 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization by Adaptation: Diffusion-Based Domain Extension for Domain-Generalized Semantic Segmentation
Dec 04, 2023When models, e.g., for semantic segmentation, are applied to images that are vastly different from training data, the performance will drop significantly. Domain adaptation methods try to overcome this issue, but need samples from the target domain. However, this might not always be feasible for various reasons and therefore domain generalization methods are useful as they do not require any target data. We present a new diffusion-based domain extension (DIDEX) method and employ a diffusion model to generate a pseudo-target domain with diverse text prompts. In contrast to existing methods, this allows to control the style and content of the generated images and to introduce a high diversity. In a second step, we train a generalizing model by adapting towards this pseudo-target domain. We outperform previous approaches by a large margin across various datasets and architectures without using any real data. For the generalization from GTA5, we improve state-of-the-art mIoU performance by 3.8% absolute on average and for SYNTHIA by 11.8% absolute, marking a big step for the generalization performance on these benchmarks. Code is available at https://github.com/JNiemeijer/DIDEX
A Re-Parameterized Vision Transformer (ReVT) for Domain-Generalized Semantic Segmentation
Aug 25, 2023

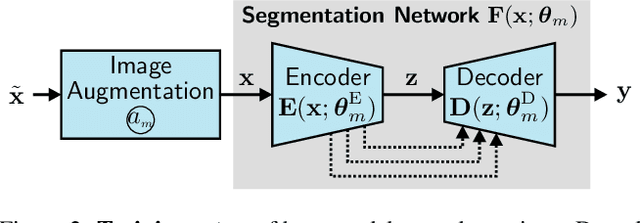

The task of semantic segmentation requires a model to assign semantic labels to each pixel of an image. However, the performance of such models degrades when deployed in an unseen domain with different data distributions compared to the training domain. We present a new augmentation-driven approach to domain generalization for semantic segmentation using a re-parameterized vision transformer (ReVT) with weight averaging of multiple models after training. We evaluate our approach on several benchmark datasets and achieve state-of-the-art mIoU performance of 47.3% (prior art: 46.3%) for small models and of 50.1% (prior art: 47.8%) for midsized models on commonly used benchmark datasets. At the same time, our method requires fewer parameters and reaches a higher frame rate than the best prior art. It is also easy to implement and, unlike network ensembles, does not add any computational complexity during inference.
Survey on Unsupervised Domain Adaptation for Semantic Segmentation for Visual Perception in Automated Driving
Apr 24, 2023Deep neural networks (DNNs) have proven their capabilities in many areas in the past years, such as robotics, or automated driving, enabling technological breakthroughs. DNNs play a significant role in environment perception for the challenging application of automated driving and are employed for tasks such as detection, semantic segmentation, and sensor fusion. Despite this progress and tremendous research efforts, several issues still need to be addressed that limit the applicability of DNNs in automated driving. The bad generalization of DNNs to new, unseen domains is a major problem on the way to a safe, large-scale application, because manual annotation of new domains is costly, particularly for semantic segmentation. For this reason, methods are required to adapt DNNs to new domains without labeling effort. The task, which these methods aim to solve is termed unsupervised domain adaptation (UDA). While several different domain shifts can challenge DNNs, the shift between synthetic and real data is of particular importance for automated driving, as it allows the use of simulation environments for DNN training. In this work, we present an overview of the current state of the art in this field of research. We categorize and explain the different approaches for UDA. The number of considered publications is larger than any other survey on this topic. The scope of this survey goes far beyond the description of the UDA state-of-the-art. Based on our large data and knowledge base, we present a quantitative comparison of the approaches and use the observations to point out the latest trends in this field. In the following, we conduct a critical analysis of the state-of-the-art and highlight promising future research directions. With this survey, we aim to facilitate UDA research further and encourage scientists to exploit novel research directions to generalize DNNs better.
