 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Meta-Learned Neuron model for Continual Learning
Paper and Code
Nov 03, 2021
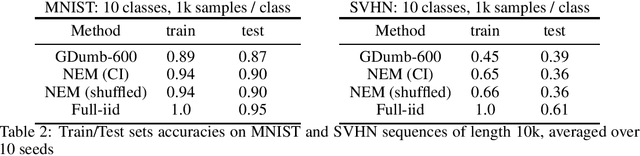
Continual learning is the ability to acquire new knowledge without forgetting the previously learned one, assuming no further access to past training data. Neural network approximators trained with gradient descent are known to fail in this setting as they must learn from a stream of data-points sampled from a stationary distribution to converge. In this work, we replace the standard neuron by a meta-learned neuron model whom inference and update rules are optimized to minimize catastrophic interference. Our approach can memorize dataset-length sequences of training samples, and its learning capabilities generalize to any domain. Unlike previous continual learning methods, our method does not make any assumption about how tasks are constructed, delivered and how they relate to each other: it simply absorbs and retains training samples one by one, whether the stream of input data is time-correlated or not.