 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Geometric Understanding and Learned Data Priors in VGGT
Dec 12, 2025The Visual Geometry Grounded Transformer (VGGT) is a 3D foundation model that infers camera geometry and scene structure in a single feed-forward pass. Trained in a supervised, single-step fashion on large datasets, VGGT raises a key question: does it build upon geometric concepts like traditional multi-view methods, or does it rely primarily on learned appearance-based data-driven priors? In this work, we conduct a systematic analysis of VGGT's internal mechanisms to uncover whether geometric understanding emerges within its representations. By probing intermediate features, analyzing attention patterns, and performing interventions, we examine how the model implements its functionality. Our findings reveal that VGGT implicitly performs correspondence matching within its global attention layers and encodes epipolar geometry, despite being trained without explicit geometric constraints. We further investigate VGGT's dependence on its learned data priors. Using spatial input masking and perturbation experiments, we assess its robustness to occlusions, appearance variations, and camera configurations, comparing it with classical multi-stage pipelines. Together, these insights highlight how VGGT internalizes geometric structure while using learned data-driven priors.
Orbis: Overcoming Challenges of Long-Horizon Prediction in Driving World Models
Jul 17, 2025Existing world models for autonomous driving struggle with long-horizon generation and generalization to challenging scenarios. In this work, we develop a model using simple design choices, and without additional supervision or sensors, such as maps, depth, or multiple cameras. We show that our model yields state-of-the-art performance, despite having only 469M parameters and being trained on 280h of video data. It particularly stands out in difficult scenarios like turning maneuvers and urban traffic. We test whether discrete token models possibly have advantages over continuous models based on flow matching. To this end, we set up a hybrid tokenizer that is compatible with both approaches and allows for a side-by-side comparison. Our study concludes in favor of the continuous autoregressive model, which is less brittle on individual design choices and more powerful than the model built on discrete tokens. Code, models and qualitative results are publicly available at https://lmb-freiburg.github.io/orbis.github.io/.
What Matters for In-Context Learning: A Balancing Act of Look-up and In-Weight Learning
Jan 09, 2025Large Language Models (LLMs) have demonstrated impressive performance in various tasks, including In-Context Learning (ICL), where the model performs new tasks by conditioning solely on the examples provided in the context, without updating the model's weights. While prior research has explored the roles of pretraining data and model architecture, the key mechanism behind ICL remains unclear. In this work, we systematically uncover properties present in LLMs that support the emergence of ICL. To disambiguate these factors, we conduct a study with a controlled dataset and data sequences using a deep autoregressive model. We show that conceptual repetitions in the data sequences are crucial for ICL, more so than previously indicated training data properties like burstiness or long-tail distribution. Conceptual repetitions could refer to $n$-gram repetitions in textual data or exact image copies in image sequence data. Such repetitions also offer other previously overlooked benefits such as reduced transiency in ICL performance. Furthermore, we show that the emergence of ICL depends on balancing the in-weight learning objective with the in-context solving ability during training.
Revisiting Deep Active Learning for Semantic Segmentation
Feb 08, 2023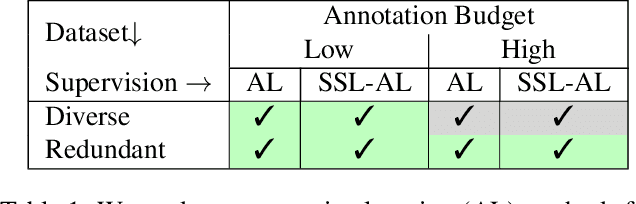
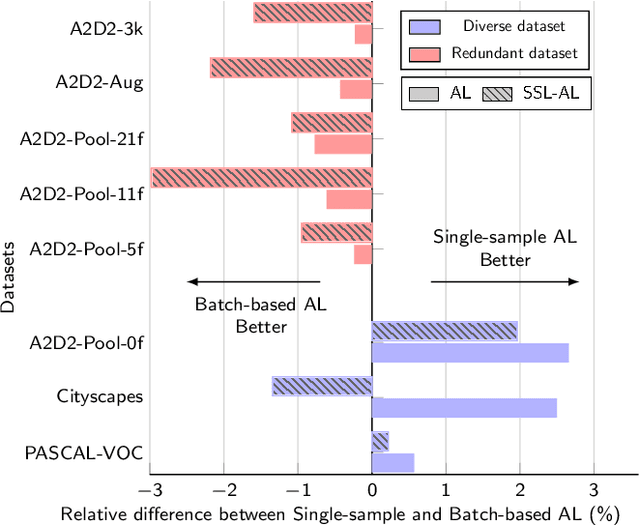


Active learning automatically selects samples for annotation from a data pool to achieve maximum performance with minimum annotation cost. This is particularly critical for semantic segmentation, where annotations are costly. In this work, we show in the context of semantic segmentation that the data distribution is decisive for the performance of the various active learning objectives proposed in the literature. Particularly, redundancy in the data, as it appears in most driving scenarios and video datasets, plays a large role. We demonstrate that the integration of semi-supervised learning with active learning can improve performance when the two objectives are aligned. Our experimental study shows that current active learning benchmarks for segmentation in driving scenarios are not realistic since they operate on data that is already curated for maximum diversity. Accordingly, we propose a more realistic evaluation scheme in which the value of active learning becomes clearly visible, both by itself and in combination with semi-supervised learning.
