 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$β$-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language Alignment
Dec 14, 2025CLIP achieves strong zero-shot image-text retrieval by aligning global vision and text representations, yet it falls behind on fine-grained tasks even when fine-tuned on long, detailed captions. In this work, we propose $β$-CLIP, a multi-granular text-conditioned contrastive learning framework designed to achieve hierarchical alignment between multiple textual granularities-from full captions to sentences and phrases-and their corresponding visual regions. For each level of granularity, $β$-CLIP utilizes cross-attention to dynamically pool image patches, producing contextualized visual embeddings. To address the semantic overlap inherent in this hierarchy, we introduce the $β$-Contextualized Contrastive Alignment Loss ($β$-CAL). This objective parameterizes the trade-off between strict query-specific matching and relaxed intra-image contextualization, supporting both soft Cross-Entropy and hard Binary Cross-Entropy formulations. Through extensive experiments, we demonstrate that $β$-CLIP significantly improves dense alignment: achieving 91.8% T2I 92.3% I2T at R@1 on Urban1K and 30.9% on FG-OVD (Hard), setting state-of-the-art among methods trained without hard negatives. $β$-CLIP establishes a robust, adaptive baseline for dense vision-language correspondence. The code and models are released at https://github.com/fzohra/B-CLIP.
Unforgotten Safety: Preserving Safety Alignment of Large Language Models with Continual Learning
Dec 10, 2025The safety alignment of large language models (LLMs) is becoming increasingly important with their democratization. In this paper, we study the safety degradation that comes with adapting LLMs to new tasks. We attribute this safety compromise to catastrophic forgetting and frame the problem of preserving safety when fine-tuning as a continual learning (CL) problem. We consider the fine-tuning-as-a-service setup where the user uploads their data to a service provider to get a customized model that excels on the user's selected task. We adapt several CL approaches from the literature and systematically evaluate their ability to mitigate safety degradation. These include regularization-based, memory-based, and model merging approaches. We consider two scenarios, (1) benign user data and (2) poisoned user data. Our results demonstrate that CL approaches consistently achieve lower attack success rates than standard fine-tuning. Among these, DER outperforms both other CL methods and existing safety-preserving baselines while maintaining task utility. These findings generalize across three downstream tasks (GSM8K, SST2, Code) and three model families (LLaMA2-7B, Mistral-7B, Gemma-2B), establishing CL as a practical solution to preserve safety.
Beyond the Last Answer: Your Reasoning Trace Uncovers More than You Think
Apr 29, 2025Large Language Models (LLMs) leverage step-by-step reasoning to solve complex problems. Standard evaluation practice involves generating a complete reasoning trace and assessing the correctness of the final answer presented at its conclusion. In this paper, we challenge the reliance on the final answer by posing the following two questions: Does the final answer reliably represent the model's optimal conclusion? Can alternative reasoning paths yield different results? To answer these questions, we analyze intermediate reasoning steps, termed subthoughts, and propose a method based on our findings. Our approach involves segmenting a reasoning trace into sequential subthoughts based on linguistic cues. We start by prompting the model to generate continuations from the end-point of each intermediate subthought. We extract a potential answer from every completed continuation originating from different subthoughts. We find that aggregating these answers by selecting the most frequent one (the mode) often yields significantly higher accuracy compared to relying solely on the answer derived from the original complete trace. Analyzing the consistency among the answers derived from different subthoughts reveals characteristics that correlate with the model's confidence and correctness, suggesting potential for identifying less reliable answers. Our experiments across various LLMs and challenging mathematical reasoning datasets (AIME2024 and AIME2025) show consistent accuracy improvements, with gains reaching up to 13\% and 10\% respectively. Implementation is available at: https://github.com/hammoudhasan/SubthoughtReasoner.
Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration
May 27, 2024This study investigates whether Compressed-Language Models (CLMs), i.e. language models operating on raw byte streams from Compressed File Formats~(CFFs), can understand files compressed by CFFs. We focus on the JPEG format as a representative CFF, given its commonality and its representativeness of key concepts in compression, such as entropy coding and run-length encoding. We test if CLMs understand the JPEG format by probing their capabilities to perform along three axes: recognition of inherent file properties, handling of files with anomalies, and generation of new files. Our findings demonstrate that CLMs can effectively perform these tasks. These results suggest that CLMs can understand the semantics of compressed data when directly operating on the byte streams of files produced by CFFs. The possibility to directly operate on raw compressed files offers the promise to leverage some of their remarkable characteristics, such as their ubiquity, compactness, multi-modality and segment-nature.
