 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Performance of Semantic Segmentation CycleGANs by Noise Injection into the Latent Segmentation Space
Jan 17, 2022In recent years, semantic segmentation has taken benefit from various works in computer vision. Inspired by the very versatile CycleGAN architecture, we combine semantic segmentation with the concept of cycle consistency to enable a multitask training protocol. However, learning is largely prevented by the so-called steganography effect, which expresses itself as watermarks in the latent segmentation domain, making image reconstruction a too easy task. To combat this, we propose a noise injection, based either on quantization noise or on Gaussian noise addition to avoid this disadvantageous information flow in the cycle architecture. We find that noise injection significantly reduces the generation of watermarks and thus allows the recognition of highly relevant classes such as "traffic signs", which are hardly detected by the ERFNet baseline. We report mIoU and PSNR results on the Cityscapes dataset for semantic segmentation and image reconstruction, respectively. The proposed methodology allows to achieve an mIoU improvement on the Cityscapes validation set of 5.7% absolute over the same CycleGAN without noise injection, and still an absolute 4.9% over the ERFNet non-cyclic baseline.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
An Application-Driven Conceptualization of Corner Cases for Perception in Highly Automated Driving
Mar 05, 2021
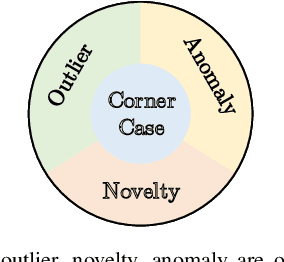
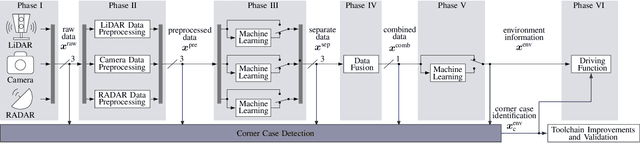
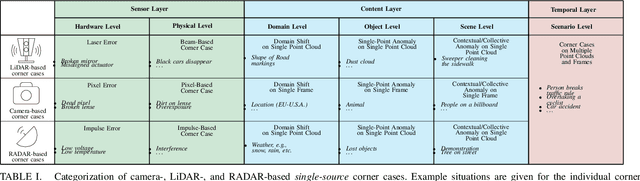
Systems and functions that rely on machine learning (ML) are the basis of highly automated driving. An essential task of such ML models is to reliably detect and interpret unusual, new, and potentially dangerous situations. The detection of those situations, which we refer to as corner cases, is highly relevant for successfully developing, applying, and validating automotive perception functions in future vehicles where multiple sensor modalities will be used. A complication for the development of corner case detectors is the lack of consistent definitions, terms, and corner case descriptions, especially when taking into account various automotive sensors. In this work, we provide an application-driven view of corner cases in highly automated driving. To achieve this goal, we first consider existing definitions from the general outlier, novelty, anomaly, and out-of-distribution detection to show relations and differences to corner cases. Moreover, we extend an existing camera-focused systematization of corner cases by adding RADAR (radio detection and ranging) and LiDAR (light detection and ranging) sensors. For this, we describe an exemplary toolchain for data acquisition and processing, highlighting the interfaces of the corner case detection. We also define a novel level of corner cases, the method layer corner cases, which appear due to uncertainty inherent in the methodology or the data distribution.
