 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Semantic Segmentation with Efficient Joint Source and Task Decoding
Jul 15, 2024



Distributed computing in the context of deep neural networks (DNNs) implies the execution of one part of the network on edge devices and the other part typically on a large-scale cloud platform. Conventional methods propose to employ a serial concatenation of a learned image and source encoder, the latter projecting the image encoder output (bottleneck features) into a quantized representation for bitrate-efficient transmission. In the cloud, a respective source decoder reprojects the quantized representation to the original feature representation, serving as an input for the downstream task decoder performing, e.g., semantic segmentation. In this work, we propose joint source and task decoding, as it allows for a smaller network size in the cloud. This further enables the scalability of such services in large numbers without requiring extensive computational load on the cloud per channel. We demonstrate the effectiveness of our method by achieving a distributed semantic segmentation SOTA over a wide range of bitrates on the mean intersection over union metric, while using only $9.8 \%$ ... $11.59 \%$ of cloud DNN parameters used in the previous SOTA on the COCO and Cityscapes datasets.
A Re-Parameterized Vision Transformer (ReVT) for Domain-Generalized Semantic Segmentation
Aug 25, 2023

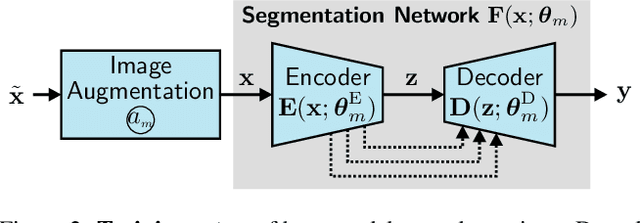

The task of semantic segmentation requires a model to assign semantic labels to each pixel of an image. However, the performance of such models degrades when deployed in an unseen domain with different data distributions compared to the training domain. We present a new augmentation-driven approach to domain generalization for semantic segmentation using a re-parameterized vision transformer (ReVT) with weight averaging of multiple models after training. We evaluate our approach on several benchmark datasets and achieve state-of-the-art mIoU performance of 47.3% (prior art: 46.3%) for small models and of 50.1% (prior art: 47.8%) for midsized models on commonly used benchmark datasets. At the same time, our method requires fewer parameters and reaches a higher frame rate than the best prior art. It is also easy to implement and, unlike network ensembles, does not add any computational complexity during inference.