X-VARS: Introducing Explainability in Football Refereeing with Multi-Modal Large Language Model
Apr 07, 2024The rapid advancement of artificial intelligence has led to significant improvements in automated decision-making. However, the increased performance of models often comes at the cost of explainability and transparency of their decision-making processes. In this paper, we investigate the capabilities of large language models to explain decisions, using football refereeing as a testing ground, given its decision complexity and subjectivity. We introduce the Explainable Video Assistant Referee System, X-VARS, a multi-modal large language model designed for understanding football videos from the point of view of a referee. X-VARS can perform a multitude of tasks, including video description, question answering, action recognition, and conducting meaningful conversations based on video content and in accordance with the Laws of the Game for football referees. We validate X-VARS on our novel dataset, SoccerNet-XFoul, which consists of more than 22k video-question-answer triplets annotated by over 70 experienced football referees. Our experiments and human study illustrate the impressive capabilities of X-VARS in interpreting complex football clips. Furthermore, we highlight the potential of X-VARS to reach human performance and support football referees in the future.
SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?
Feb 02, 2024We present SynthCLIP, a novel framework for training CLIP models with entirely synthetic text-image pairs, significantly departing from previous methods relying on real data. Leveraging recent text-to-image (TTI) generative networks and large language models (LLM), we are able to generate synthetic datasets of images and corresponding captions at any scale, with no human intervention. With training at scale, SynthCLIP achieves performance comparable to CLIP models trained on real datasets. We also introduce SynthCI-30M, a purely synthetic dataset comprising 30 million captioned images. Our code, trained models, and generated data are released at https://github.com/hammoudhasan/SynthCLIP
Revisiting Test Time Adaptation under Online Evaluation
Apr 10, 2023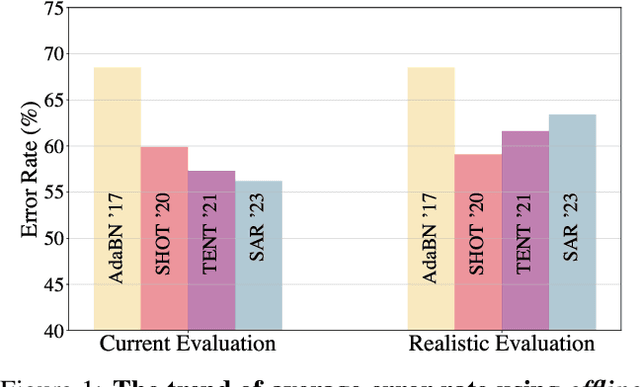

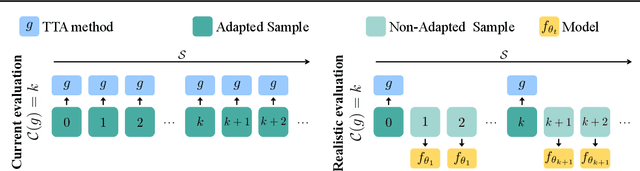
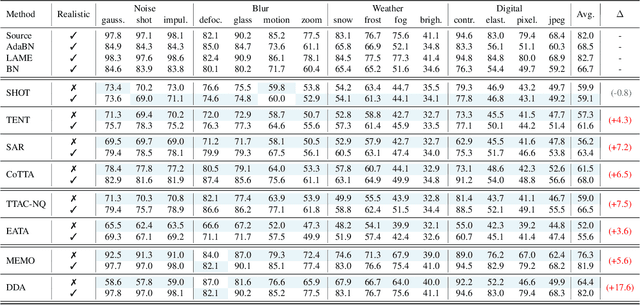
This paper proposes a novel online evaluation protocol for Test Time Adaptation (TTA) methods, which penalizes slower methods by providing them with fewer samples for adaptation. TTA methods leverage unlabeled data at test time to adapt to distribution shifts. Though many effective methods have been proposed, their impressive performance usually comes at the cost of significantly increased computation budgets. Current evaluation protocols overlook the effect of this extra computation cost, affecting their real-world applicability. To address this issue, we propose a more realistic evaluation protocol for TTA methods, where data is received in an online fashion from a constant-speed data stream, thereby accounting for the method's adaptation speed. We apply our proposed protocol to benchmark several TTA methods on multiple datasets and scenarios. Extensive experiments shows that, when accounting for inference speed, simple and fast approaches can outperform more sophisticated but slower methods. For example, SHOT from 2020 outperforms the state-of-the-art method SAR from 2023 under our online setting. Our online evaluation protocol emphasizes the need for developing TTA methods that are efficient and applicable in realistic settings.
CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
Mar 31, 2023The rapid advancement of conversational and chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming. This paper explores the potential of building scalable techniques to facilitate autonomous cooperation among communicative agents and provide insight into their "cognitive" processes. To address the challenges of achieving autonomous cooperation, we propose a novel communicative agent framework named role-playing. Our approach involves using inception prompting to guide chat agents toward task completion while maintaining consistency with human intentions. We showcase how role-playing can be used to generate conversational data for studying the behaviors and capabilities of chat agents, providing a valuable resource for investigating conversational language models. Our contributions include introducing a novel communicative agent framework, offering a scalable approach for studying the cooperative behaviors and capabilities of multi-agent systems, and open-sourcing our library to support research on communicative agents and beyond. The GitHub repository of this project is made publicly available on: https://github.com/lightaime/camel.