On the Choice of Data for Efficient Training and Validation of End-to-End Driving Models
Jun 01, 2022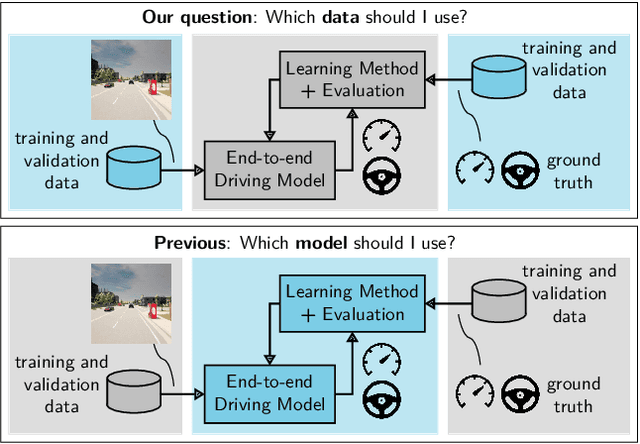
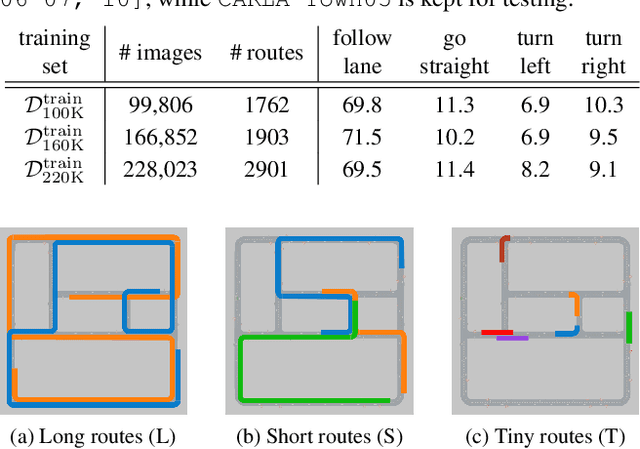
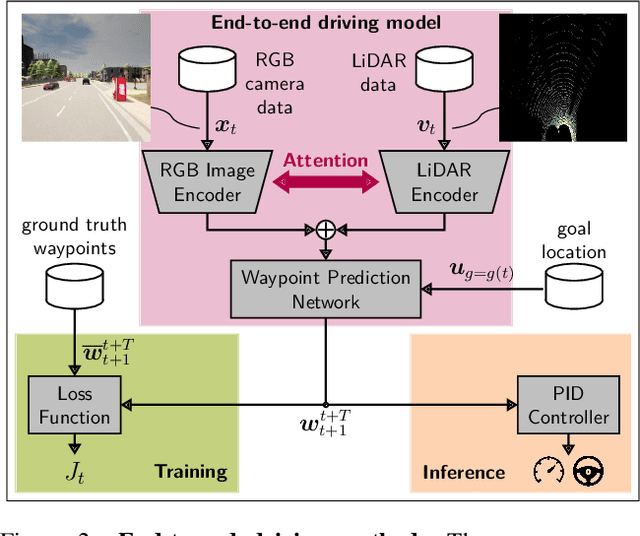
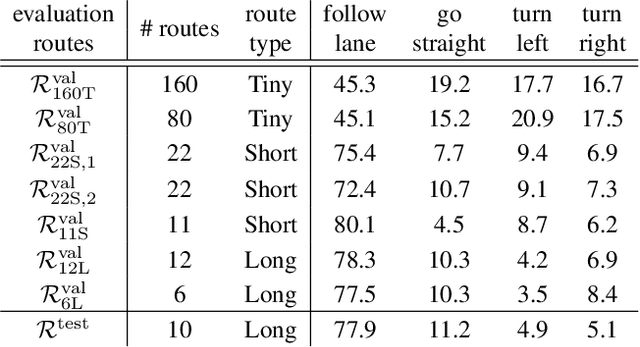
The emergence of data-driven machine learning (ML) has facilitated significant progress in many complicated tasks such as highly-automated driving. While much effort is put into improving the ML models and learning algorithms in such applications, little focus is put into how the training data and/or validation setting should be designed. In this paper we investigate the influence of several data design choices regarding training and validation of deep driving models trainable in an end-to-end fashion. Specifically, (i) we investigate how the amount of training data influences the final driving performance, and which performance limitations are induced through currently used mechanisms to generate training data. (ii) Further, we show by correlation analysis, which validation design enables the driving performance measured during validation to generalize well to unknown test environments. (iii) Finally, we investigate the effect of random seeding and non-determinism, giving insights which reported improvements can be deemed significant. Our evaluations using the popular CARLA simulator provide recommendations regarding data generation and driving route selection for an efficient future development of end-to-end driving models.
