 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Visual Transformers: Patch-level Interpretability for Image Classification
Feb 24, 2025



Visual transformers have achieved remarkable performance in image classification tasks, but this performance gain has come at the cost of interpretability. One of the main obstacles to the interpretation of transformers is the self-attention mechanism, which mixes visual information across the whole image in a complex way. In this paper, we propose Hindered Transformer (HiT), a novel interpretable by design architecture inspired by visual transformers. Our proposed architecture rethinks the design of transformers to better disentangle patch influences at the classification stage. Ultimately, HiT can be interpreted as a linear combination of patch-level information. We show that the advantages of our approach in terms of explicability come with a reasonable trade-off in performance, making it an attractive alternative for applications where interpretability is paramount.
Text-to-Image Models for Counterfactual Explanations: a Black-Box Approach
Sep 14, 2023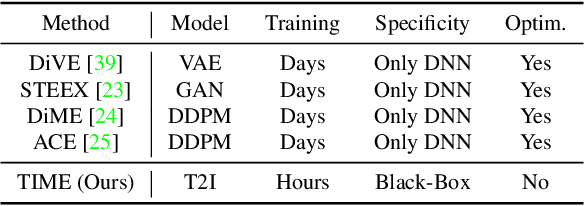

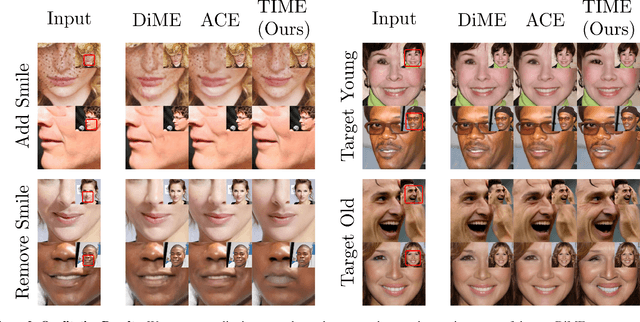
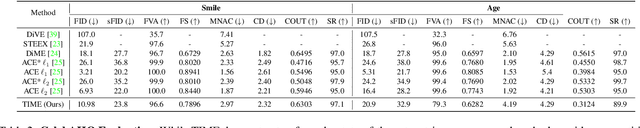
This paper addresses the challenge of generating Counterfactual Explanations (CEs), involving the identification and modification of the fewest necessary features to alter a classifier's prediction for a given image. Our proposed method, Text-to-Image Models for Counterfactual Explanations (TIME), is a black-box counterfactual technique based on distillation. Unlike previous methods, this approach requires solely the image and its prediction, omitting the need for the classifier's structure, parameters, or gradients. Before generating the counterfactuals, TIME introduces two distinct biases into Stable Diffusion in the form of textual embeddings: the context bias, associated with the image's structure, and the class bias, linked to class-specific features learned by the target classifier. After learning these biases, we find the optimal latent code applying the classifier's predicted class token and regenerate the image using the target embedding as conditioning, producing the counterfactual explanation. Extensive empirical studies validate that TIME can generate explanations of comparable effectiveness even when operating within a black-box setting.
Adversarial Counterfactual Visual Explanations
Mar 17, 2023



Counterfactual explanations and adversarial attacks have a related goal: flipping output labels with minimal perturbations regardless of their characteristics. Yet, adversarial attacks cannot be used directly in a counterfactual explanation perspective, as such perturbations are perceived as noise and not as actionable and understandable image modifications. Building on the robust learning literature, this paper proposes an elegant method to turn adversarial attacks into semantically meaningful perturbations, without modifying the classifiers to explain. The proposed approach hypothesizes that Denoising Diffusion Probabilistic Models are excellent regularizers for avoiding high-frequency and out-of-distribution perturbations when generating adversarial attacks. The paper's key idea is to build attacks through a diffusion model to polish them. This allows studying the target model regardless of its robustification level. Extensive experimentation shows the advantages of our counterfactual explanation approach over current State-of-the-Art in multiple testbeds.
Diffusion Models for Counterfactual Explanations
Mar 29, 2022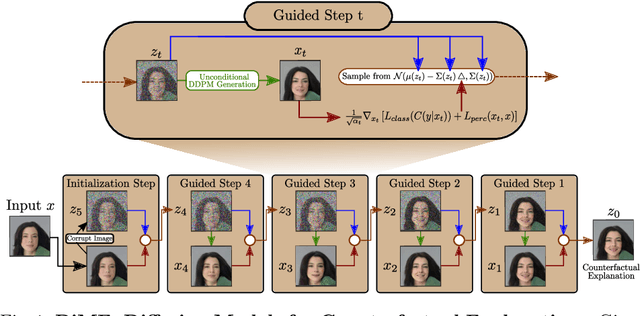
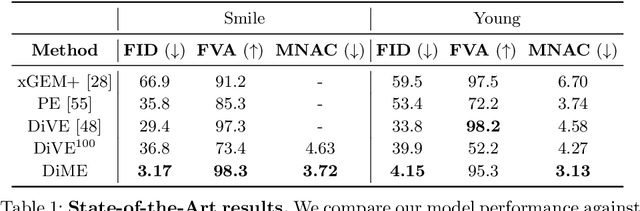