The Vulnerability of Semantic Segmentation Networks to Adversarial Attacks in Autonomous Driving: Enhancing Extensive Environment Sensing
Jan 13, 2021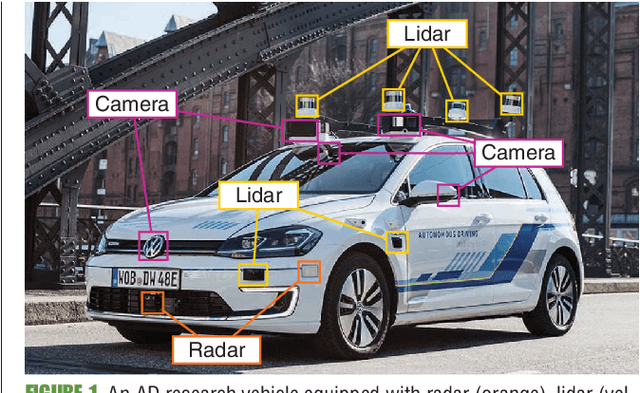

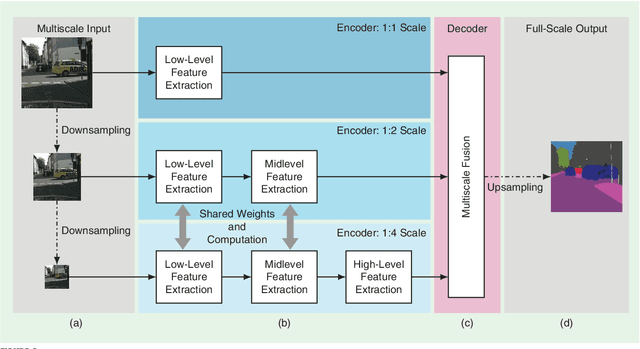
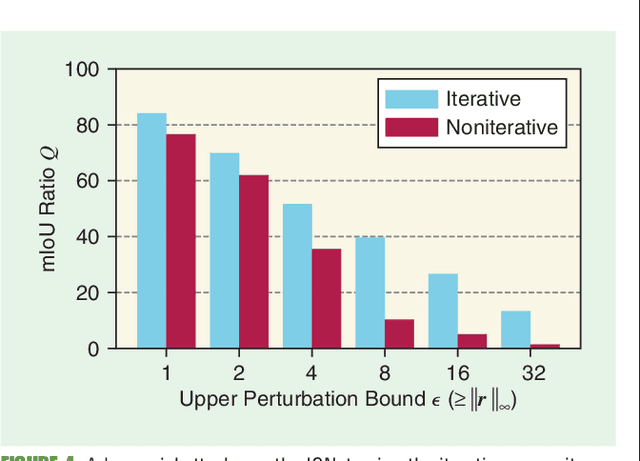
Enabling autonomous driving (AD) can be considered one of the biggest challenges in today's technology. AD is a complex task accomplished by several functionalities, with environment perception being one of its core functions. Environment perception is usually performed by combining the semantic information captured by several sensors, i.e., lidar or camera. The semantic information from the respective sensor can be extracted by using convolutional neural networks (CNNs) for dense prediction. In the past, CNNs constantly showed state-of-the-art performance on several vision-related tasks, such as semantic segmentation of traffic scenes using nothing but the red-green-blue (RGB) images provided by a camera. Although CNNs obtain state-of-the-art performance on clean images, almost imperceptible changes to the input, referred to as adversarial perturbations, may lead to fatal deception. The goal of this article is to illuminate the vulnerability aspects of CNNs used for semantic segmentation with respect to adversarial attacks, and share insights into some of the existing known adversarial defense strategies. We aim to clarify the advantages and disadvantages associated with applying CNNs for environment perception in AD to serve as a motivation for future research in this field.