Open-vocabulary Attribute Detection
Nov 23, 2022Vision-language modeling has enabled open-vocabulary tasks where predictions can be queried using any text prompt in a zero-shot manner. Existing open-vocabulary tasks focus on object classes, whereas research on object attributes is limited due to the lack of a reliable attribute-focused evaluation benchmark. This paper introduces the Open-Vocabulary Attribute Detection (OVAD) task and the corresponding OVAD benchmark. The objective of the novel task and benchmark is to probe object-level attribute information learned by vision-language models. To this end, we created a clean and densely annotated test set covering 117 attribute classes on the 80 object classes of MS COCO. It includes positive and negative annotations, which enables open-vocabulary evaluation. Overall, the benchmark consists of 1.4 million annotations. For reference, we provide a first baseline method for open-vocabulary attribute detection. Moreover, we demonstrate the benchmark's value by studying the attribute detection performance of several foundation models. Project page https://ovad-benchmark.github.io/
Localized Vision-Language Matching for Open-vocabulary Object Detection
May 12, 2022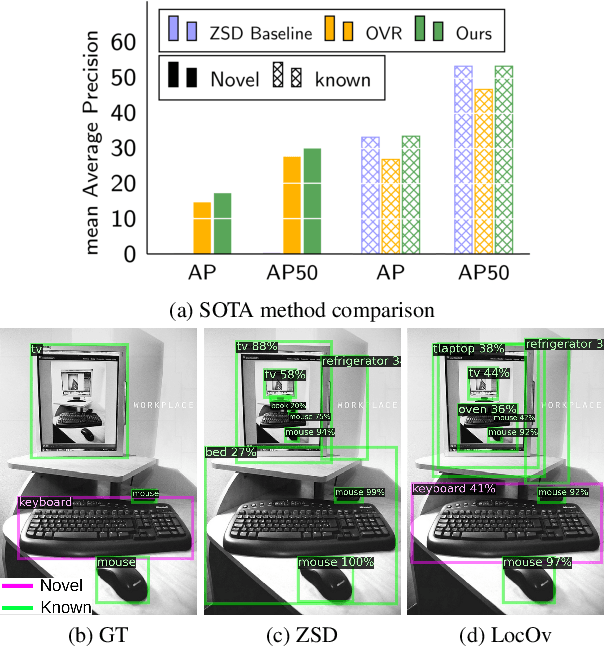
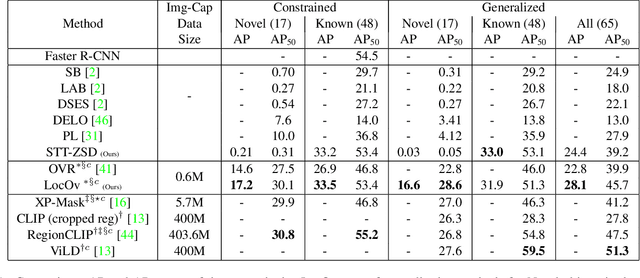
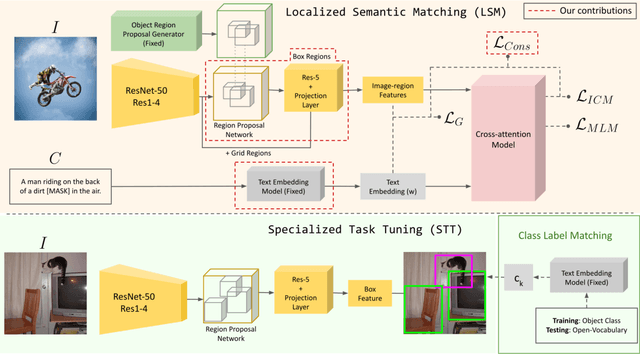
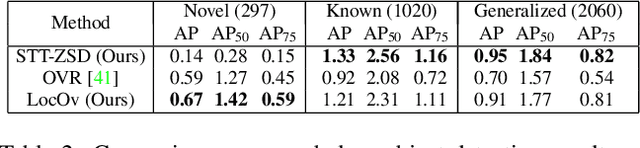
In this work, we propose an open-world object detection method that, based on image-caption pairs, learns to detect novel object classes along with a given set of known classes. It is a two-stage training approach that first uses a location-guided image-caption matching technique to learn class labels for both