 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAM: Hierarchical Adapter Merging for Scalable Continual Learning
Sep 16, 2025



Continual learning is an essential capability of human cognition, yet it poses significant challenges for current deep learning models. The primary issue is that new knowledge can interfere with previously learned information, causing the model to forget earlier knowledge in favor of the new, a phenomenon known as catastrophic forgetting. Although large pre-trained models can partially mitigate forgetting by leveraging their existing knowledge and over-parameterization, they often struggle when confronted with novel data distributions. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, enable efficient adaptation to new knowledge. However, they still face challenges in scaling to dynamic learning scenarios and long sequences of tasks, as maintaining one adapter per task introduces complexity and increases the potential for interference. In this paper, we introduce Hierarchical Adapters Merging (HAM), a novel framework that dynamically combines adapters from different tasks during training. This approach enables HAM to scale effectively, allowing it to manage more tasks than competing baselines with improved efficiency. To achieve this, HAM maintains a fixed set of groups that hierarchically consolidate new adapters. For each task, HAM trains a low-rank adapter along with an importance scalar, then dynamically groups tasks based on adapter similarity. Within each group, adapters are pruned, scaled and merge, facilitating transfer learning between related tasks. Extensive experiments on three vision benchmarks show that HAM significantly outperforms state-of-the-art methods, particularly as the number of tasks increases.
Parameter-Efficient Continual Fine-Tuning: A Survey
Apr 18, 2025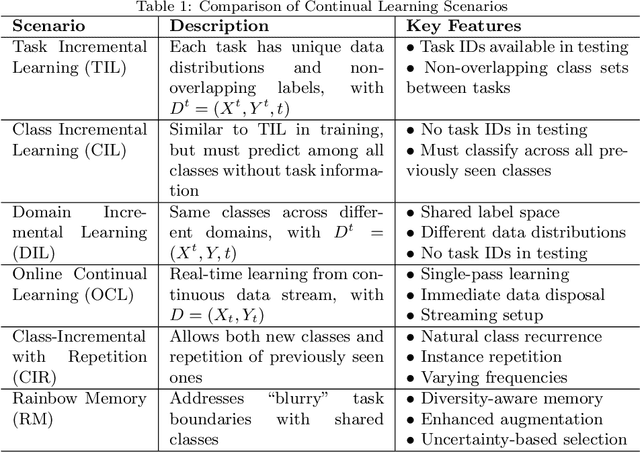

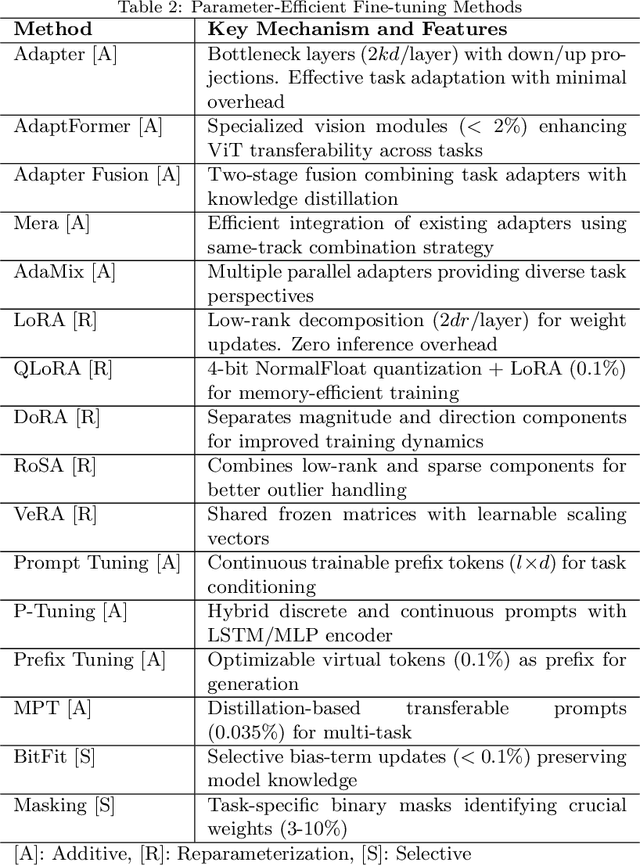
The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.
Data Distributional Properties As Inductive Bias for Systematic Generalization
Feb 27, 2025



