 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription of Corner Cases in Automated Driving: Goals and Challenges
Paper and Code
Sep 28, 2021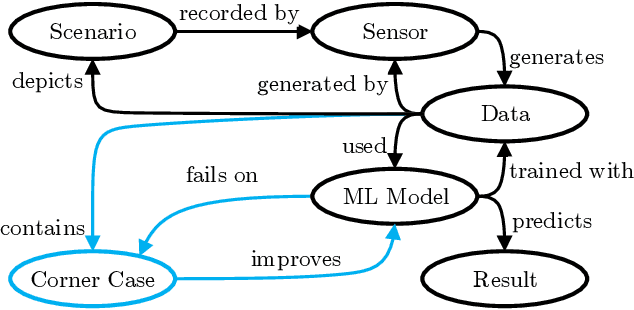


Scaling the distribution of automated vehicles requires handling various unexpected and possibly dangerous situations, termed corner cases (CC). Since many modules of automated driving systems are based on machine learning (ML), CC are an essential part of the data for their development. However, there is only a limited amount of CC data in large-scale data collections, which makes them challenging in the context of ML. With a better understanding of CC, offline applications, e.g., dataset analysis, and online methods, e.g., improved performance of automated driving systems, can be improved. While there are knowledge-based descriptions and taxonomies for CC, there is little research on machine-interpretable descriptions. In this extended abstract, we will give a brief overview of the challenges and goals of such a description.