 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the inductive biases of deep domain adaptation
Sep 16, 2021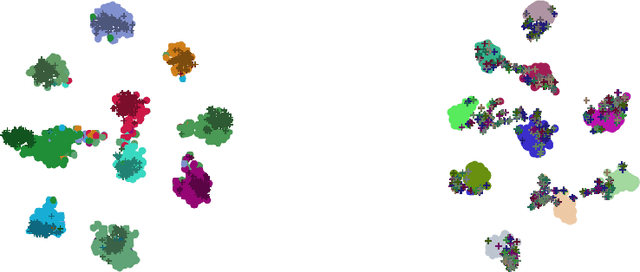

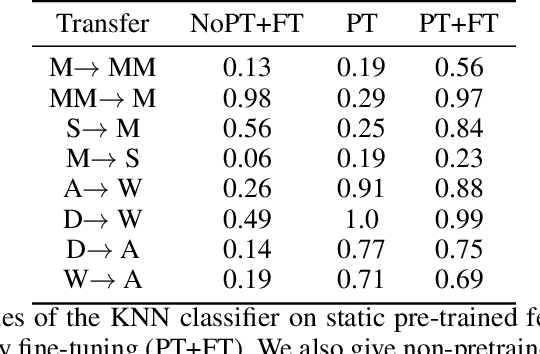

Domain alignment is currently the most prevalent solution to unsupervised domain-adaptation tasks and are often being presented as minimizers of some theoretical upper-bounds on risk in the target domain. However, further works revealed severe inadequacies between theory and practice: we consolidate this analysis and confirm that imposing domain invariance on features is neither necessary nor sufficient to obtain low target risk. We instead argue that successful deep domain adaptation rely largely on hidden inductive biases found in the common practice, such as model pre-training or design of encoder architecture. We perform various ablation experiments on popular benchmarks and our own synthetic transfers to illustrate their role in prototypical situations. To conclude our analysis, we propose to meta-learn parametric inductive biases to solve specific transfers and show their superior performance over handcrafted heuristics.