 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion
Mar 18, 2026Diffusion-based image-to-video (I2V) models are increasingly effective, yet they struggle to scale to ultra-high-resolution inputs (e.g., 4K). Generating videos at the model's native resolution often loses fine-grained structure, whereas high-resolution tiled denoising preserves local detail but breaks global layout consistency. This failure mode is particularly severe in the fresco animation setting: monumental artworks containing many distinct characters, objects, and semantically different sub-scenes that must remain spatially coherent over time. We introduce FrescoDiffusion, a training-free method for coherent large-format I2V generation from a single complex image. The key idea is to augment tiled denoising with a precomputed latent prior: we first generate a low-resolution video at the underlying model resolution and upsample its latent trajectory to obtain a global reference that captures long-range temporal and spatial structure. For 4K generation, we compute per-tile noise predictions and fuse them with this reference at every diffusion timestep by minimizing a single weighted least-squares objective in model-output space. The objective combines a standard tile-merging criterion with our regularization term, yielding a closed-form fusion update that strengthens global coherence while retaining fine detail. We additionally provide a spatial regularization variable that enables region-level control over where motion is allowed. Experiments on the VBench-I2V dataset and our proposed fresco I2V dataset show improved global consistency and fidelity over tiled baselines, while being computationally efficient. Our regularization enables explicit controllability of the trade-off between creativity and consistency.
Disentangling Visual Transformers: Patch-level Interpretability for Image Classification
Feb 24, 2025



Visual transformers have achieved remarkable performance in image classification tasks, but this performance gain has come at the cost of interpretability. One of the main obstacles to the interpretation of transformers is the self-attention mechanism, which mixes visual information across the whole image in a complex way. In this paper, we propose Hindered Transformer (HiT), a novel interpretable by design architecture inspired by visual transformers. Our proposed architecture rethinks the design of transformers to better disentangle patch influences at the classification stage. Ultimately, HiT can be interpreted as a linear combination of patch-level information. We show that the advantages of our approach in terms of explicability come with a reasonable trade-off in performance, making it an attractive alternative for applications where interpretability is paramount.
Text-to-Image Models for Counterfactual Explanations: a Black-Box Approach
Sep 14, 2023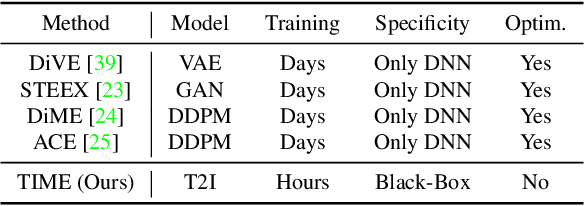

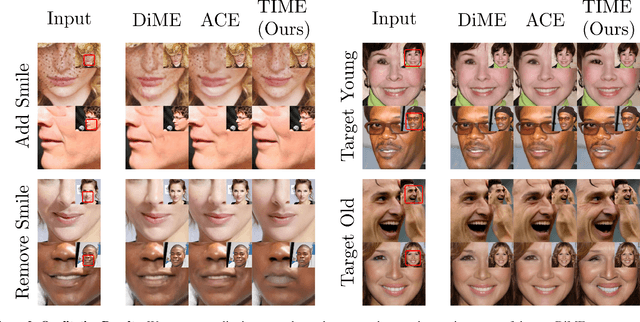
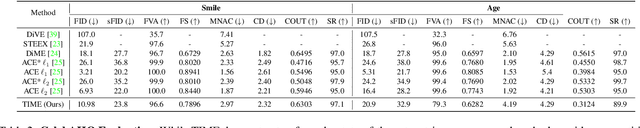
This paper addresses the challenge of generating Counterfactual Explanations (CEs), involving the identification and modification of the fewest necessary features to alter a classifier's prediction for a given image. Our proposed method, Text-to-Image Models for Counterfactual Explanations (TIME), is a black-box counterfactual technique based on distillation. Unlike previous methods, this approach requires solely the image and its prediction, omitting the need for the classifier's structure, parameters, or gradients. Before generating the counterfactuals, TIME introduces two distinct biases into Stable Diffusion in the form of textual embeddings: the context bias, associated with the image's structure, and the class bias, linked to class-specific features learned by the target classifier. After learning these biases, we find the optimal latent code applying the classifier's predicted class token and regenerate the image using the target embedding as conditioning, producing the counterfactual explanation. Extensive empirical studies validate that TIME can generate explanations of comparable effectiveness even when operating within a black-box setting.
BoDiffusion: Diffusing Sparse Observations for Full-Body Human Motion Synthesis
Apr 21, 2023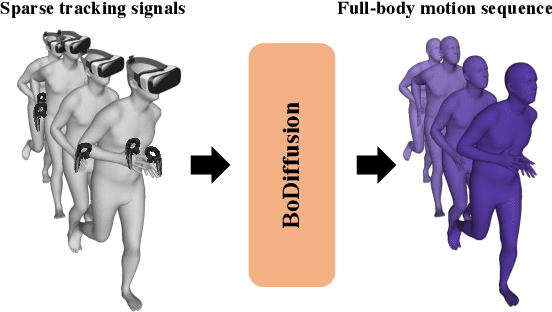

