 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Amodal Video Instance Segmentation in Automated Driving
Sep 21, 2024In this work, we study amodal video instance segmentation for automated driving. Previous works perform amodal video instance segmentation relying on methods trained on entirely labeled video data with techniques borrowed from standard video instance segmentation. Such amodally labeled video data is difficult and expensive to obtain and the resulting methods suffer from a trade-off between instance segmentation and tracking performance. To largely solve this issue, we propose to study the application of foundation models for this task. More precisely, we exploit the extensive knowledge of the Segment Anything Model (SAM), while fine-tuning it to the amodal instance segmentation task. Given an initial video instance segmentation, we sample points from the visible masks to prompt our amodal SAM. We use a point memory to store those points. If a previously observed instance is not predicted in a following frame, we retrieve its most recent points from the point memory and use a point tracking method to follow those points to the current frame, together with the corresponding last amodal instance mask. This way, while basing our method on an amodal instance segmentation, we nevertheless obtain video-level amodal instance segmentation results. Our resulting S-AModal method achieves state-of-the-art results in amodal video instance segmentation while resolving the need for amodal video-based labels. Code for S-AModal is available at https://github.com/ifnspaml/S-AModal.
On the Choice of Data for Efficient Training and Validation of End-to-End Driving Models
Jun 01, 2022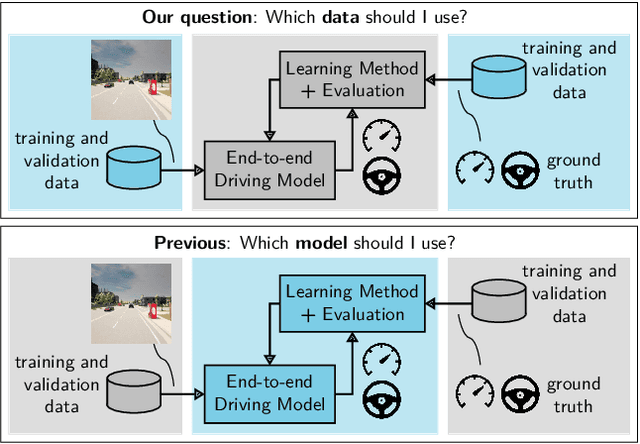
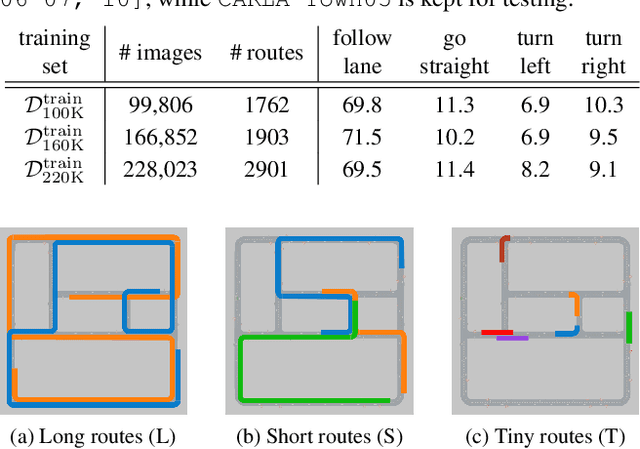
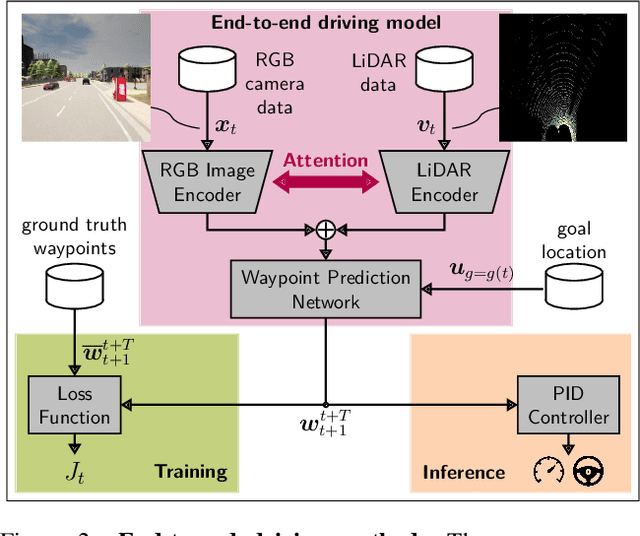
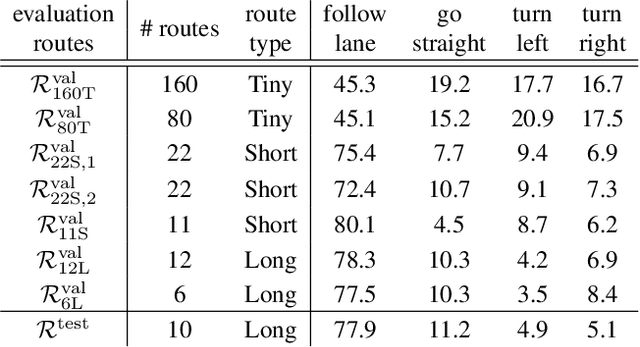
The emergence of data-driven machine learning (ML) has facilitated significant progress in many complicated tasks such as highly-automated driving. While much effort is put into improving the ML models and learning algorithms in such applications, little focus is put into how the training data and/or validation setting should be designed. In this paper we investigate the influence of several data design choices regarding training and validation of deep driving models trainable in an end-to-end fashion. Specifically, (i) we investigate how the amount of training data influences the final driving performance, and which performance limitations are induced through currently used mechanisms to generate training