 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjusting the Ground Truth Annotations for Connectivity-Based Learning to Delineate
Dec 06, 2021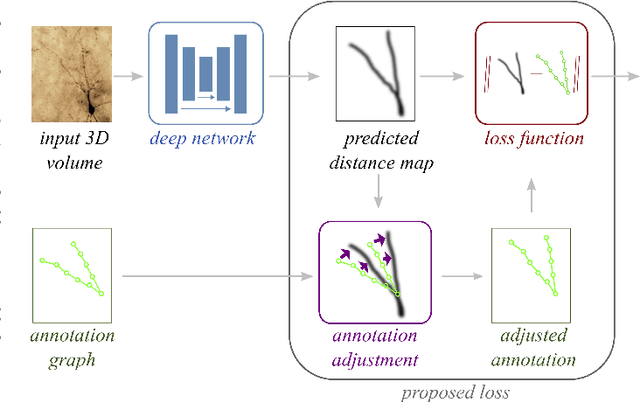
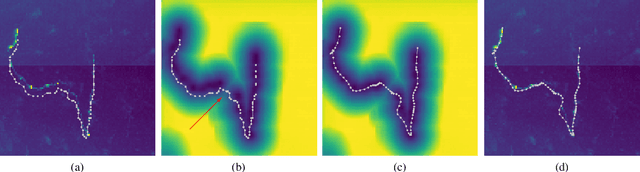
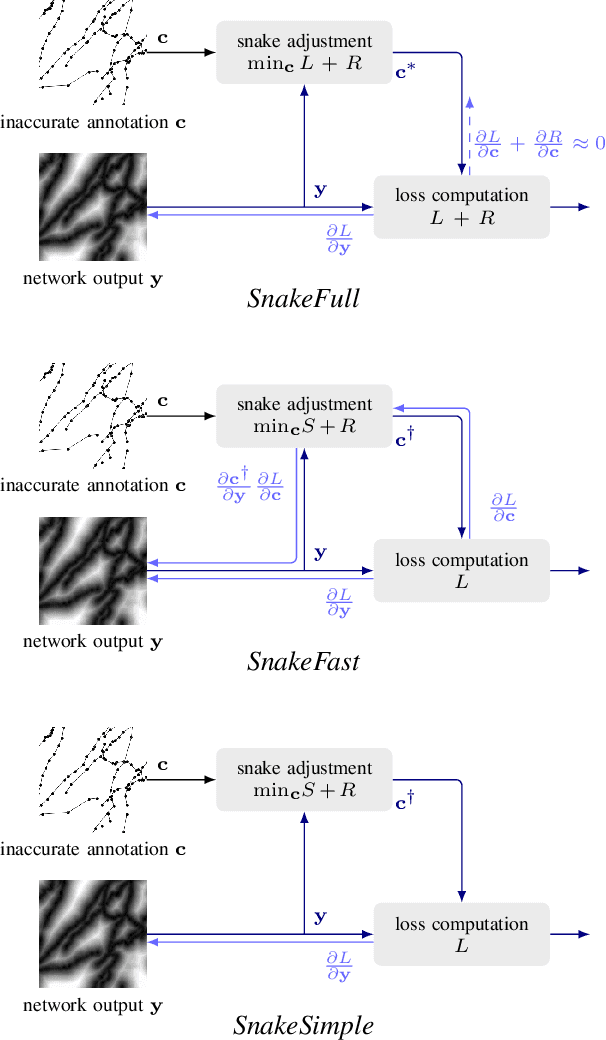

Deep learning-based approaches to delineating 3D structure depend on accurate annotations to train the networks. Yet, in practice, people, no matter how conscientious, have trouble precisely delineating in 3D and on a large scale, in part because the data is often hard to interpret visually and in part because the 3D interfaces are awkward to use. In this paper, we introduce a method that explicitly accounts for annotation inaccuracies. To this end, we treat the annotations as active contour models that can deform themselves while preserving their topology. This enables us to jointly train the network and correct potential errors in the original annotations. The result is an approach that boosts performance of deep networks trained with potentially inaccurate annotations.
Localized Persistent Homologies for more Effective Deep Learning
Oct 12, 2021
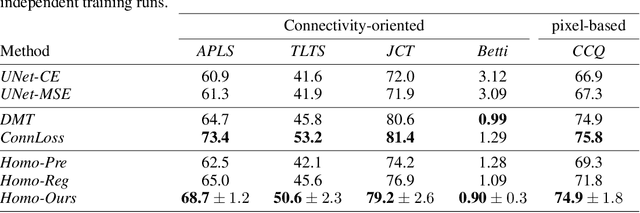

