 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust a Glimpse: Rethinking Temporal Information for Video Continual Learning
May 28, 2023Class-incremental learning is one of the most important settings for the study of Continual Learning, as it closely resembles real-world application scenarios. With constrained memory sizes, catastrophic forgetting arises as the number of classes/tasks increases. Studying continual learning in the video domain poses even more challenges, as video data contains a large number of frames, which places a higher burden on the replay memory. The current common practice is to sub-sample frames from the video stream and store them in the replay memory. In this paper, we propose SMILE a novel replay mechanism for effective video continual learning based on individual/single frames. Through extensive experimentation, we show that under extreme memory constraints, video diversity plays a more significant role than temporal information. Therefore, our method focuses on learning from a small number of frames that represent a large number of unique videos. On three representative video datasets, Kinetics, UCF101, and ActivityNet, the proposed method achieves state-of-the-art performance, outperforming the previous state-of-the-art by up to 21.49%.
End-to-End Active Speaker Detection
Mar 27, 2022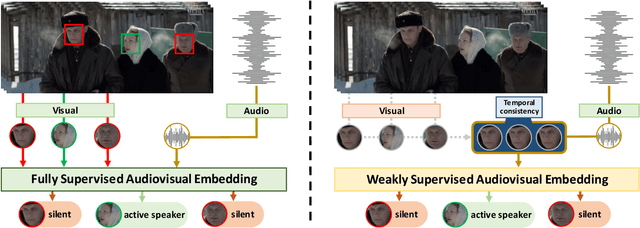
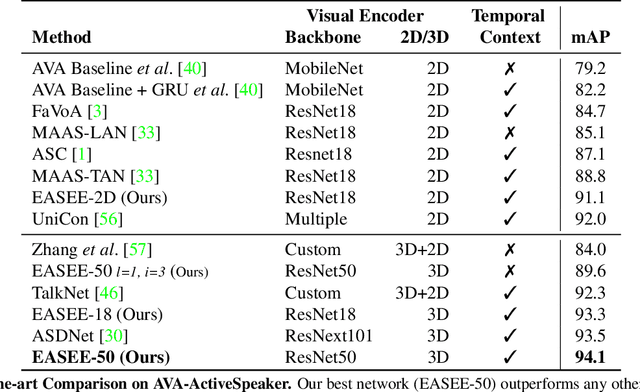
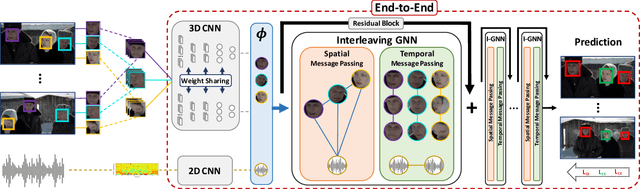

Recent advances in the Active Speaker Detection (ASD) problem build upon a two-stage process: feature extraction and spatio-temporal context aggregation. In this paper, we propose an end-to-end ASD workflow where feature learning and contextual predictions are jointly learned. Our end-to-end trainable network simultaneously learns multi-modal embeddings and aggregates spatio-temporal context. This results in more suitable feature representations and improved performance in the ASD task. We also introduce interleaved graph neural network (iGNN) blocks, which split the message passing according to the main sources of context in the ASD problem. Experiments show that the aggregated features from the iGNN blocks are more suitable for ASD, resulting in state-of-the art performance. Finally, we design a weakly-supervised strategy, which demonstrates that the ASD problem can also be approached by utilizing audiovisual data but relying exclusively on audio annotations. We achieve this by modelling the direct relationship between the audio signal and the possible sound sources (speakers), as well as introducing a contrastive loss.
APES: Audiovisual Person Search in Untrimmed Video
Jun 03, 2021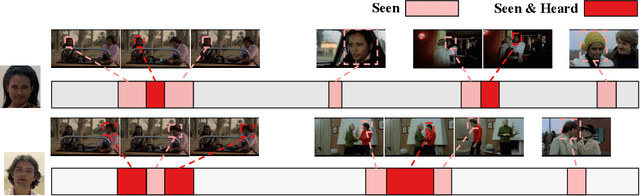
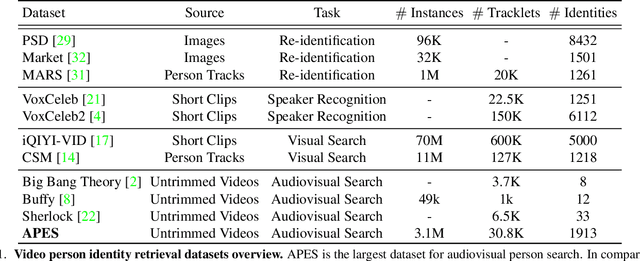