Reconfigurable Intelligent Surface Enabled Spatial Multiplexing with Fully Convolutional Network
Jan 08, 2022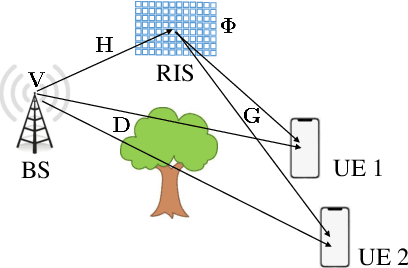
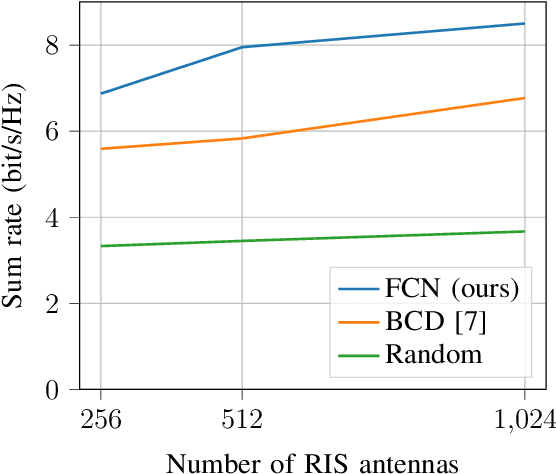
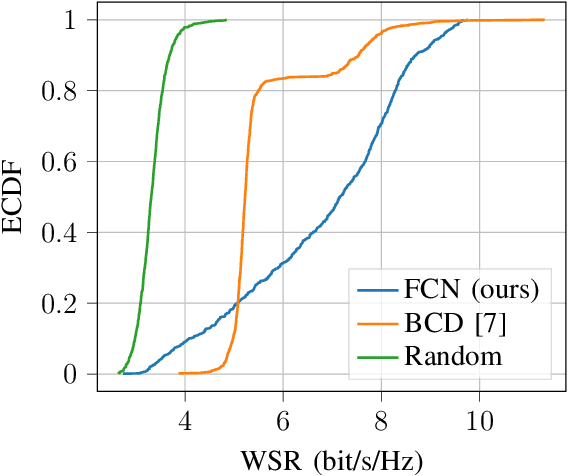
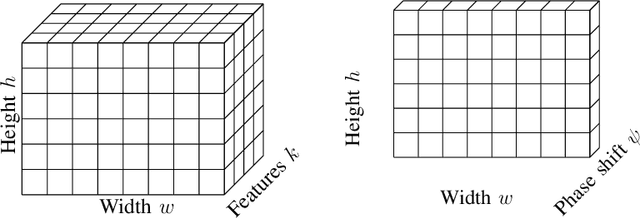
Reconfigurable intelligent surface (RIS) is an emerging technology for future wireless communication systems. In this work, we consider downlink spatial multiplexing enabled by the RIS for weighted sum-rate (WSR) maximization. In the literature, most solutions use alternating gradient-based optimization, which has moderate performance, high complexity, and limited scalability. We propose to apply a fully convolutional network (FCN) to solve this problem, which was originally designed for semantic segmentation of images. The rectangular shape of the RIS and the spatial correlation of channels with adjacent RIS antennas due to the short distance between them encourage us to apply it for the RIS configuration. We design a set of channel features that includes both cascaded channels via the RIS and the direct channel. In the base station (BS), the differentiable minimum mean squared error (MMSE) precoder is used for pretraining and the weighted minimum mean squared error (WMMSE) precoder is then applied for fine-tuning, which is nondifferentiable, more complex, but achieves a better performance. Evaluation results show that the proposed solution has higher performance and allows for a faster evaluation than the baselines. Hence it scales better to a large number of antennas, advancing the RIS one step closer to practical deployment.
Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches
Feb 11, 2021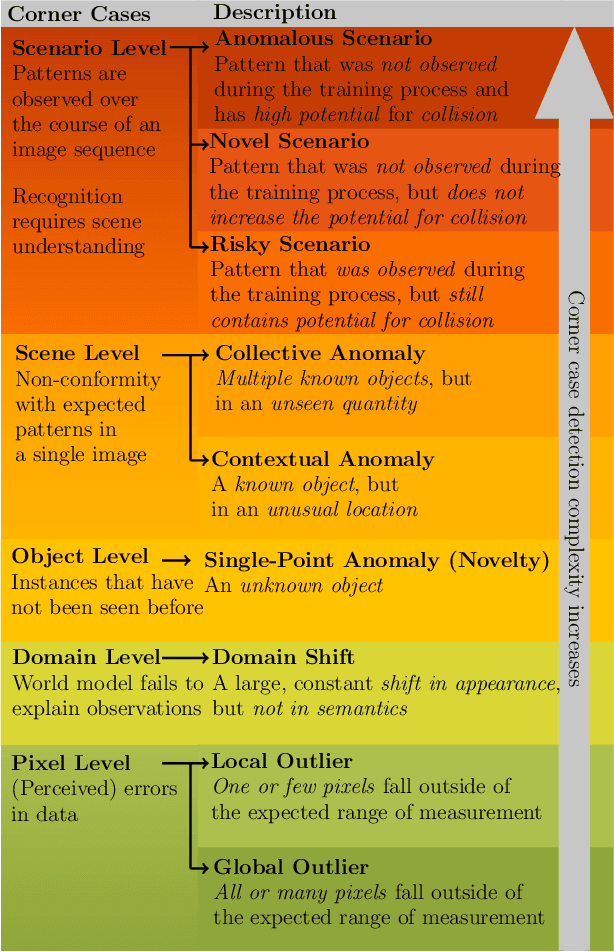


Automated driving has become a major topic of interest not only in the active research community but also in mainstream media reports. Visual perception of such intelligent vehicles has experienced large progress in the last decade thanks to advances in deep learning techniques but some challenges still remain. One such challenge is the detection of corner cases. They are unexpected and unknown situations that occur while driving. Conventional visual perception methods are often not able to detect them because corner cases have not been witnessed during training. Hence, their detection is highly safety-critical, and detection methods can be applied to vast amounts of collected data to select suitable training data. A reliable detection of corner cases will not only further automate the data selection procedure and increase safety in autonomous driving but can thereby also affect the public acceptance of the new technology in a positive manner. In this work, we continue a previous systematization of corner cases on different levels by an extended set of examples for each level. Moreover, we group detection approaches into different categories and link them with the corner case levels. Hence, we give directions to showcase specific corner cases and basic guidelines on how to technically detect them.
Unsupervised BatchNorm Adaptation (UBNA): A Domain Adaptation Method for Semantic Segmentation Without Using Source Domain Representations
Nov 17, 2020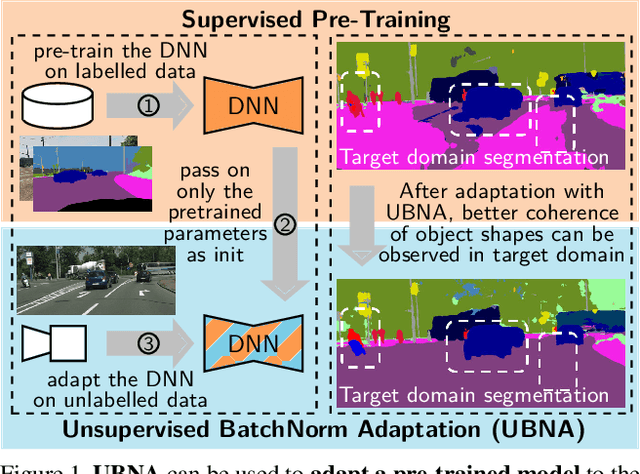
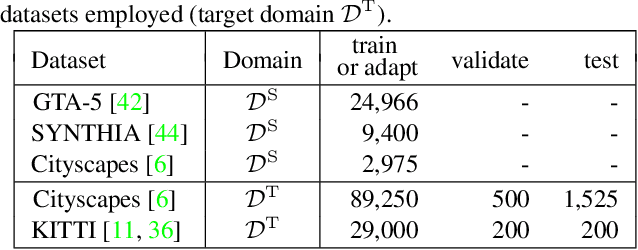
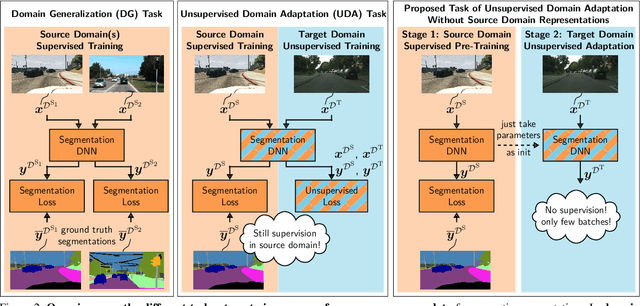