novel and known classes in a weakly-supervised manner and second specializes the model for the object detection task using known class annotations. We show that a simple language model fits better than a large contextualized language model for detecting novel objects. Moreover, we introduce a consistency-regularization technique to better exploit image-caption pair information. Our method compares favorably to existing open-world detection approaches while being data-efficient.
Essentials for Class Incremental Learning
Feb 18, 2021
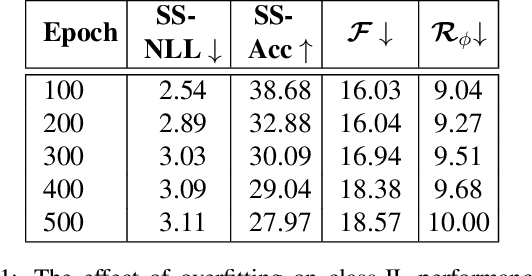
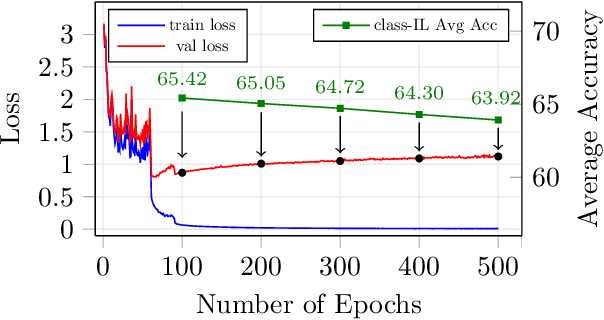

Contemporary neural networks are limited in their ability to learn from evolving streams of training data. When trained sequentially on new or evolving tasks, their accuracy drops sharply, making them unsuitable for many real-world applications. In this work, we shed light on the causes of this well-known yet unsolved phenomenon - often referred to as catastrophic forgetting - in a class-incremental setup. We show that a combination of simple components and a loss that balances intra-task and inter-task learning can already resolve forgetting to the same extent as more complex measures proposed in literature. Moreover, we identify poor quality of the learned representation as another reason for catastrophic forgetting in class-IL. We show that performance is correlated with secondary class information (dark knowledge) learned by the model and it can be improved by an appropriate regularizer. With these lessons learned, class-incremental learning results on CIFAR-100 and ImageNet improve over the state-of-the-art by a large margin, while keeping the approach simple.