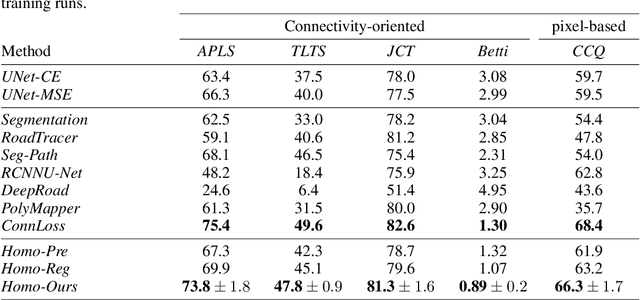
Persistent Homologies have been successfully used to increase the performance of deep networks trained to detect curvilinear structures and to improve the topological quality of the results. However, existing methods are very global and ignore the location of topological features. In this paper, we introduce an approach that relies on a new filtration function to account for location during network training. We demonstrate experimentally on 2D images of roads and 3D image stacks of neuronal processes that networks trained in this manner are better at recovering the topology of the curvilinear structures they extract.
Promoting Connectivity of Network-Like Structures by Enforcing Region Separation
Sep 15, 2020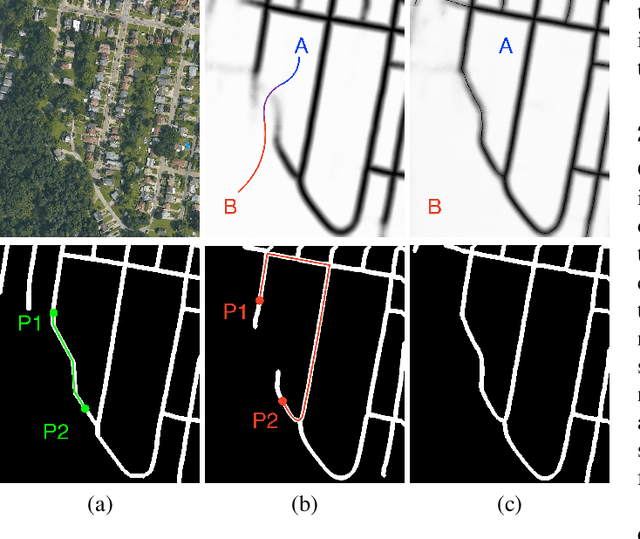
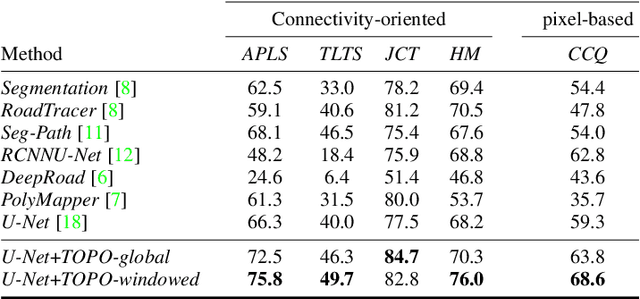
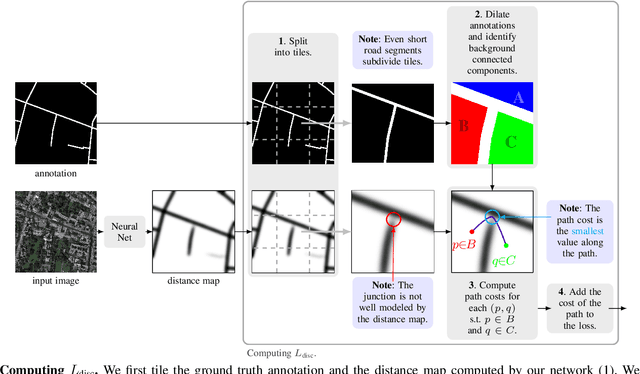
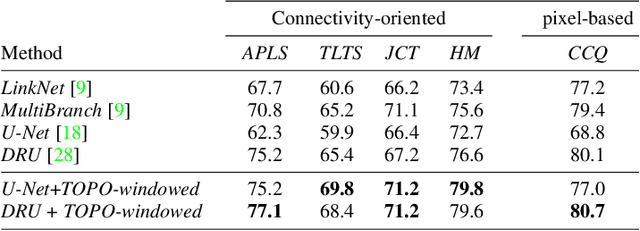
We propose a novel, connectivity-oriented loss function for training deep convolutional networks to reconstruct network-like structures, like roads and irrigation canals, from aerial images. The main idea behind our loss is to express the connectivity of roads, or canals, in terms of disconnections that they create between background regions of the image. In simple terms, a gap in the predicted road causes two background regions, that lie on the opposite sides of a ground truth road, to touch in prediction. Our loss function is designed to prevent such unwanted connections between background regions, and therefore close the gaps in predicted roads. It also prevents predicting false positive roads and canals by penalizing unwarranted disconnections of background regions. In order to capture even short, dead-ending road segments, we evaluate the loss in small image crops. We show, in experiments on two standard road benchmarks and a new data set of irrigation canals, that convnets trained with our loss function recover road connectivity so well, that it suffices to skeletonize their output to produce state of the art maps. A distinct advantage of our approach is that the loss can be plugged in to any existing training setup without further modifications.
Towards Reliable Evaluation of Road Network Reconstructions
Nov 28, 2019