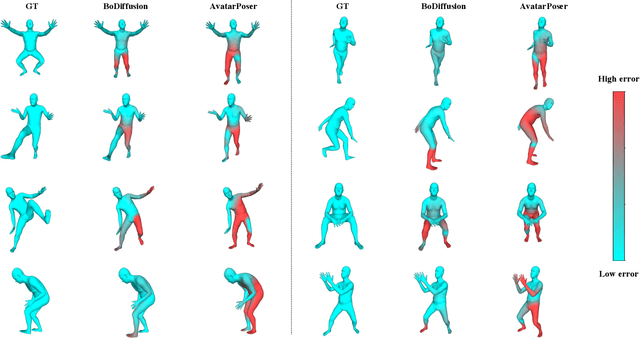
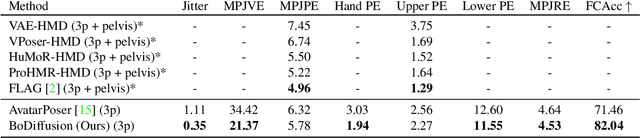
Mixed reality applications require tracking the user's full-body motion to enable an immersive experience. However, typical head-mounted devices can only track head and hand movements, leading to a limited reconstruction of full-body motion due to variability in lower body configurations. We propose BoDiffusion -- a generative diffusion model for motion synthesis to tackle this under-constrained reconstruction problem. We present a time and space conditioning scheme that allows BoDiffusion to leverage sparse tracking inputs while generating smooth and realistic full-body motion sequences. To the best of our knowledge, this is the first approach that uses the reverse diffusion process to model full-body tracking as a conditional sequence generation task. We conduct experiments on the large-scale motion-capture dataset AMASS and show that our approach outperforms the state-of-the-art approaches by a significant margin in terms of full-body motion realism and joint reconstruction error.
Adversarial Counterfactual Visual Explanations
Mar 17, 2023



Counterfactual explanations and adversarial attacks have a related goal: flipping output labels with minimal perturbations regardless of their characteristics. Yet, adversarial attacks cannot be used directly in a counterfactual explanation perspective, as such perturbations are perceived as noise and not as actionable and understandable image modifications. Building on the robust learning literature, this paper proposes an elegant method to turn adversarial attacks into semantically meaningful perturbations, without modifying the classifiers to explain. The proposed approach hypothesizes that Denoising Diffusion Probabilistic Models are excellent regularizers for avoiding high-frequency and out-of-distribution perturbations when generating adversarial attacks. The paper's key idea is to build attacks through a diffusion model to polish them. This allows studying the target model regardless of its robustification level. Extensive experimentation shows the advantages of our counterfactual explanation approach over current State-of-the-Art in multiple testbeds.
Diffusion Models for Counterfactual Explanations
Mar 29, 2022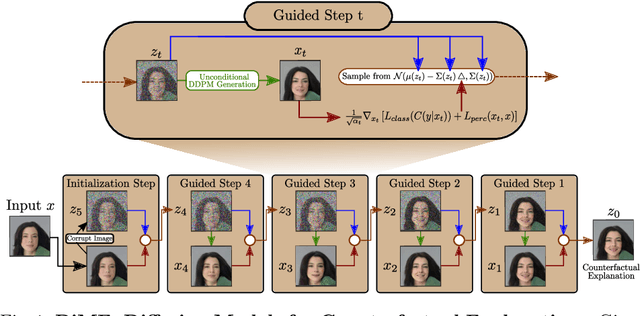
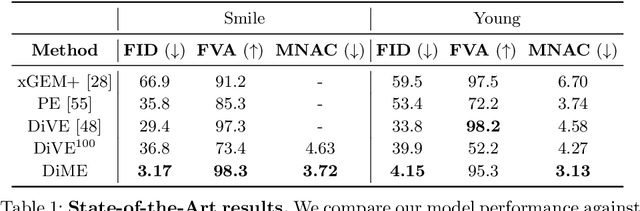