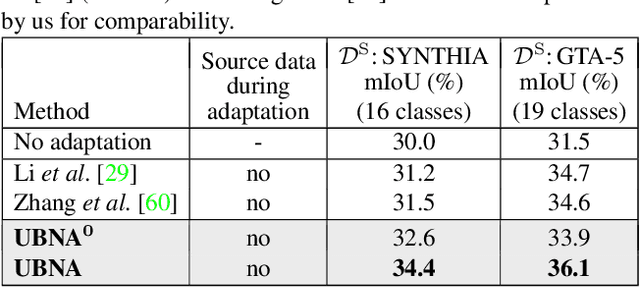
In this paper we present a solution to the task of "unsupervised domain adaptation (UDA) of a pre-trained semantic segmentation model without relying on any source domain representations". Previous UDA approaches for semantic segmentation either employed simultaneous training of the model in the source and target domains, or they relied on a generator network, replaying source domain data to the model during adaptation. In contrast, we present our novel Unsupervised BatchNorm Adaptation (UBNA) method, which adapts a pre-trained model to an unseen target domain without using---beyond the existing model parameters from pre-training---any source domain representations (neither data, nor generators) and which can also be applied in an online setting or using just a few unlabeled images from the target domain in a few-shot manner. Specifically, we partially adapt the normalization layer statistics to the target domain using an exponentially decaying momentum factor, thereby mixing the statistics from both domains. By evaluation on standard UDA benchmarks for semantic segmentation we show that this is superior to a model without adaptation and to baseline approaches using statistics from the target domain only. Compared to standard UDA approaches we report a trade-off between performance and usage of source domain representations.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 21, 2020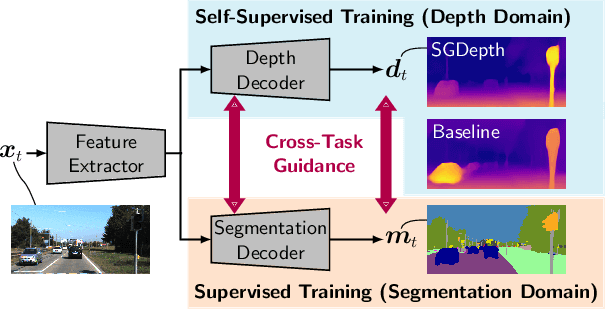
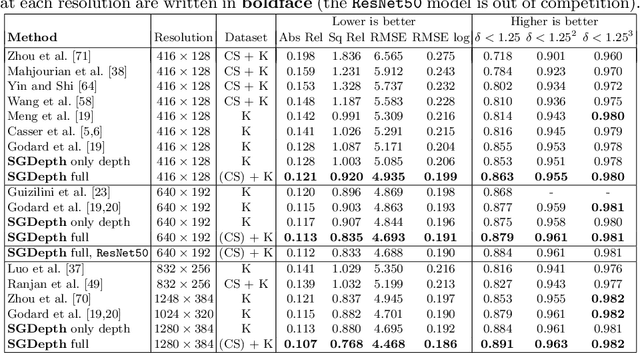
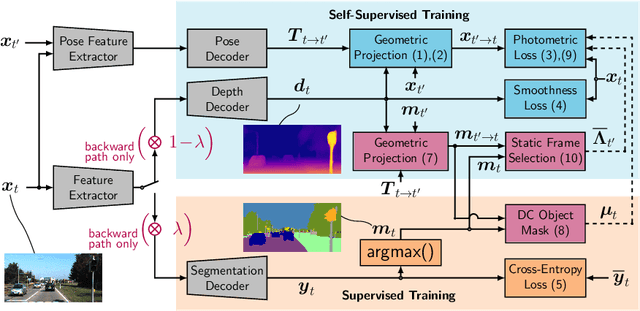
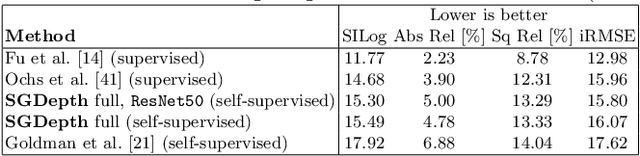
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement.