Existing performance measures rank delineation algorithms inconsistently, which makes it difficult to decide which one is best in any given situation. We show that these inconsistencies stem from design flaws that make the metrics insensitive to whole classes of errors. To provide more reliable evaluation, we design three new metrics that are far more consistent even though they use very different approaches to comparing ground-truth and reconstructed road networks. We use both synthetic and real data to demonstrate this and advocate the use of these corrected metrics as a tool to gauge future progress.
Tracing in 2D to Reduce the Annotation Effort for 3D Deep Delineation
Nov 26, 2018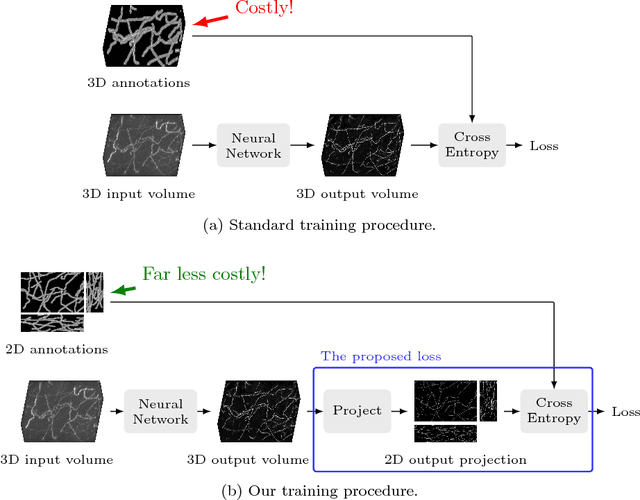
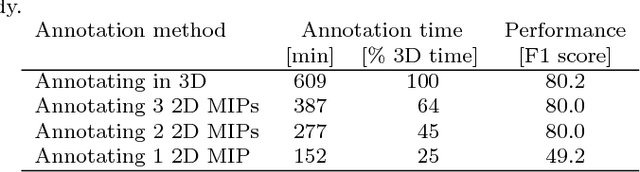

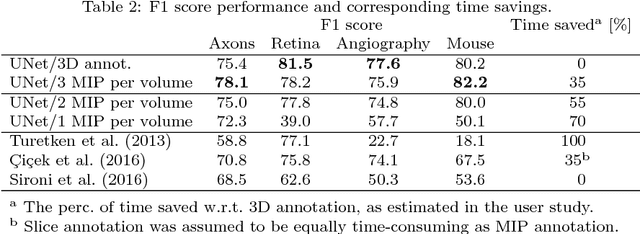
The difficulty of obtaining annotations to build training databases still slows down the adoption of recent deep learning approaches for biomedical image analysis. In this paper, we show that we can train a Deep Net to perform 3D volumetric delineation given only 2D annotations in Maximum Intensity Projections (MIP). As a consequence, we can decrease the amount of time spent annotating by a factor of two while maintaining similar performance. Our approach is inspired by space carving, a classical technique of reconstructing complex 3D shapes from arbitrarily-positioned cameras. We will demonstrate its effectiveness on 3D light microscopy images of neurons and retinal blood vessels and on Magnetic Resonance Angiography (MRA) brain scans.
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks
Feb 08, 2017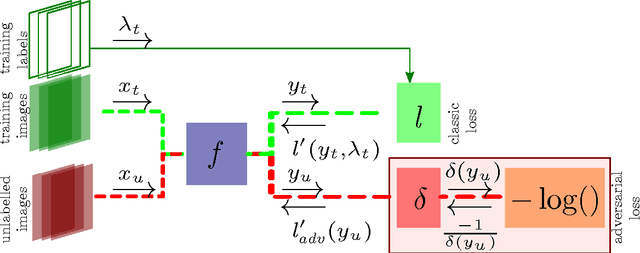

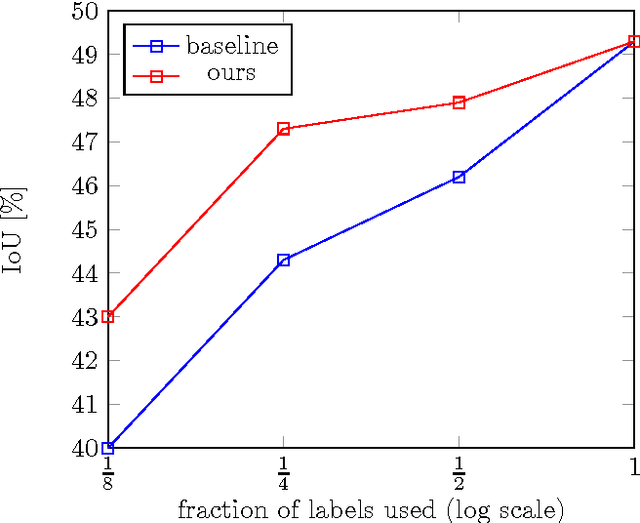
We propose a method for semi-supervised training of structured-output neural networks. Inspired by the framework of Generative Adversarial Networks (GAN), we train a discriminator network to capture the notion of a quality of network output. To this end, we leverage the qualitative difference between outputs obtained on the labelled training data and unannotated data. We then use the discriminator as a source of error signal for unlabelled data. This effectively boosts the performance of a network on a held out test set. Initial experiments in image segmentation demonstrate that the proposed framework enables achieving the same network performance as in a fully supervised scenario, while using two times less annotations.