Counterfactual explanations have shown promising results as a post-hoc framework to make image classifiers more explainable. In this paper, we propose DiME, a method allowing the generation of counterfactual images using the recent diffusion models. By leveraging the guided generative diffusion process, our proposed methodology shows how to use the gradients of the target classifier to generate counterfactual explanations of input instances. Further, we analyze current approaches to evaluate spurious correlations and extend the evaluation measurements by proposing a new metric: Correlation Difference. Our experimental validations show that the proposed algorithm surpasses previous State-of-the-Art results on 5 out of 6 metrics on CelebA.
A Hierarchical Assessment of Adversarial Severity
Aug 26, 2021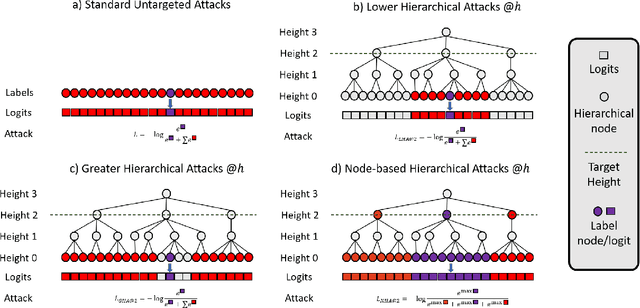


