 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Faster and More Compact Foundation Models for Molecular Property Prediction
Apr 28, 2025Advancements in machine learning for molecular property prediction have improved accuracy but at the expense of higher computational cost and longer training times. Recently, the Joint Multi-domain Pre-training (JMP) foundation model has demonstrated strong performance across various downstream tasks with reduced training time over previous models. Despite JMP's advantages, fine-tuning it on molecular datasets ranging from small-scale to large-scale requires considerable time and computational resources. In this work, we investigate strategies to enhance efficiency by reducing model size while preserving performance. To better understand the model's efficiency, we analyze the layer contributions of JMP and find that later interaction blocks provide diminishing returns, suggesting an opportunity for model compression. We explore block reduction strategies by pruning the pre-trained model and evaluating its impact on efficiency and accuracy during fine-tuning. Our analysis reveals that removing two interaction blocks results in a minimal performance drop, reducing the model size by 32% while increasing inference throughput by 1.3x. These results suggest that JMP-L is over-parameterized and that a smaller, more efficient variant can achieve comparable performance with lower computational cost. Our study provides insights for developing lighter, faster, and more scalable foundation models for molecular and materials discovery. The code is publicly available at: https://github.com/Yasir-Ghunaim/efficient-jmp.
EAGLE: Enhanced Visual Grounding Minimizes Hallucinations in Instructional Multimodal Models
Jan 06, 2025Large language models and vision transformers have demonstrated impressive zero-shot capabilities, enabling significant transferability in downstream tasks. The fusion of these models has resulted in multi-modal architectures with enhanced instructional capabilities. Despite incorporating vast image and language pre-training, these multi-modal architectures often generate responses that deviate from the ground truth in the image data. These failure cases are known as hallucinations. Current methods for mitigating hallucinations generally focus on regularizing the language component, improving the fusion module, or ensembling multiple visual encoders to improve visual representation. In this paper, we address the hallucination issue by directly enhancing the capabilities of the visual component. Our approach, named EAGLE, is fully agnostic to the LLM or fusion module and works as a post-pretraining approach that improves the grounding and language alignment of the visual encoder. We show that a straightforward reformulation of the original contrastive pre-training task results in an improved visual encoder that can be incorporated into the instructional multi-modal architecture without additional instructional training. As a result, EAGLE achieves a significant reduction in hallucinations across multiple challenging benchmarks and tasks.
Deep Learning at the Intersection: Certified Robustness as a Tool for 3D Vision
Aug 23, 2024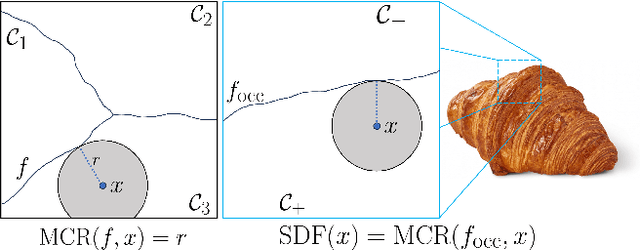
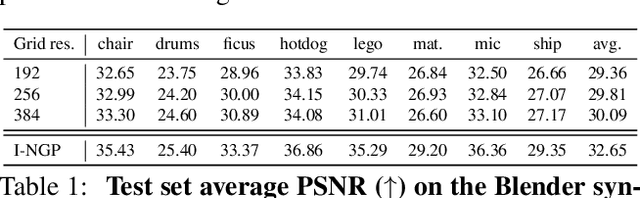