data. (ii) Further, we show by correlation analysis, which validation design enables the driving performance measured during validation to generalize well to unknown test environments. (iii) Finally, we investigate the effect of random seeding and non-determinism, giving insights which reported improvements can be deemed significant. Our evaluations using the popular CARLA simulator provide recommendations regarding data generation and driving route selection for an efficient future development of end-to-end driving models.
Amodal Cityscapes: A New Dataset, its Generation, and an Amodal Semantic Segmentation Challenge Baseline
Jun 01, 2022



Amodal perception terms the ability of humans to imagine the entire shapes of occluded objects. This gives humans an advantage to keep track of everything that is going on, especially in crowded situations. Typical perception functions, however, lack amodal perception abilities and are therefore at a disadvantage in situations with occlusions. Complex urban driving scenarios often experience many different types of occlusions and, therefore, amodal perception for automated vehicles is an important task to investigate. In this paper, we consider the task of amodal semantic segmentation and propose a generic way to generate datasets to train amodal semantic segmentation methods. We use this approach to generate an amodal Cityscapes dataset. Moreover, we propose and evaluate a method as baseline on Amodal Cityscapes, showing its applicability for amodal semantic segmentation in automotive environment perception. We provide the means to re-generate this dataset on github.
Description of Corner Cases in Automated Driving: Goals and Challenges
Sep 28, 2021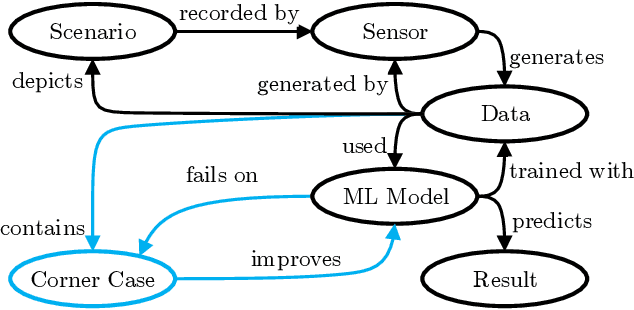


Scaling the distribution of automated vehicles requires handling various unexpected and possibly dangerous situations, termed corner cases (CC). Since many modules of automated driving systems are based on machine learning (ML), CC are an essential part of the data for their development. However, there is only a limited amount of CC data in large-scale data collections, which makes them challenging in the context of ML. With a better understanding of CC, offline applications, e.g., dataset analysis, and online methods, e.g., improved performance of automated driving systems, can be improved. While there are knowledge-based descriptions and taxonomies for CC, there is little research on machine-interpretable descriptions. In this extended abstract, we will give a brief overview of the challenges and goals of such a description.