Counterfactual explanations have shown promising results as a post-hoc framework to make image classifiers more explainable. In this paper, we propose DiME, a method allowing the generation of counterfactual images using the recent diffusion models. By leveraging the guided generative diffusion process, our proposed methodology shows how to use the gradients of the target classifier to generate counterfactual explanations of input instances. Further, we analyze current approaches to evaluate spurious correlations and extend the evaluation measurements by proposing a new metric: Correlation Difference. Our experimental validations show that the proposed algorithm surpasses previous State-of-the-Art results on 5 out of 6 metrics on CelebA.
On the inductive biases of deep domain adaptation
Sep 16, 2021

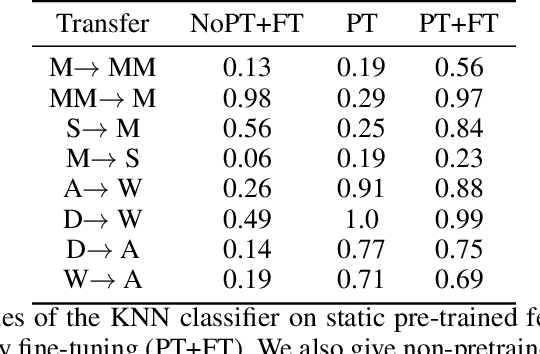

Domain alignment is currently the most prevalent solution to unsupervised domain-adaptation tasks and are often being presented as minimizers of some theoretical upper-bounds on risk in the target domain. However, further works revealed severe inadequacies between theory and practice: we consolidate this analysis and confirm that imposing domain invariance on features is neither necessary nor sufficient to obtain low target risk. We instead argue that successful deep domain adaptation rely largely on hidden inductive biases found in the common practice, such as model pre-training or design of encoder architecture. We perform various ablation experiments on popular benchmarks and our own synthetic transfers to illustrate their role in prototypical situations. To conclude our analysis, we propose to meta-learn parametric inductive biases to solve specific transfers and show their superior performance over handcrafted heuristics.
n-MeRCI: A new Metric to Evaluate the Correlation Between Predictive Uncertainty and True Error
Aug 20, 2019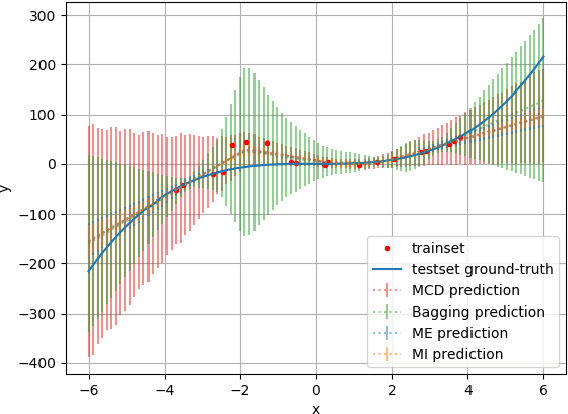


