 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Meta-Learned Neuron model for Continual Learning
Nov 03, 2021
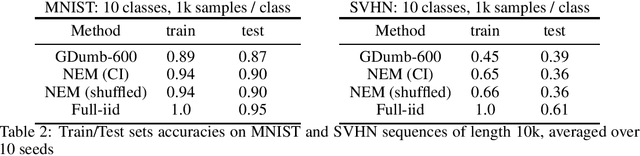
Continual learning is the ability to acquire new knowledge without forgetting the previously learned one, assuming no further access to past training data. Neural network approximators trained with gradient descent are known to fail in this setting as they must learn from a stream of data-points sampled from a stationary distribution to converge. In this work, we replace the standard neuron by a meta-learned neuron model whom inference and update rules are optimized to minimize catastrophic interference. Our approach can memorize dataset-length sequences of training samples, and its learning capabilities generalize to any domain. Unlike previous continual learning methods, our method does not make any assumption about how tasks are constructed, delivered and how they relate to each other: it simply absorbs and retains training samples one by one, whether the stream of input data is time-correlated or not.
On the inductive biases of deep domain adaptation
Sep 16, 2021

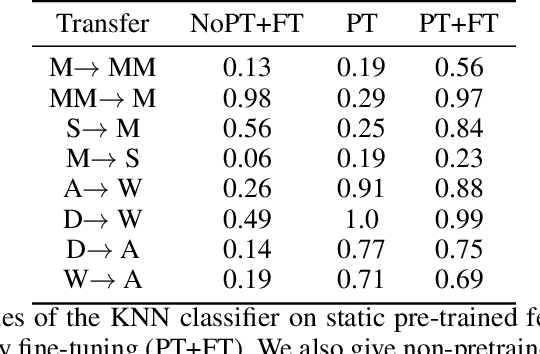

Domain alignment is currently the most prevalent solution to unsupervised domain-adaptation tasks and are often being presented as minimizers of some theoretical upper-bounds on risk in the target domain. However, further works revealed severe inadequacies between theory and practice: we consolidate this analysis and confirm that imposing domain invariance on features is neither necessary nor sufficient to obtain low target risk. We instead argue that successful deep domain adaptation rely largely on hidden inductive biases found in the common practice, such as model pre-training or design of encoder architecture. We perform various ablation experiments on popular benchmarks and our own synthetic transfers to illustrate their role in prototypical situations. To conclude our analysis, we propose to meta-learn parametric inductive biases to solve specific transfers and show their superior performance over handcrafted heuristics.