openDD: A Large-Scale Roundabout Drone Dataset
Jul 16, 2020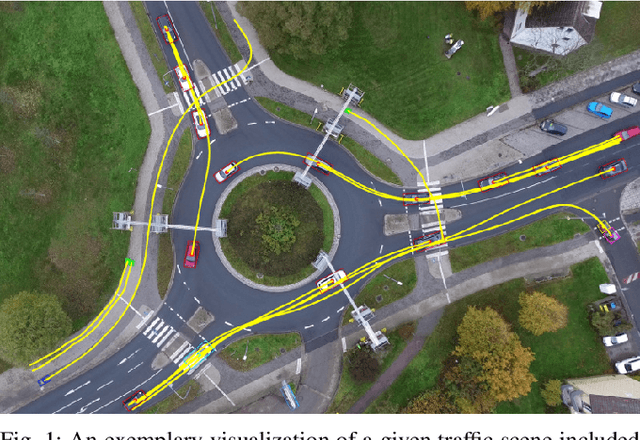

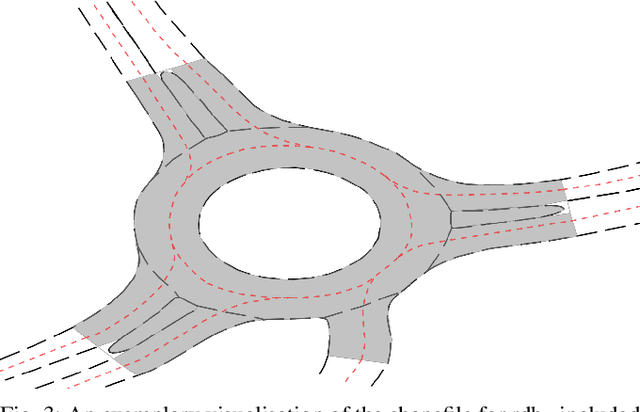
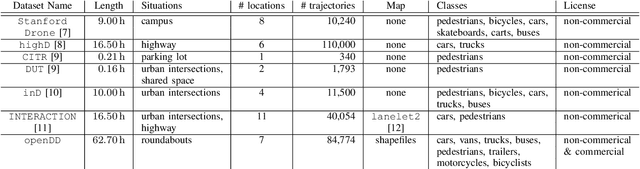
Analyzing and predicting the traffic scene around the ego vehicle has been one of the key challenges in autonomous driving. Datasets including the trajectories of all road users present in a scene, as well as the underlying road topology are invaluable to analyze the behavior of the different traffic participants. The interaction between the various traffic participants is especially high in intersection types that are not regulated by traffic lights, the most common one being the roundabout. We introduce the openDD dataset, including 84,774 accurately tracked trajectories and HD map data of seven different roundabouts. The openDD dataset is annotated using images taken by a drone in 501 separate flights, totalling in over 62 hours of trajectory data. As of today, openDD is by far the largest publicly available trajectory dataset recorded from a drone perspective, while comparable datasets span 17 hours at most. The data is available, for both commercial and noncommercial use, at: http://www.l3pilot.eu/openDD.