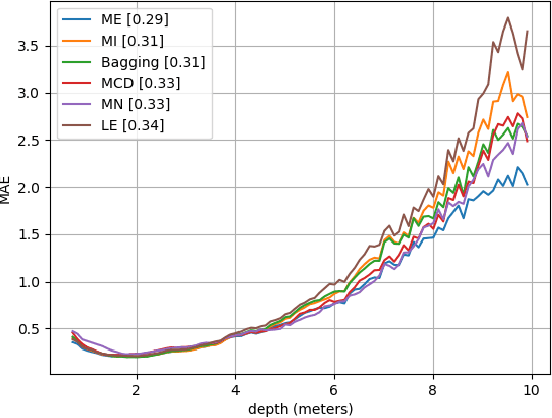
As deep learning applications are becoming more and more pervasive in robotics, the question of evaluating the reliability of inferences becomes a central question in the robotics community. This domain, known as predictive uncertainty, has come under the scrutiny of research groups developing Bayesian approaches adapted to deep learning such as Monte Carlo Dropout. Unfortunately, for the time being, the real goal of predictive uncertainty has been swept under the rug. Indeed, these approaches are solely evaluated in terms of raw performance of the network prediction, while the quality of their estimated uncertainty is not assessed. Evaluating such uncertainty prediction quality is especially important in robotics, as actions shall depend on the confidence in perceived information. In this context, the main contribution of this article is to propose a novel metric that is adapted to the evaluation of relative uncertainty assessment and directly applicable to regression with deep neural networks. To experimentally validate this metric, we evaluate it on a toy dataset and then apply it to the task of monocular depth estimation.
Revisiting Precision and Recall Definition for Generative Model Evaluation
May 14, 2019

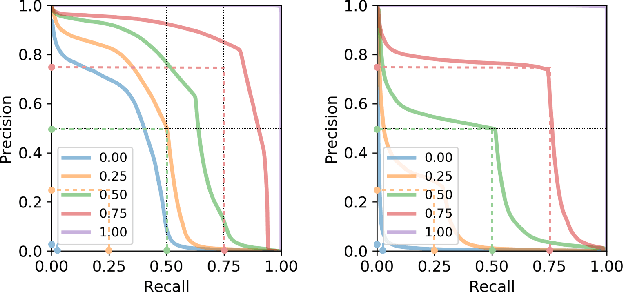

In this article we revisit the definition of Precision-Recall (PR) curves for generative models proposed by Sajjadi et al. (arXiv:1806.00035). Rather than providing a scalar for generative quality, PR curves distinguish mode-collapse (poor recall) and bad quality (poor precision). We first generalize their formulation to arbitrary measures, hence removing any restriction to finite support. We also expose a bridge between PR curves and type I and type II error rates of likelihood ratio classifiers on the task of discriminating between samples of the two distributions. Building upon this new perspective, we propose a novel algorithm to approximate precision-recall curves, that shares some interesting methodological properties with the hypothesis testing technique from Lopez-Paz et al (arXiv:1610.06545). We demonstrate the interest of the proposed formulation over the original approach on controlled multi-modal datasets.
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks
Feb 08, 2017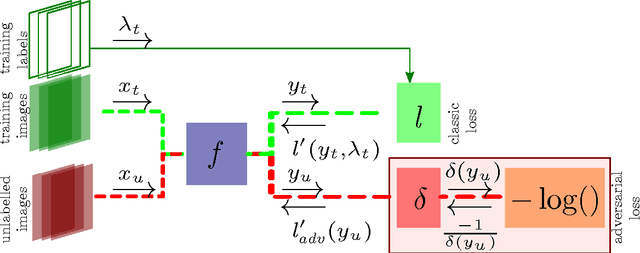

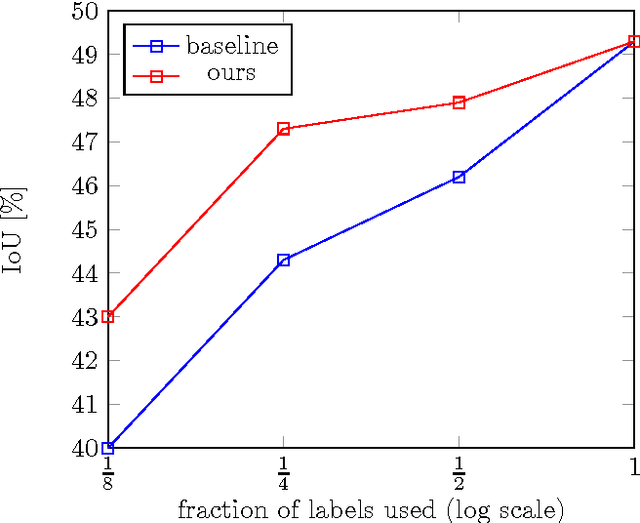
We propose a method for semi-supervised training of structured-output neural networks. Inspired by the framework of Generative Adversarial Networks (GAN), we train a discriminator network to capture the notion of a quality of network output. To this end, we leverage the qualitative difference between outputs obtained on the labelled training data and unannotated data. We then use the discriminator as a source of error signal for unlabelled data. This effectively boosts the performance of a network on a held out test set. Initial experiments in image segmentation demonstrate that the proposed framework enables achieving the same network performance as in a fully supervised scenario, while using two times less annotations.