 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Modification: Inverse Domain Transformation for Robust Perception
Dec 15, 2025



Generative foundation models contain broad visual knowledge and can produce diverse image variations, making them particularly promising for advancing domain generalization tasks. While they can be used for training data augmentation, synthesizing comprehensive target-domain variations remains slow, expensive, and incomplete. We propose an alternative: using diffusion models at test time to map target images back to the source distribution where the downstream model was trained. This approach requires only a source domain description, preserves the task model, and eliminates large-scale synthetic data generation. We demonstrate consistent improvements across segmentation, detection, and classification tasks under challenging environmental shifts in real-to-real domain generalization scenarios with unknown target distributions. Our analysis spans multiple generative and downstream models, including an ensemble variant for enhanced robustness. The method achieves substantial relative gains: 137% on BDD100K-Night, 68% on ImageNet-R, and 62% on DarkZurich.
TSynD: Targeted Synthetic Data Generation for Enhanced Medical Image Classification
Jun 25, 2024The usage of medical image data for the training of large-scale machine learning approaches is particularly challenging due to its scarce availability and the costly generation of data annotations, typically requiring the engagement of medical professionals. The rapid development of generative models allows towards tackling this problem by leveraging large amounts of realistic synthetically generated data for the training process. However, randomly choosing synthetic samples, might not be an optimal strategy. In this work, we investigate the targeted generation of synthetic training data, in order to improve the accuracy and robustness of image classification. Therefore, our approach aims to guide the generative model to synthesize data with high epistemic uncertainty, since large measures of epistemic uncertainty indicate underrepresented data points in the training set. During the image generation we feed images reconstructed by an auto encoder into the classifier and compute the mutual information over the class-probability distribution as a measure for uncertainty.We alter the feature space of the autoencoder through an optimization process with the objective of maximizing the classifier uncertainty on the decoded image. By training on such data we improve the performance and robustness against test time data augmentations and adversarial attacks on several classifications tasks.
LNQ Challenge 2023: Learning Mediastinal Lymph Node Segmentation with a Probabilistic Lymph Node Atlas
Jun 06, 2024