A Self-Supervised Feature Map Augmentation (FMA) Loss and Combined Augmentations Finetuning to Efficiently Improve the Robustness of CNNs
Dec 02, 2020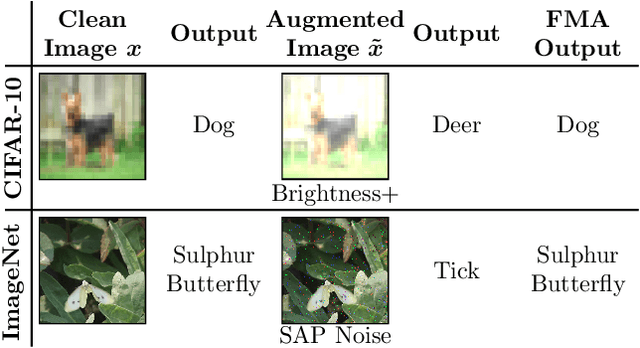
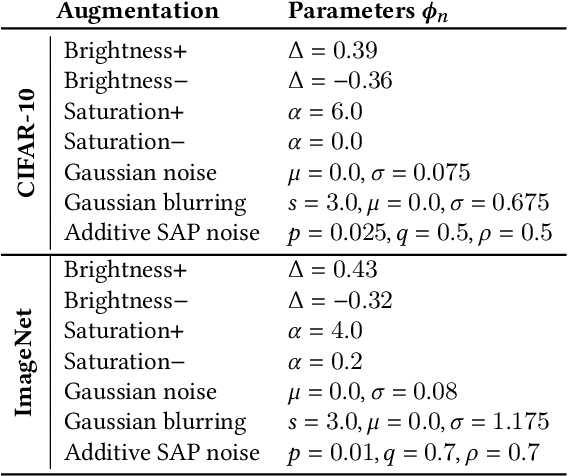
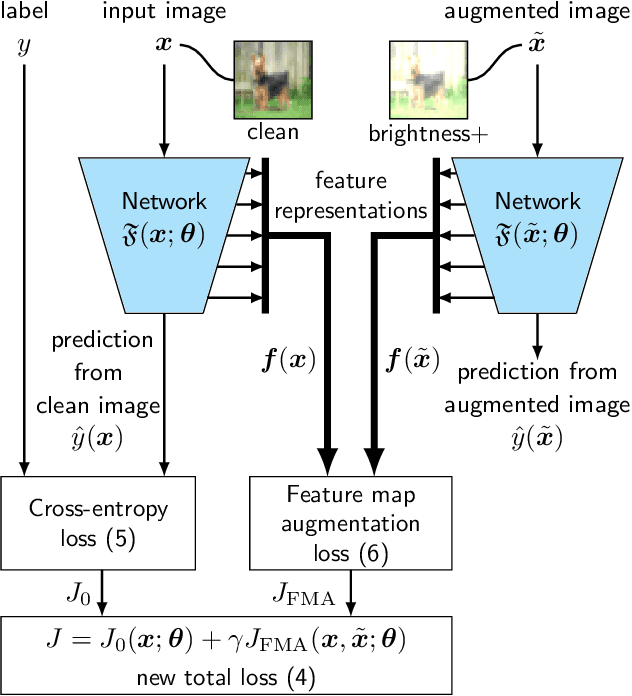
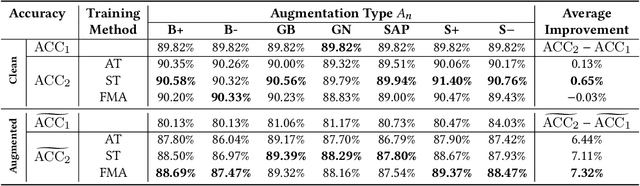
Deep neural networks are often not robust to semantically-irrelevant changes in the input. In this work we address the issue of robustness of state-of-the-art deep convolutional neural networks (CNNs) against commonly occurring distortions in the input such as photometric changes, or the addition of blur and noise. These changes in the input are often accounted for during training in the form of data augmentation. We have two major contributions: First, we propose a new regularization loss called feature-map augmentation (FMA) loss which can be used during finetuning to make a model robust to several distortions in the input. Second, we propose a new combined augmentations (CA) finetuning strategy, that results in a single model that is robust to several augmentation types at the same time in a data-efficient manner. We use the CA strategy to improve an existing state-of-the-art method called stability training (ST). Using CA, on an image classification task with distorted images, we achieve an accuracy improvement of on average 8.94% with FMA and 8.86% with ST absolute on CIFAR-10 and 8.04% with FMA and 8.27% with ST absolute on ImageNet, compared to 1.98% and 2.12%, respectively, with the well known data augmentation method, while keeping the clean baseline performance.