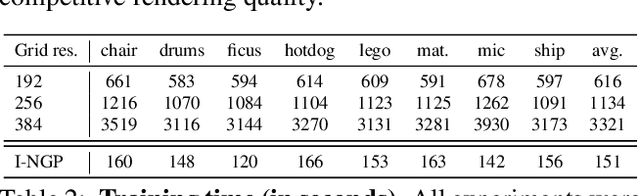
This paper presents preliminary work on a novel connection between certified robustness in machine learning and the modeling of 3D objects. We highlight an intriguing link between the Maximal Certified Radius (MCR) of a classifier representing a space's occupancy and the space's Signed Distance Function (SDF). Leveraging this relationship, we propose to use the certification method of randomized smoothing (RS) to compute SDFs. Since RS' high computational cost prevents its practical usage as a way to compute SDFs, we propose an algorithm to efficiently run RS in low-dimensional applications, such as 3D space, by expressing RS' fundamental operations as Gaussian smoothing on pre-computed voxel grids. Our approach offers an innovative and practical tool to compute SDFs, validated through proof-of-concept experiments in novel view synthesis. This paper bridges two previously disparate areas of machine learning, opening new avenues for further exploration and potential cross-domain advancements.
FedMedICL: Towards Holistic Evaluation of Distribution Shifts in Federated Medical Imaging
Jul 11, 2024



For medical imaging AI models to be clinically impactful, they must generalize. However, this goal is hindered by (i) diverse types of distribution shifts, such as temporal, demographic, and label shifts, and (ii) limited diversity in datasets that are siloed within single medical institutions. While these limitations have spurred interest in federated learning, current evaluation benchmarks fail to evaluate different shifts simultaneously. However, in real healthcare settings, multiple types of shifts co-exist, yet their impact on medical imaging performance remains unstudied. In response, we introduce FedMedICL, a unified framework and benchmark to holistically evaluate federated medical imaging challenges, simultaneously capturing label, demographic, and temporal distribution shifts. We comprehensively evaluate several popular methods on six diverse medical imaging datasets (totaling 550 GPU hours). Furthermore, we use FedMedICL to simulate COVID-19 propagation across hospitals and evaluate whether methods can adapt to pandemic changes in disease prevalence. We find that a simple batch balancing technique surpasses advanced methods in average performance across FedMedICL experiments. This finding questions the applicability of results from previous, narrow benchmarks in real-world medical settings.
Towards Interpretable Deep Local Learning with Successive Gradient Reconciliation
Jun 07, 2024



Relieving the reliance of neural network training on a global back-propagation (BP) has emerged as a notable research topic due to the biological implausibility and huge memory consumption caused by BP. Among the existing solutions, local learning optimizes gradient-isolated modules of a neural network with local errors and has been proved to be effective even on large-scale datasets. However, the reconciliation among local errors has never been investigated. In this paper, we first theoretically study non-greedy layer-wise training and show that the convergence cannot be assured when the local gradient in a module w.r.t. its input is not reconciled with the local gradient in the previous module w.r.t. its output. Inspired by the theoretical result, we further propose a local training strategy that successively regularizes the gradient reconciliation between neighboring modules without breaking gradient isolation or introducing any learnable parameters. Our method can be integrated into both local-BP and BP-free settings. In experiments, we achieve significant performance improvements compared to previous methods. Particularly, our method for CNN and Transformer architectures on ImageNet is able to attain a competitive performance with global BP, saving more than 40% memory consumption.
Combating Missing Modalities in Egocentric Videos at Test Time
Apr 23, 2024

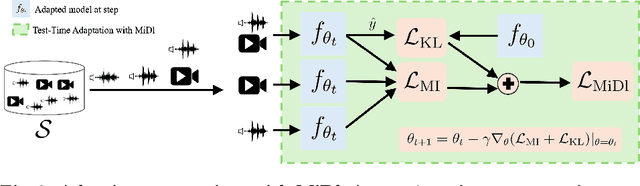

Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
Revisiting Test Time Adaptation under Online Evaluation
Apr 10, 2023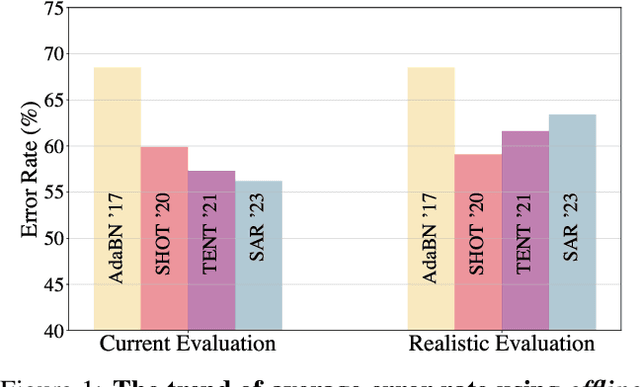

