 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Unsupervised Domain Adaptation for Semantic Segmentation for Visual Perception in Automated Driving
Apr 24, 2023Deep neural networks (DNNs) have proven their capabilities in many areas in the past years, such as robotics, or automated driving, enabling technological breakthroughs. DNNs play a significant role in environment perception for the challenging application of automated driving and are employed for tasks such as detection, semantic segmentation, and sensor fusion. Despite this progress and tremendous research efforts, several issues still need to be addressed that limit the applicability of DNNs in automated driving. The bad generalization of DNNs to new, unseen domains is a major problem on the way to a safe, large-scale application, because manual annotation of new domains is costly, particularly for semantic segmentation. For this reason, methods are required to adapt DNNs to new domains without labeling effort. The task, which these methods aim to solve is termed unsupervised domain adaptation (UDA). While several different domain shifts can challenge DNNs, the shift between synthetic and real data is of particular importance for automated driving, as it allows the use of simulation environments for DNN training. In this work, we present an overview of the current state of the art in this field of research. We categorize and explain the different approaches for UDA. The number of considered publications is larger than any other survey on this topic. The scope of this survey goes far beyond the description of the UDA state-of-the-art. Based on our large data and knowledge base, we present a quantitative comparison of the approaches and use the observations to point out the latest trends in this field. In the following, we conduct a critical analysis of the state-of-the-art and highlight promising future research directions. With this survey, we aim to facilitate UDA research further and encourage scientists to exploit novel research directions to generalize DNNs better.
Revisiting Deep Active Learning for Semantic Segmentation
Feb 08, 2023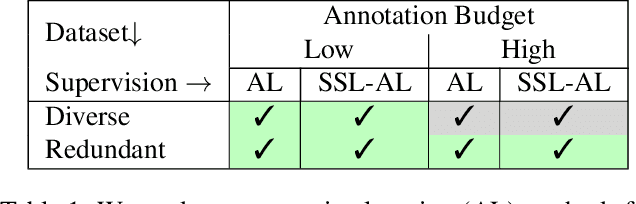
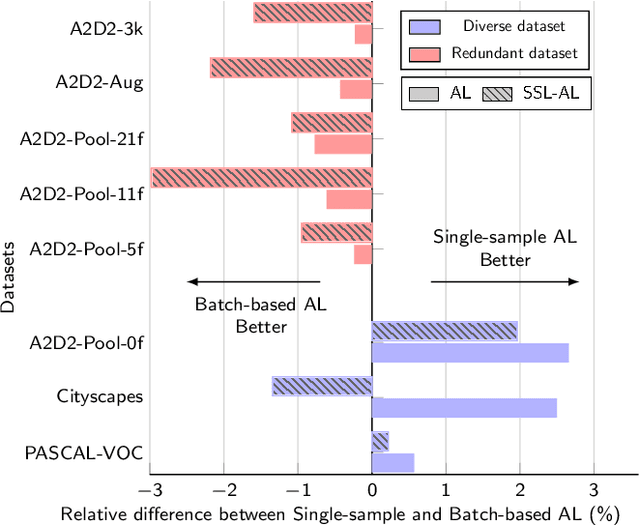


Active learning automatically selects samples for annotation from a data pool to achieve maximum performance with minimum annotation cost. This is particularly critical for semantic segmentation, where annotations are costly. In this work, we show in the context of semantic segmentation that the data distribution is decisive for the performance of the various active learning objectives proposed in the literature. Particularly, redundancy in the data, as it appears in most driving scenarios and video datasets, plays a large role. We demonstrate that the integration of semi-supervised learning with active learning can improve performance when the two objectives are aligned. Our experimental study shows that current active learning benchmarks for segmentation in driving scenarios are not realistic since they operate on data that is already curated for maximum diversity. Accordingly, we propose a more realistic evaluation scheme in which the value of active learning becomes clearly visible, both by itself and in combination with semi-supervised learning.