An Application-Driven Conceptualization of Corner Cases for Perception in Highly Automated Driving
Mar 05, 2021
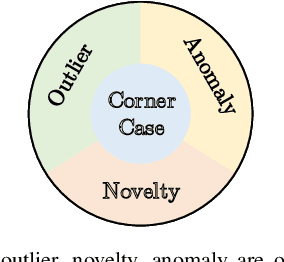
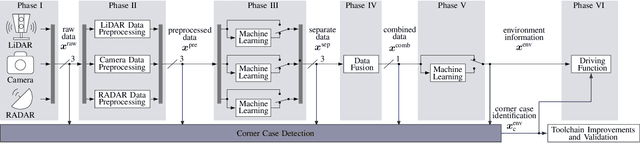
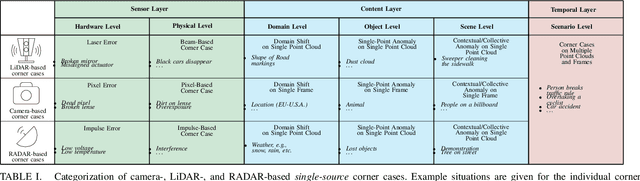
Systems and functions that rely on machine learning (ML) are the basis of highly automated driving. An essential task of such ML models is to reliably detect and interpret unusual, new, and potentially dangerous situations. The detection of those situations, which we refer to as corner cases, is highly relevant for successfully developing, applying, and validating automotive perception functions in future vehicles where multiple sensor modalities will be used. A complication for the development of corner case detectors is the lack of consistent definitions, terms, and corner case descriptions, especially when taking into account various automotive sensors. In this work, we provide an application-driven view of corner cases in highly automated driving. To achieve this goal, we first consider existing definitions from the general outlier, novelty, anomaly, and out-of-distribution detection to show relations and differences to corner cases. Moreover, we extend an existing camera-focused systematization of corner cases by adding RADAR (radio detection and ranging) and LiDAR (light detection and ranging) sensors. For this, we describe an exemplary toolchain for data acquisition and processing, highlighting the interfaces of the corner case detection. We also define a novel level of corner cases, the method layer corner cases, which appear due to uncertainty inherent in the methodology or the data distribution.
Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches
Feb 11, 2021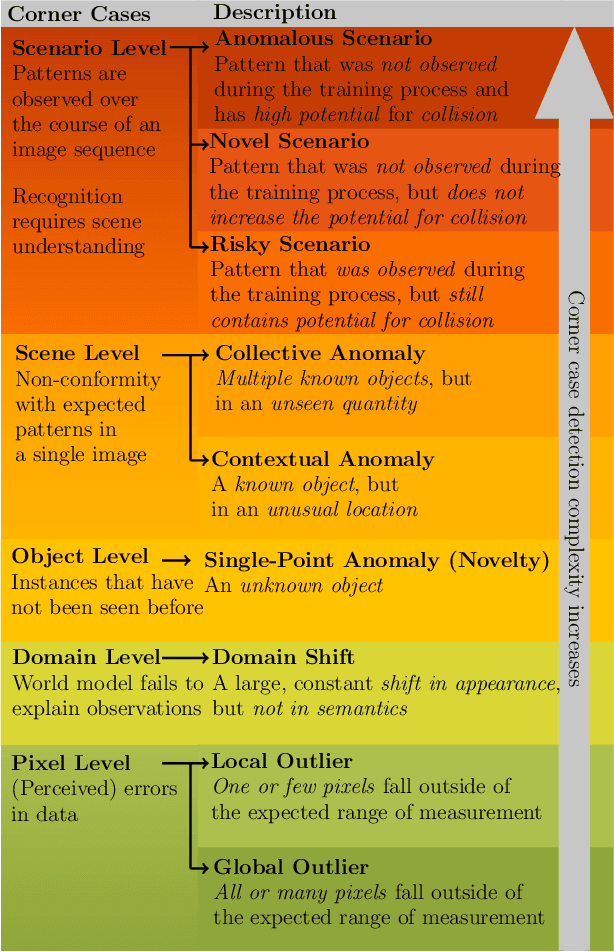


Automated driving has become a major topic of interest not only in the active research community but also in mainstream media reports. Visual perception of such intelligent vehicles has experienced large progress in the last decade thanks to advances in deep learning techniques but some challenges still remain. One such challenge is the detection of corner cases. They are unexpected and unknown situations that occur while driving. Conventional visual perception methods are often not able to detect them because corner cases have not been witnessed during training. Hence, their detection is highly safety-critical, and detection methods can be applied to vast amounts of collected data to select suitable training data. A reliable detection of corner cases will not only further automate the data selection procedure and increase safety in autonomous driving but can thereby also affect the public acceptance of the new technology in a positive manner. In this work, we continue a previous systematization of corner cases on different levels by an extended set of examples for each level. Moreover, we group detection approaches into different categories and link them with the corner case levels. Hence, we give directions to showcase specific corner cases and basic guidelines on how to technically detect them.