 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised BatchNorm Adaptation (UBNA): A Domain Adaptation Method for Semantic Segmentation Without Using Source Domain Representations
Nov 17, 2020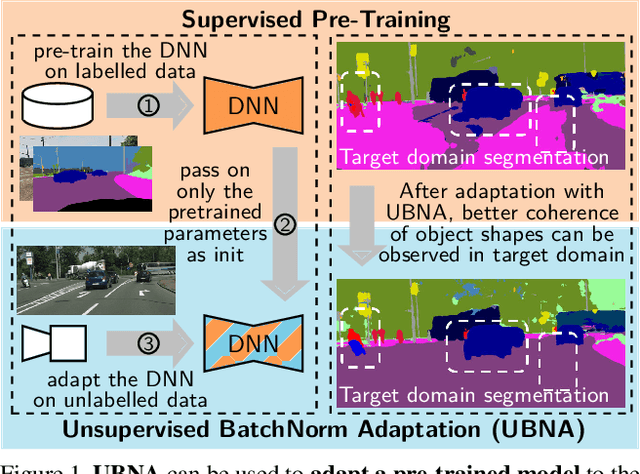
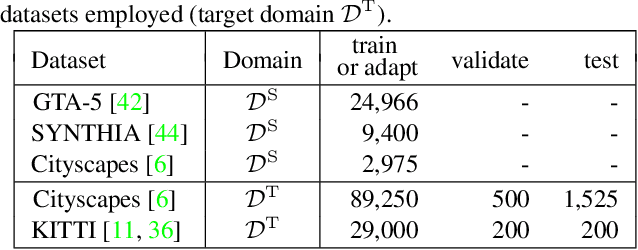
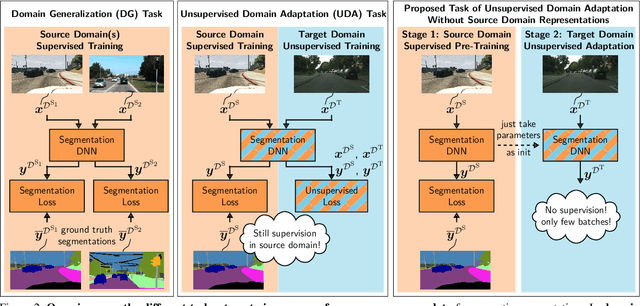
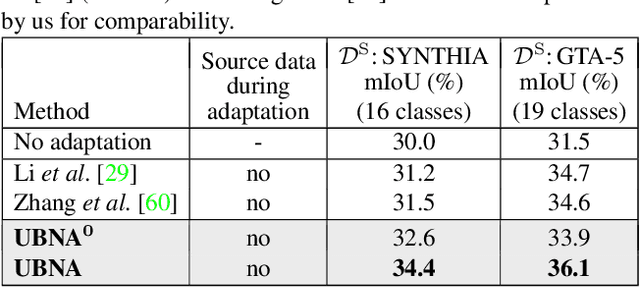
In this paper we present a solution to the task of "unsupervised domain adaptation (UDA) of a pre-trained semantic segmentation model without relying on any source domain representations". Previous UDA approaches for semantic segmentation either employed simultaneous training of the model in the source and target domains, or they relied on a generator network, replaying source domain data to the model during adaptation. In contrast, we present our novel Unsupervised BatchNorm Adaptation (UBNA) method, which adapts a pre-trained model to an unseen target domain without using---beyond the existing model parameters from pre-training---any source domain representations (neither data, nor generators) and which can also be applied in an online setting or using just a few unlabeled images from the target domain in a few-shot manner. Specifically, we partially adapt the normalization layer statistics to the target domain using an exponentially decaying momentum factor, thereby mixing the statistics from both domains. By evaluation on standard UDA benchmarks for semantic segmentation we show that this is superior to a model without adaptation and to baseline approaches using statistics from the target domain only. Compared to standard UDA approaches we report a trade-off between performance and usage of source domain representations.