Adversarial Robustness is a growing field that evidences the brittleness of neural networks. Although the literature on adversarial robustness is vast, a dimension is missing in these studies: assessing how severe the mistakes are. We call this notion "Adversarial Severity" since it quantifies the downstream impact of adversarial corruptions by computing the semantic error between the misclassification and the proper label. We propose to study the effects of adversarial noise by measuring the Robustness and Severity into a large-scale dataset: iNaturalist-H. Our contributions are: (i) we introduce novel Hierarchical Attacks that harness the rich structured space of labels to create adversarial examples. (ii) These attacks allow us to benchmark the Adversarial Robustness and Severity of classification models. (iii) We enhance the traditional adversarial training with a simple yet effective Hierarchical Curriculum Training to learn these nodes gradually within the hierarchical tree. We perform extensive experiments showing that hierarchical defenses allow deep models to boost the adversarial Robustness by 1.85% and reduce the severity of all attacks by 0.17, on average.
Enhancing Adversarial Robustness via Test-time Transformation Ensembling
Jul 29, 2021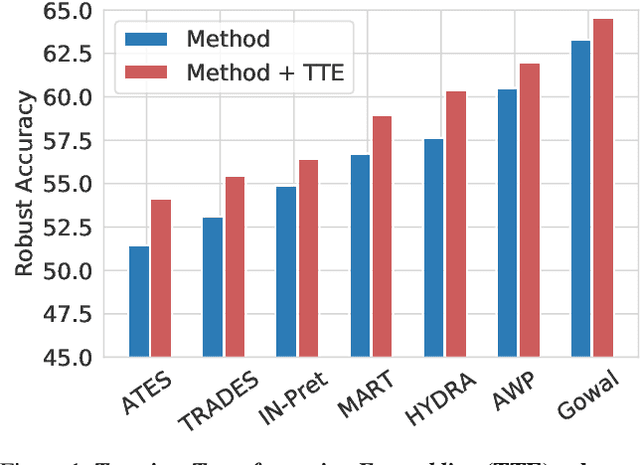
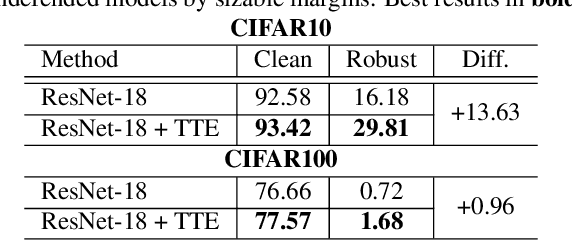
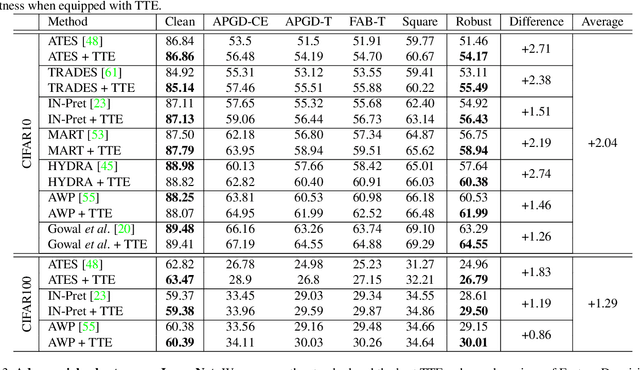
Deep learning models are prone to being fooled by imperceptible perturbations known as adversarial attacks. In this work, we study how equipping models with Test-time Transformation Ensembling (TTE) can work as a reliable defense against such attacks. While transforming the input data, both at train and test times, is known to enhance model performance, its effects on adversarial robustness have not been studied. Here, we present a comprehensive empirical study of the impact of TTE, in the form of widely-used image transforms, on adversarial robustness. We show that TTE consistently improves model robustness against a variety of powerful attacks without any need for re-training, and that this improvement comes at virtually no trade-off with accuracy on clean samples. Finally, we show that the benefits of TTE transfer even to the certified robustness domain, in which TTE provides sizable and consistent improvements.
Robust Gabor Networks
Dec 11, 2019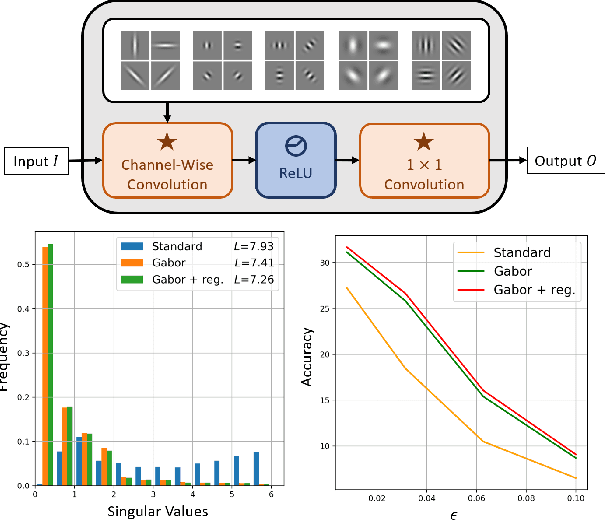
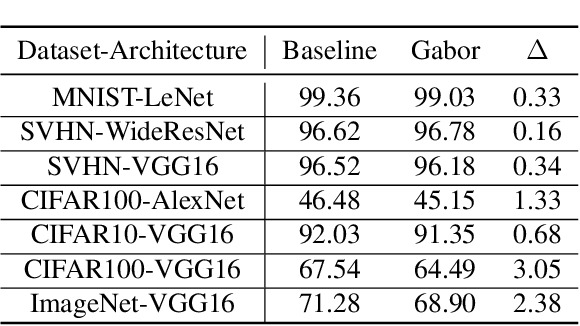
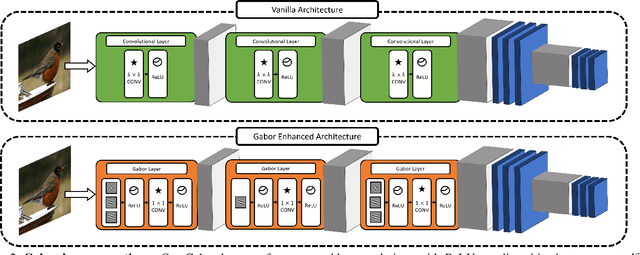
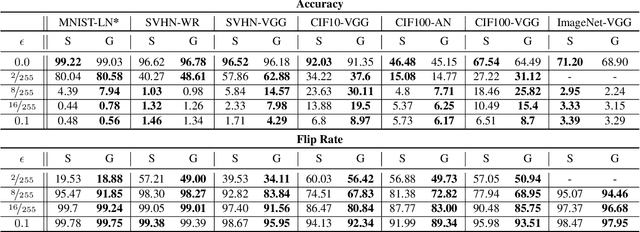
This work takes a step towards investigating the benefits of merging classical vision techniques with deep learning models. Formally, we explore the effect of replacing the first layers of neural network architectures with convolutional layers that are based on Gabor filters with learnable parameters. As a first result, we observe that architectures utilizing Gabor filters as low-level kernels are capable of preserving test set accuracy of deep convolutional networks. Therefore, this architectural change exalts their capabilities in extracting useful low-level features. Furthermore, we observe that the architectures enhanced with Gabor layers gain advantages in terms of robustness when compared to the regular models. Additionally, the existence of a closed mathematical expression for the Gabor kernels allows us to develop an analytical expression for an upper bound to the Lipschitz constant of the Gabor layer. This expression allows us to propose a simple regularizer to enhance the robustness of the network. We conduct extensive experiments with several architectures and datasets, and show the beneficial effects that the introduction of Gabor layers has on the robustness of deep convolutional networks.
MAIN: Multi-Attention Instance Network for Video Segmentation
Apr 11, 2019



Instance-level video segmentation requires a solid integration of spatial and temporal information. However, current methods rely mostly on domain-specific information (online learning) to produce accurate instance-level segmentations. We propose a novel approach that relies exclusively on the integration of generic spatio-temporal attention cues. Our strategy, named Multi-Attention Instance Network (MAIN), overcomes challenging segmentation scenarios over arbitrary videos without modelling sequence- or instance-specific knowledge. We design MAIN to segment multiple instances in a single forward pass, and optimize it with a novel loss function that favors class agnostic predictions and assigns instance-specific penalties. We achieve state-of-the-art performance on the challenging Youtube-VOS dataset and benchmark, improving the unseen Jaccard and F-Metric by 6.8% and 12.7% respectively, while operating at real-time (30.3 FPS).