 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Assessment of Adversarial Severity
Paper and Code
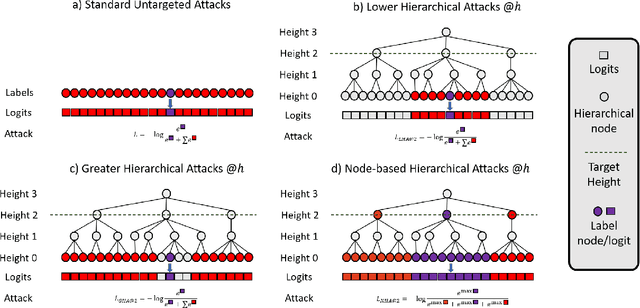


Adversarial Robustness is a growing field that evidences the brittleness of neural networks. Although the literature on adversarial robustness is vast, a dimension is missing in these studies: assessing how severe the mistakes are. We call this notion "Adversarial Severity" since it quantifies the downstream impact of adversarial corruptions by computing the semantic error between the misclassification and the proper label. We propose to study the effects of adversarial noise by measuring the Robustness and Severity into a large-scale dataset: iNaturalist-H. Our contributions are: (i) we introduce novel Hierarchical Attacks that harness the rich structured space of labels to create adversarial examples. (ii) These attacks allow us to benchmark the Adversarial Robustness and Severity of classification models. (iii) We enhance the traditional adversarial training with a simple yet effective Hierarchical Curriculum Training to learn these nodes gradually within the hierarchical tree. We perform extensive experiments showing that hierarchical defenses allow deep models to boost the adversarial Robustness by 1.85% and reduce the severity of all attacks by 0.17, on average.