Deep neural networks (DNNs) struggle at systematic generalization (SG). Several studies have evaluated the possibility to promote SG through the proposal of novel architectures, loss functions or training methodologies. Few studies, however, have focused on the role of training data properties in promoting SG. In this work, we investigate the impact of certain data distributional properties, as inductive biases for the SG ability of a multi-modal language model. To this end, we study three different properties. First, data diversity, instantiated as an increase in the possible values a latent property in the training distribution may take. Second, burstiness, where we probabilistically restrict the number of possible values of latent factors on particular inputs during training. Third, latent intervention, where a particular latent factor is altered randomly during training. We find that all three factors significantly enhance SG, with diversity contributing an 89\% absolute increase in accuracy in the most affected property. Through a series of experiments, we test various hypotheses to understand why these properties promote SG. Finally, we find that Normalized Mutual Information (NMI) between latent attributes in the training distribution is strongly predictive of out-of-distribution generalization. We find that a mechanism by which lower NMI induces SG is in the geometry of representations. In particular, we find that NMI induces more parallelism in neural representations (i.e., input features coded in parallel neural vectors) of the model, a property related to the capacity of reasoning by analogy.
Gradient-based inference of abstract task representations for generalization in neural networks
Jul 24, 2024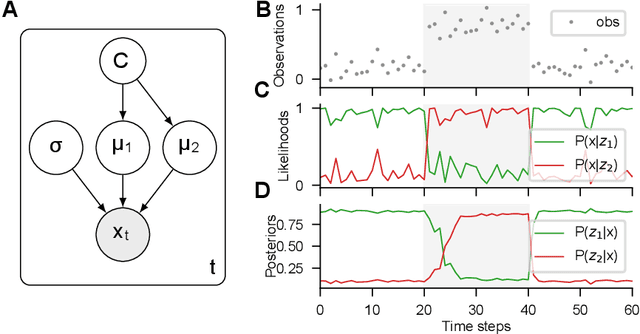



Humans and many animals show remarkably adaptive behavior and can respond differently to the same input depending on their internal goals. The brain not only represents the intermediate abstractions needed to perform a computation but also actively maintains a representation of the computation itself (task abstraction). Such separation of the computation and its abstraction is associated with faster learning, flexible decision-making, and broad generalization capacity. We investigate if such benefits might extend to neural networks trained with task abstractions. For such benefits to emerge, one needs a task inference mechanism that possesses two crucial abilities: First, the ability to infer abstract task representations when no longer explicitly provided (task inference), and second, manipulate task representations to adapt to novel problems (task recomposition). To tackle this, we cast task inference as an optimization problem from a variational inference perspective and ground our approach in an expectation-maximization framework. We show that gradients backpropagated through a neural network to a task representation layer are an efficient heuristic to infer current task demands, a process we refer to as gradient-based inference (GBI). Further iterative optimization of the task representation layer allows for recomposing abstractions to adapt to novel situations. Using a toy example, a novel image classifier, and a language model, we demonstrate that GBI provides higher learning efficiency and generalization to novel tasks and limits forgetting. Moreover, we show that GBI has unique advantages such as preserving information for uncertainty estimation and detecting out-of-distribution samples.
Continually Learn to Map Visual Concepts to Large Language Models in Resource-constrained Environments
Jul 11, 2024



Learning continually from a stream of non-i.i.d. data is an open challenge in deep learning, even more so when working in resource-constrained environments such as embedded devices. Visual models that are continually updated through supervised learning are often prone to overfitting, catastrophic forgetting, and biased representations. On the other hand, large language models contain knowledge about multiple concepts and their relations, which can foster a more robust, informed and coherent learning process. This work proposes Continual Visual Mapping (CVM), an approach that continually ground vision representations to a knowledge space extracted from a fixed Language model. Specifically, CVM continually trains a small and efficient visual model to map its representations into a conceptual space established by a fixed Large Language Model. Due to their smaller nature, CVM can be used when directly adapting large visual pre-trained models is unfeasible due to computational or data constraints. CVM overcome state-of-the-art continual learning methods on five benchmarks and offers a promising avenue for addressing generalization capabilities in continual learning, even in computationally constrained devices.
Adaptive Hyperparameter Optimization for Continual Learning Scenarios
Mar 09, 2024