Parting with Illusions about Deep Active Learning
Dec 11, 2019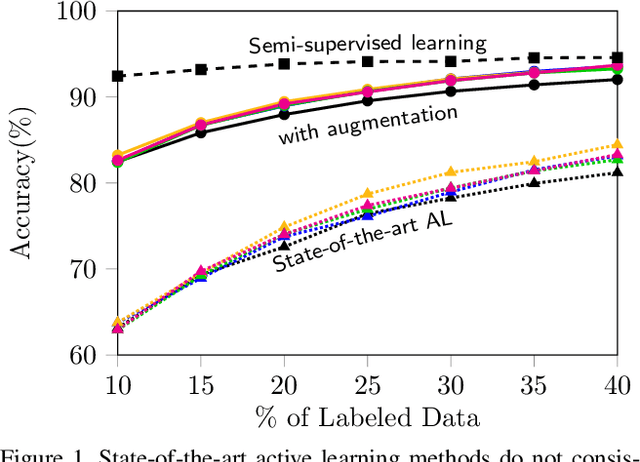
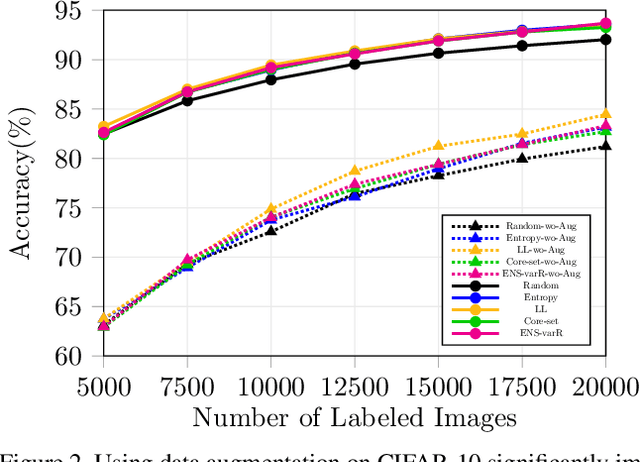
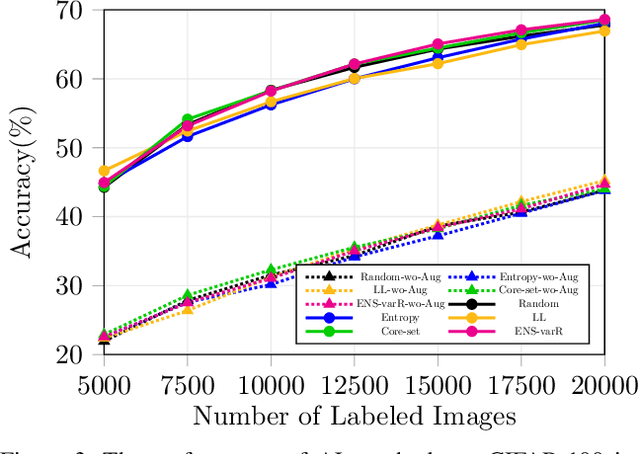
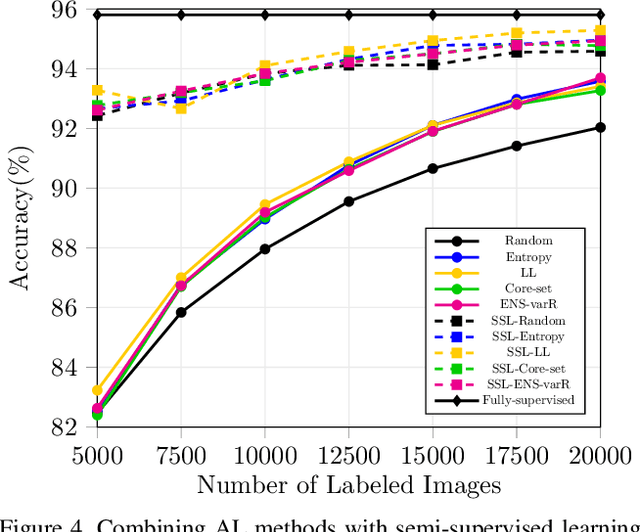
Active learning aims to reduce the high labeling cost involved in training machine learning models on large datasets by efficiently labeling only the most informative samples. Recently, deep active learning has shown success on various tasks. However, the conventional evaluation scheme used for deep active learning is below par. Current methods disregard some apparent parallel work in the closely related fields. Active learning methods are quite sensitive w.r.t. changes in the training procedure like data augmentation. They improve by a large-margin when integrated with semi-supervised learning, but barely perform better than the random baseline. We re-implement various latest active learning approaches for image classification and evaluate them under more realistic settings. We further validate our findings for semantic segmentation. Based on our observations, we realistically assess the current state of the field and propose a more suitable evaluation protocol.
Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
Aug 15, 2019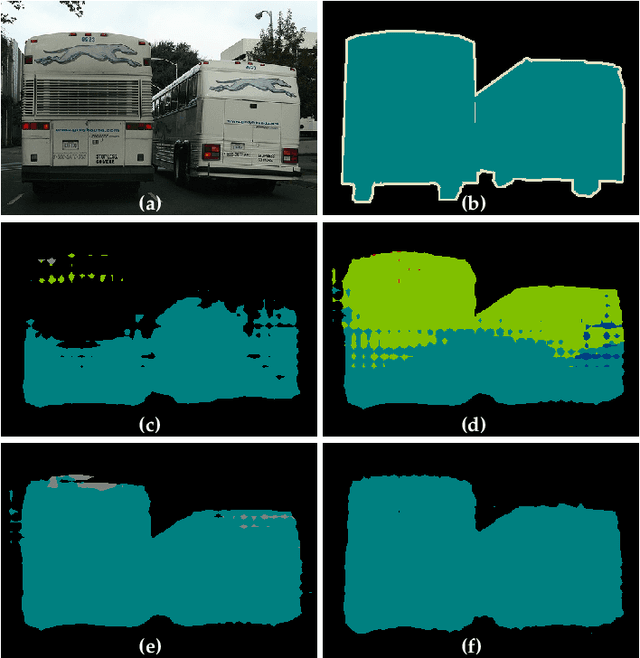
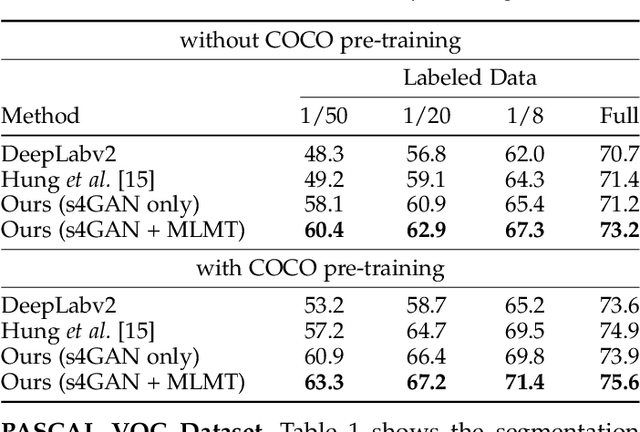
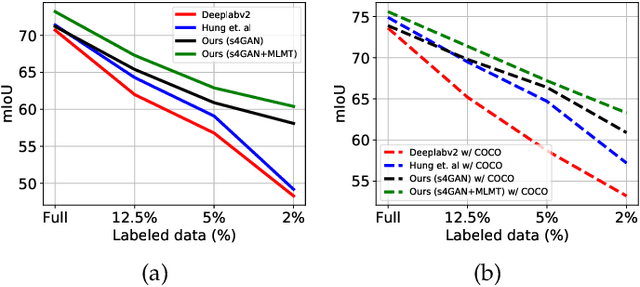
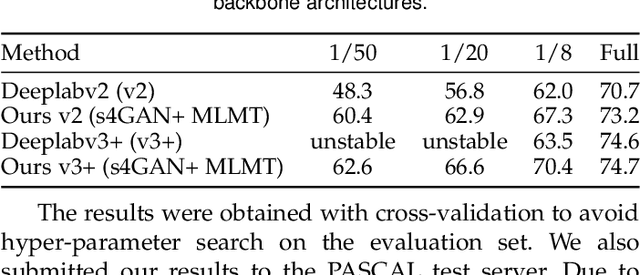
The ability to understand visual information from limited labeled data is an important aspect of machine learning. While image-level classification has been extensively studied in a semi-supervised setting, dense pixel-level classification with limited data has only drawn attention recently. In this work, we propose an approach for semi-supervised semantic segmentation that learns from limited pixel-wise annotated samples while exploiting additional annotation-free images. It uses two network branches that link semi-supervised classification with semi-supervised segmentation including self-training. The dual-branch approach reduces both the low-level and the high-level artifacts typical when training with few labels. The approach attains significant improvement over existing methods, especially when trained with very few labeled samples. On several standard benchmarks - PASCAL VOC 2012, PASCAL-Context, and Cityscapes - the approach achieves new state-of-the-art in semi-supervised learning.