SALA: Soft Assignment Local Aggregation for 3D Semantic Segmentation
Dec 29, 2020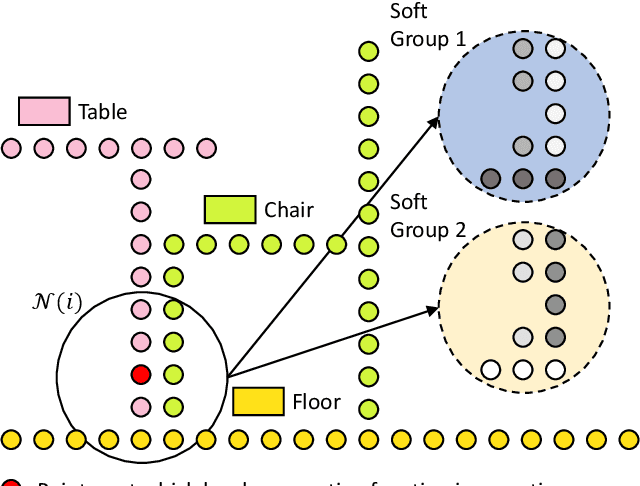
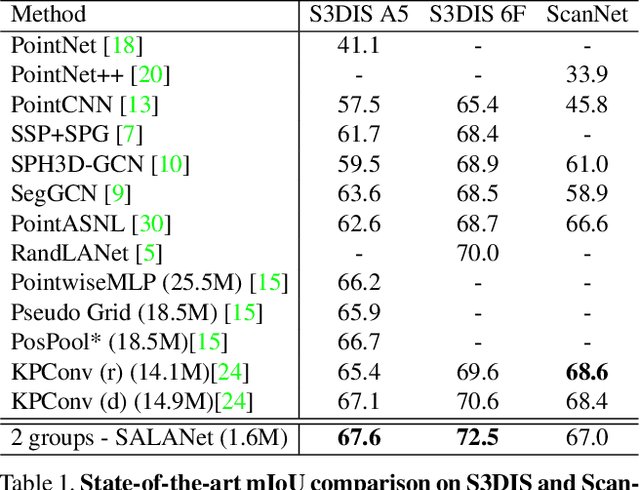
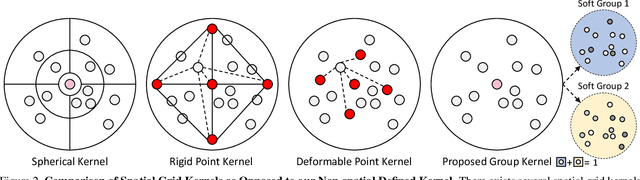
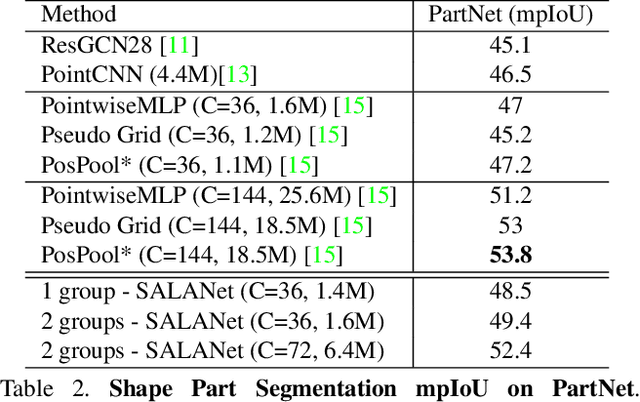
We introduce the idea of using learnable neighbor-to-grid soft assignment in grid-based aggregation functions for the task of 3D semantic segmentation. Previous methods in literature operate on a predefined geometric grid such as local volume partitions or irregular kernel points. These methods use geometric functions to assign local neighbors to their corresponding grid. Such geometric heuristics are potentially sub-optimal for the end task of semantic segmentation. Furthermore, they are applied uniformly throughout the depth of the network. A more general alternative would allow the network to learn its own neighbor-to-grid assignment function that best suits the end task. Since it is learnable, this mapping has the flexibility to be different per layer. This paper leverages learned neighbor-to-grid soft assignment to define an aggregation function that balances efficiency and performance. We demonstrate the efficacy of our method by reaching state-of-the-art (SOTA) performance on S3DIS with almost 10$\times$ less parameters than the current reigning method. We also demonstrate competitive performance on ScanNet and PartNet as compared with much larger SOTA models.