Self-Supervised Domain Mismatch Estimation for Autonomous Perception
Jun 15, 2020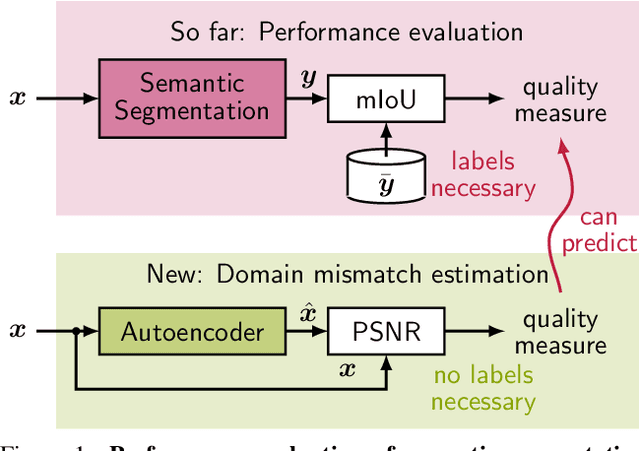
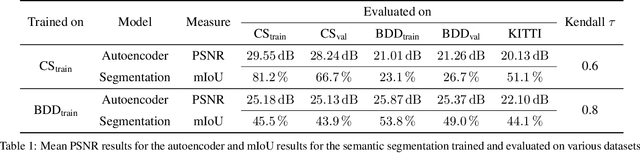
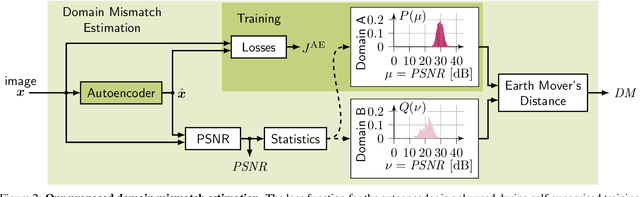
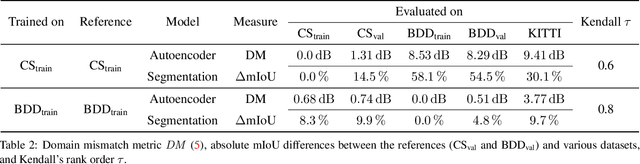
Autonomous driving requires self awareness of its perception functions. Technically spoken, this can be realized by observers, which monitor the performance indicators of various perception modules. In this work we choose, exemplarily, a semantic segmentation to be monitored, and propose an autoencoder, trained in a self-supervised fashion on the very same training data as the semantic segmentation to be monitored. While the autoencoder's image reconstruction performance (PSNR) during online inference shows already a good predictive power w.r.t. semantic segmentation performance, we propose a novel domain mismatch metric DM as the earth mover's distance between a pre-stored PSNR distribution on training (source) data, and an online-acquired PSNR distribution on any inference (target) data. We are able to show by experiments that the DM metric has a strong rank order correlation with the semantic segmentation within its functional scope. We also propose a training domain-dependent threshold for the DM metric to define this functional scope.