The evaluation of lymph node metastases plays a crucial role in achieving precise cancer staging, influencing subsequent decisions regarding treatment options. Lymph node detection poses challenges due to the presence of unclear boundaries and the diverse range of sizes and morphological characteristics, making it a resource-intensive process. As part of the LNQ 2023 MICCAI challenge, we propose the use of anatomical priors as a tool to address the challenges that persist in mediastinal lymph node segmentation in combination with the partial annotation of the challenge training data. The model ensemble using all suggested modifications yields a Dice score of 0.6033 and segments 57% of the ground truth lymph nodes, compared to 27% when training on CT only. Segmentation accuracy is improved significantly by incorporating a probabilistic lymph node atlas in loss weighting and post-processing. The largest performance gains are achieved by oversampling fully annotated data to account for the partial annotation of the challenge training data, as well as adding additional data augmentation to address the high heterogeneity of the CT images and lymph node appearance. Our code is available at https://github.com/MICAI-IMI-UzL/LNQ2023.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:009
Generalization by Adaptation: Diffusion-Based Domain Extension for Domain-Generalized Semantic Segmentation
Dec 04, 2023When models, e.g., for semantic segmentation, are applied to images that are vastly different from training data, the performance will drop significantly. Domain adaptation methods try to overcome this issue, but need samples from the target domain. However, this might not always be feasible for various reasons and therefore domain generalization methods are useful as they do not require any target data. We present a new diffusion-based domain extension (DIDEX) method and employ a diffusion model to generate a pseudo-target domain with diverse text prompts. In contrast to existing methods, this allows to control the style and content of the generated images and to introduce a high diversity. In a second step, we train a generalizing model by adapting towards this pseudo-target domain. We outperform previous approaches by a large margin across various datasets and architectures without using any real data. For the generalization from GTA5, we improve state-of-the-art mIoU performance by 3.8% absolute on average and for SYNTHIA by 11.8% absolute, marking a big step for the generalization performance on these benchmarks. Code is available at https://github.com/JNiemeijer/DIDEX
Survey on Unsupervised Domain Adaptation for Semantic Segmentation for Visual Perception in Automated Driving
Apr 24, 2023Deep neural networks (DNNs) have proven their capabilities in many areas in the past years, such as robotics, or automated driving, enabling technological breakthroughs. DNNs play a significant role in environment perception for the challenging application of automated driving and are employed for tasks such as detection, semantic segmentation, and sensor fusion. Despite this progress and tremendous research efforts, several issues still need to be addressed that limit the applicability of DNNs in automated driving. The bad generalization of DNNs to new, unseen domains is a major problem on the way to a safe, large-scale application, because manual annotation of new domains is costly, particularly for semantic segmentation. For this reason, methods are required to adapt DNNs to new domains without labeling effort. The task, which these methods aim to solve is termed unsupervised domain adaptation (UDA). While several different domain shifts can challenge DNNs, the shift between synthetic and real data is of particular importance for automated driving, as it allows the use of simulation environments for DNN training. In this work, we present an overview of the current state of the art in this field of research. We categorize and explain the different approaches for UDA. The number of considered publications is larger than any other survey on this topic. The scope of this survey goes far beyond the description of the UDA state-of-the-art. Based on our large data and knowledge base, we present a quantitative comparison of the approaches and use the observations to point out the latest trends in this field. In the following, we conduct a critical analysis of the state-of-the-art and highlight promising future research directions. With this survey, we aim to facilitate UDA research further and encourage scientists to exploit novel research directions to generalize DNNs better.
Revisiting Deep Active Learning for Semantic Segmentation
Feb 08, 2023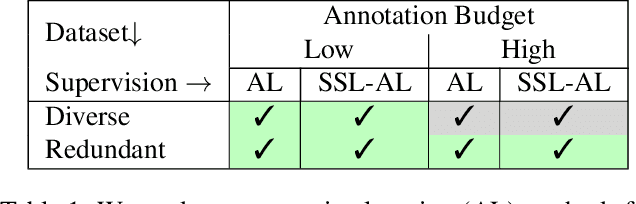
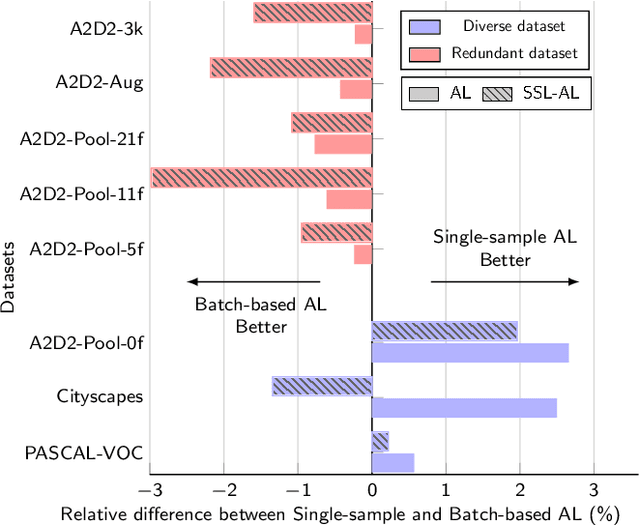


Active learning automatically selects samples for annotation from a data pool to achieve maximum performance with minimum annotation cost. This is particularly critical for semantic segmentation, where annotations are costly. In this work, we show in the context of semantic segmentation that the data distribution is decisive for the performance of the various active learning objectives proposed in the literature. Particularly, redundancy in the data, as it appears in most driving scenarios and video datasets, plays a large role. We demonstrate that the integration of semi-supervised learning with active learning can improve performance when the two objectives are aligned. Our experimental study shows that current active learning benchmarks for segmentation in driving scenarios are not realistic since they operate on data that is already curated for maximum diversity. Accordingly, we propose a more realistic evaluation scheme in which the value of active learning becomes clearly visible, both by itself and in combination with semi-supervised learning.