Hyperparameter selection in continual learning scenarios is a challenging and underexplored aspect, especially in practical non-stationary environments. Traditional approaches, such as grid searches with held-out validation data from all tasks, are unrealistic for building accurate lifelong learning systems. This paper aims to explore the role of hyperparameter selection in continual learning and the necessity of continually and automatically tuning them according to the complexity of the task at hand. Hence, we propose leveraging the nature of sequence task learning to improve Hyperparameter Optimization efficiency. By using the functional analysis of variance-based techniques, we identify the most crucial hyperparameters that have an impact on performance. We demonstrate empirically that this approach, agnostic to continual scenarios and strategies, allows us to speed up hyperparameters optimization continually across tasks and exhibit robustness even in the face of varying sequential task orders. We believe that our findings can contribute to the advancement of continual learning methodologies towards more efficient, robust and adaptable models for real-world applications.
In-context Interference in Chat-based Large Language Models
Sep 22, 2023
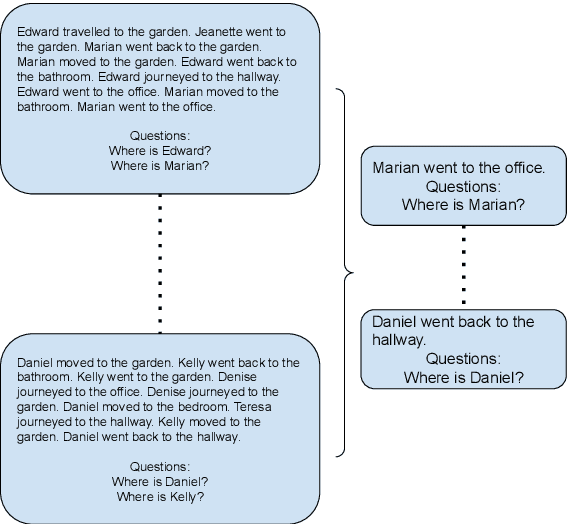
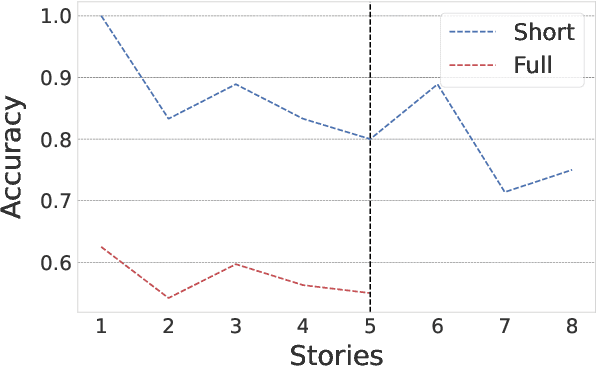
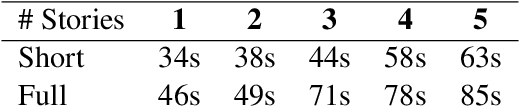
Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 20, 2023



One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.
Continual Learning for Predictive Maintenance: Overview and Challenges
Jan 29, 2023



Machine learning techniques have become one of the main propellers for solving many engineering problems effectively and efficiently. In Predictive Maintenance, for instance, Data-Driven methods have been used to improve predictions of when maintenance is needed on different machines and operative contexts. However, one of the limitations of these methods is that they are trained on a fixed distribution that does not change over time, which seldom happens in real-world applications. When internal or external factors alter the data distribution, the model performance may decrease or even fail unpredictably, resulting in severe consequences for machine maintenance. Continual Learning methods propose ways of adapting prediction models and incorporating new knowledge after deployment. The main objective of these methods is to avoid the plasticity-stability dilemma by updating the parametric model while not forgetting previously learned tasks. In this work, we present the current state of the art in applying Continual Learning to Predictive Maintenance, with an extensive review of both disciplines. We first introduce the two research themes independently, then discuss the current intersection of Continual Learning and Predictive Maintenance. Finally, we discuss the main research directions and conclusions.