GAN- vs. JPEG2000 Image Compression for Distributed Automotive Perception: Higher Peak SNR Does Not Mean Better Semantic Segmentation
Feb 12, 2019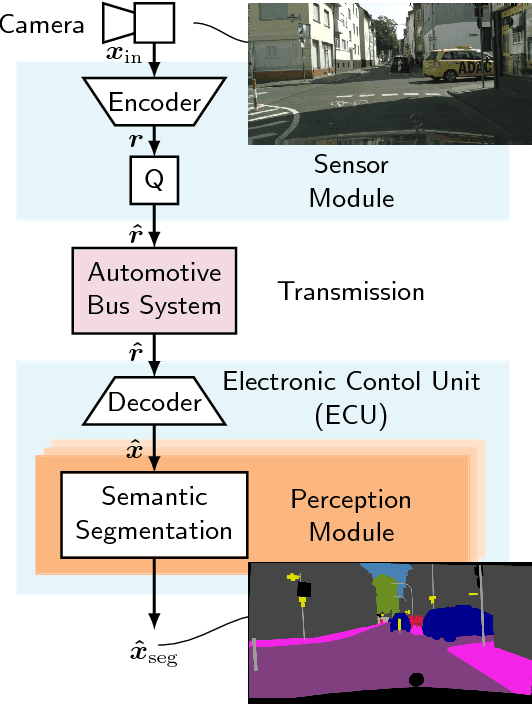
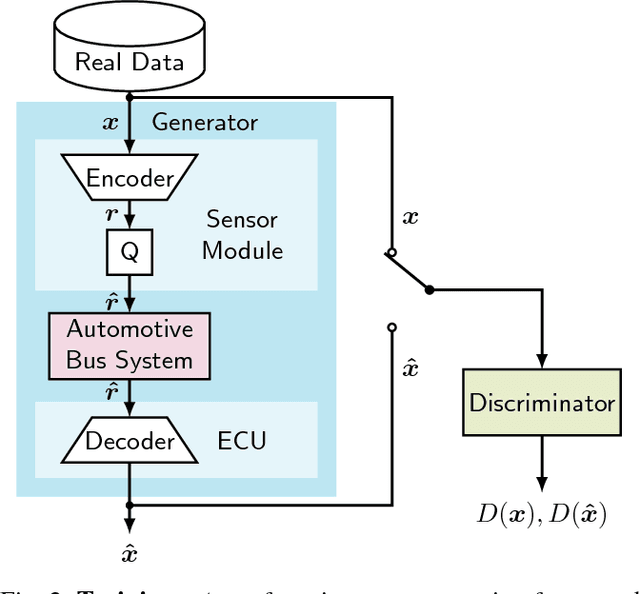
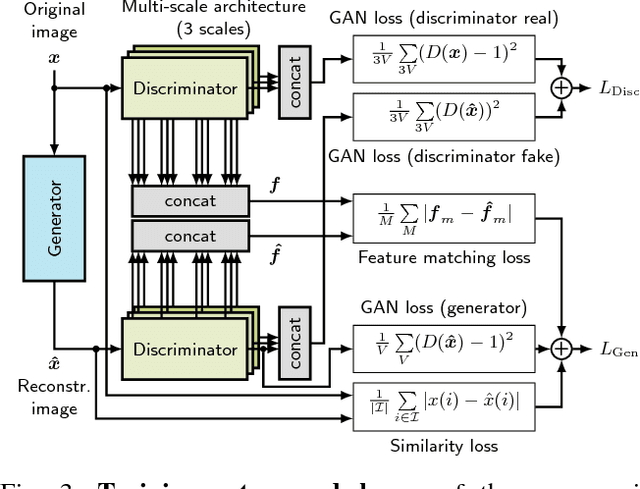

The high amount of sensors required for autonomous driving poses enormous challenges on the capacity of automotive bus systems. There is a need to understand tradeoffs between bitrate and perception performance. In this paper, we compare the image compression standards JPEG, JPEG2000, and WebP to a modern encoder/decoder image compression approach based on generative adversarial networks (GANs). We evaluate both the pure compression performance using typical metrics such as peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and others, but also the performance of a subsequent perception function, namely a semantic segmentation (characterized by the mean intersection over union (mIoU) measure). Not surprisingly, for all investigated compression methods, a higher bitrate means better results in all investigated quality metrics. Interestingly, however, we show that the semantic segmentation mIoU of the GAN autoencoder in the highly relevant low-bitrate regime (at 0.0625 bit/pixel) is better by 3.9% absolute than JPEG2000, although the latter still is considerably better in terms of PSNR (5.91 dB difference). This effect can greatly be enlarged by training the semantic segmentation model with images originating from the decoder, so that the mIoU using the segmentation model trained by GAN reconstructions exceeds the use of the model trained with original images by almost 20% absolute. We conclude that distributed perception in future autonomous driving will most probably not provide a solution to the automotive bus capacity bottleneck by using standard compression schemes such as JPEG2000, but requires modern coding approaches, with the GAN encoder/decoder method being a promising candidate.