Humans are arguably one of the most important subjects in video streams, many real-world applications such as video summarization or video editing workflows often require the automatic search and retrieval of a person of interest. Despite tremendous efforts in the person reidentification and retrieval domains, few works have developed audiovisual search strategies. In this paper, we present the Audiovisual Person Search dataset (APES), a new dataset composed of untrimmed videos whose audio (voices) and visual (faces) streams are densely annotated. APES contains over 1.9K identities labeled along 36 hours of video, making it the largest dataset available for untrimmed audiovisual person search. A key property of APES is that it includes dense temporal annotations that link faces to speech segments of the same identity. To showcase the potential of our new dataset, we propose an audiovisual baseline and benchmark for person retrieval. Our study shows that modeling audiovisual cues benefits the recognition of people's identities. To enable reproducibility and promote future research, the dataset annotations and baseline code are available at: https://github.com/fuankarion/audiovisual-person-search
Active Speakers in Context
May 20, 2020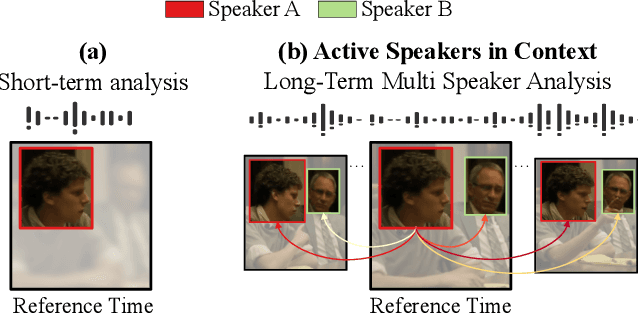
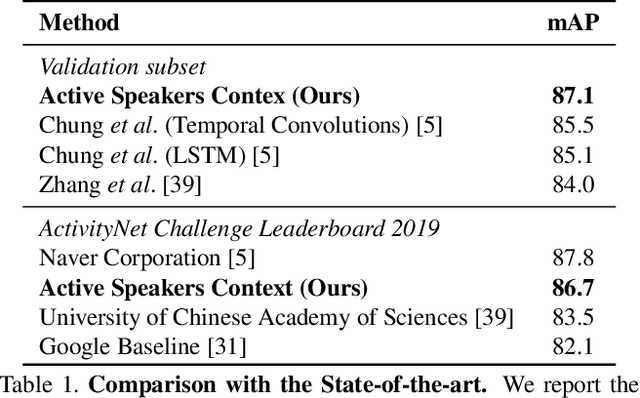
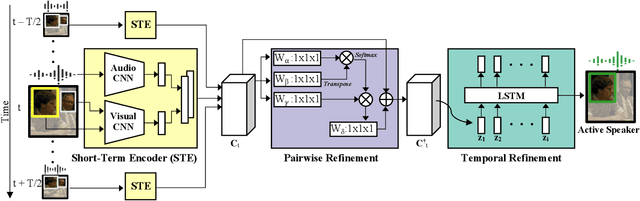

Current methods for active speak er detection focus on modeling short-term audiovisual information from a single speaker. Although this strategy can be enough for addressing single-speaker scenarios, it prevents accurate detection when the task is to identify who of many candidate speakers are talking. This paper introduces the Active Speaker Context, a novel representation that models relationships between multiple speakers over long time horizons. Our Active Speaker Context is designed to learn pairwise and temporal relations from an structured ensemble of audio-visual observations. Our experiments show that a structured feature ensemble already benefits the active speaker detection performance. Moreover, we find that the proposed Active Speaker Context improves the state-of-the-art on the AVA-ActiveSpeaker dataset achieving a mAP of 87.1%. We present ablation studies that verify that this result is a direct consequence of our long-term multi-speaker analysis.
MAIN: Multi-Attention Instance Network for Video Segmentation
Apr 11, 2019



Instance-level video segmentation requires a solid integration of spatial and temporal information. However, current methods rely mostly on domain-specific information (online learning) to produce accurate instance-level segmentations. We propose a novel approach that relies exclusively on the integration of generic spatio-temporal attention cues. Our strategy, named Multi-Attention Instance Network (MAIN), overcomes challenging segmentation scenarios over arbitrary videos without modelling sequence- or instance-specific knowledge. We design MAIN to segment multiple instances in a single forward pass, and optimize it with a novel loss function that favors class agnostic predictions and assigns instance-specific penalties. We achieve state-of-the-art performance on the challenging Youtube-VOS dataset and benchmark, improving the unseen Jaccard and F-Metric by 6.8% and 12.7% respectively, while operating at real-time (30.3 FPS).