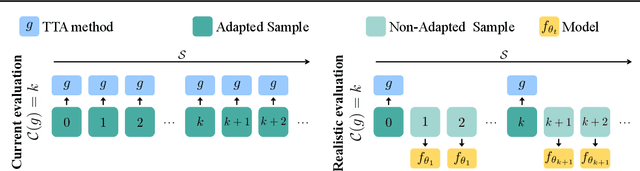
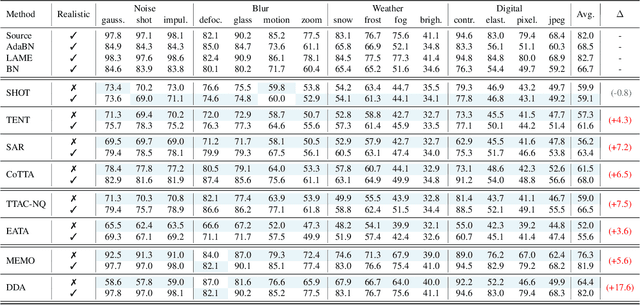
This paper proposes a novel online evaluation protocol for Test Time Adaptation (TTA) methods, which penalizes slower methods by providing them with fewer samples for adaptation. TTA methods leverage unlabeled data at test time to adapt to distribution shifts. Though many effective methods have been proposed, their impressive performance usually comes at the cost of significantly increased computation budgets. Current evaluation protocols overlook the effect of this extra computation cost, affecting their real-world applicability. To address this issue, we propose a more realistic evaluation protocol for TTA methods, where data is received in an online fashion from a constant-speed data stream, thereby accounting for the method's adaptation speed. We apply our proposed protocol to benchmark several TTA methods on multiple datasets and scenarios. Extensive experiments shows that, when accounting for inference speed, simple and fast approaches can outperform more sophisticated but slower methods. For example, SHOT from 2020 outperforms the state-of-the-art method SAR from 2023 under our online setting. Our online evaluation protocol emphasizes the need for developing TTA methods that are efficient and applicable in realistic settings.
Online Distillation with Continual Learning for Cyclic Domain Shifts
Apr 03, 2023



In recent years, online distillation has emerged as a powerful technique for adapting real-time deep neural networks on the fly using a slow, but accurate teacher model. However, a major challenge in online distillation is catastrophic forgetting when the domain shifts, which occurs when the student model is updated with data from the new domain and forgets previously learned knowledge. In this paper, we propose a solution to this issue by leveraging the power of continual learning methods to reduce the impact of domain shifts. Specifically, we integrate several state-of-the-art continual learning methods in the context of online distillation and demonstrate their effectiveness in reducing catastrophic forgetting. Furthermore, we provide a detailed analysis of our proposed solution in the case of cyclic domain shifts. Our experimental results demonstrate the efficacy of our approach in improving the robustness and accuracy of online distillation, with potential applications in domains such as video surveillance or autonomous driving. Overall, our work represents an important step forward in the field of online distillation and continual learning, with the potential to significantly impact real-world applications.
Real-Time Evaluation in Online Continual Learning: A New Paradigm
Feb 02, 2023



Current evaluations of Continual Learning (CL) methods typically assume that there is no constraint on training time and computation. This is an unrealistic assumption for any real-world setting, which motivates us to propose: a practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions. To do this, we evaluate current CL methods with respect to their computational costs. We hypothesize that under this new evaluation paradigm, computationally demanding CL approaches may perform poorly on streams with a varying distribution. We conduct extensive experiments on CLOC, a large-scale dataset containing 39 million time-stamped images with geolocation labels. We show that a simple baseline outperforms state-of-the-art CL methods under this evaluation, questioning the applicability of existing methods in realistic settings. In addition, we explore various CL components commonly used in the literature, including memory sampling strategies and regularization approaches. We find that all considered methods fail to be competitive against our simple baseline. This surprisingly suggests that the majority of existing CL literature is tailored to a specific class of streams that is not practical. We hope that the evaluation we provide will be the first step towards a paradigm shift to consider the computational cost in the development of online continual learning methods.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.