 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitch: Training-Free Position Control in Multimodal Diffusion Transformers
Sep 30, 2025Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at https://github.com/ExplainableML/Stitch.
Localized Vision-Language Matching for Open-vocabulary Object Detection
May 12, 2022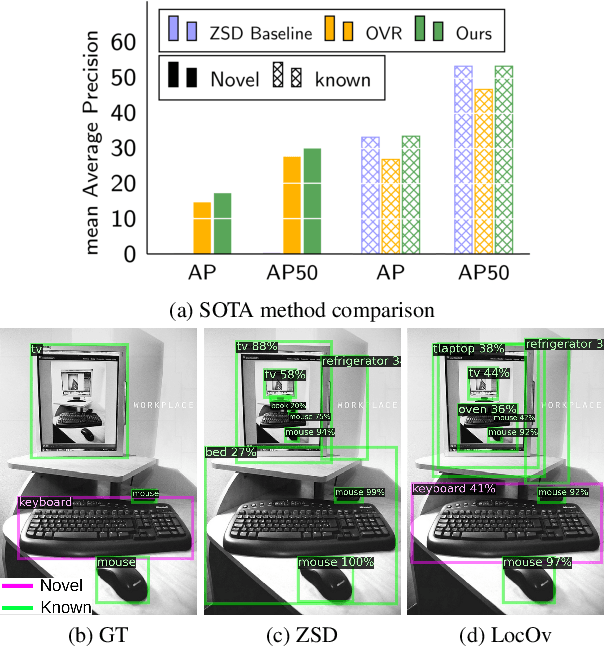
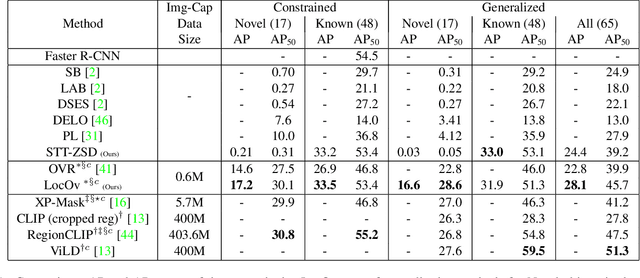
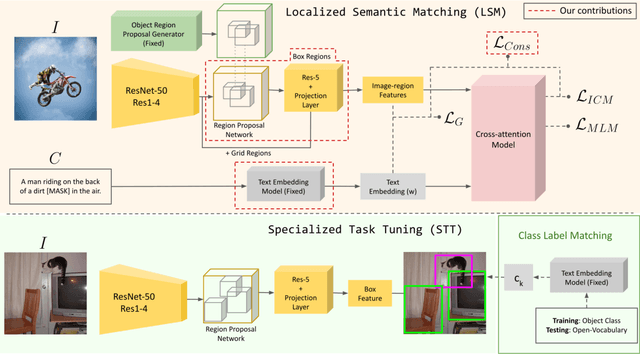
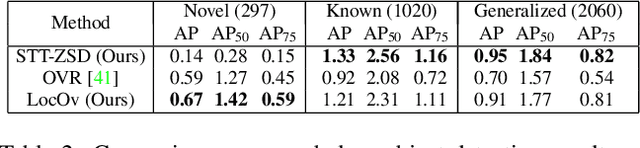
In this work, we propose an open-world object detection method that, based on image-caption pairs, learns to detect novel object classes along with a given set of known classes. It is a two-stage training approach that first uses a location-guided image-caption matching technique to learn class labels for both novel and known classes in a weakly-supervised manner and second specializes the model for the object detection task using known class annotations. We show that a simple language model fits better than a large contextualized language model for detecting novel objects. Moreover, we introduce a consistency-regularization technique to better exploit image-caption pair information. Our method compares favorably to existing open-world detection approaches while being data-efficient.
MAIN: Multi-Attention Instance Network for Video Segmentation
Apr 11, 2019



Instance-level video segmentation requires a solid integration of spatial and temporal information. However, current methods rely mostly on domain-specific information (online learning) to produce accurate instance-level segmentations. We propose a novel approach that relies exclusively on the integration of generic spatio-temporal attention cues. Our strategy, named Multi-Attention Instance Network (MAIN), overcomes challenging segmentation scenarios over arbitrary videos without modelling sequence- or instance-specific knowledge. We design MAIN to segment multiple instances in a single forward pass, and optimize it with a novel loss function that favors class agnostic predictions and assigns instance-specific penalties. We achieve state-of-the-art performance on the challenging Youtube-VOS dataset and benchmark, improving the unseen Jaccard and F-Metric by 6.8% and 12.7% respectively, while operating at real-time (30.3 FPS).