 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Distributional Properties As Inductive Bias for Systematic Generalization
Feb 27, 2025



Deep neural networks (DNNs) struggle at systematic generalization (SG). Several studies have evaluated the possibility to promote SG through the proposal of novel architectures, loss functions or training methodologies. Few studies, however, have focused on the role of training data properties in promoting SG. In this work, we investigate the impact of certain data distributional properties, as inductive biases for the SG ability of a multi-modal language model. To this end, we study three different properties. First, data diversity, instantiated as an increase in the possible values a latent property in the training distribution may take. Second, burstiness, where we probabilistically restrict the number of possible values of latent factors on particular inputs during training. Third, latent intervention, where a particular latent factor is altered randomly during training. We find that all three factors significantly enhance SG, with diversity contributing an 89\% absolute increase in accuracy in the most affected property. Through a series of experiments, we test various hypotheses to understand why these properties promote SG. Finally, we find that Normalized Mutual Information (NMI) between latent attributes in the training distribution is strongly predictive of out-of-distribution generalization. We find that a mechanism by which lower NMI induces SG is in the geometry of representations. In particular, we find that NMI induces more parallelism in neural representations (i.e., input features coded in parallel neural vectors) of the model, a property related to the capacity of reasoning by analogy.
Gradient-based inference of abstract task representations for generalization in neural networks
Jul 24, 2024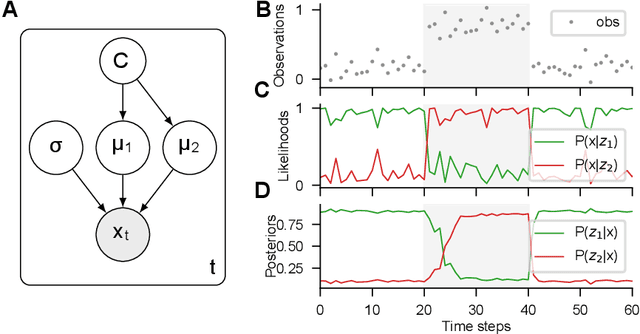



Humans and many animals show remarkably adaptive behavior and can respond differently to the same input depending on their internal goals. The brain not only represents the intermediate abstractions needed to perform a computation but also actively maintains a representation of the computation itself (task abstraction). Such separation of the computation and its abstraction is associated with faster learning, flexible decision-making, and broad generalization capacity. We investigate if such benefits might extend to neural networks trained with task abstractions. For such benefits to emerge, one needs a task inference mechanism that possesses two crucial abilities: First, the ability to infer abstract task representations when no longer explicitly provided (task inference), and second, manipulate task representations to adapt to novel problems (task recomposition). To tackle this, we cast task inference as an optimization problem from a variational inference perspective and ground our approach in an expectation-maximization framework. We show that gradients backpropagated through a neural network to a task representation layer are an efficient heuristic to infer current task demands, a process we refer to as gradient-based inference (GBI). Further iterative optimization of the task representation layer allows for recomposing abstractions to adapt to novel situations. Using a toy example, a novel image classifier, and a language model, we demonstrate that GBI provides higher learning efficiency and generalization to novel tasks and limits forgetting. Moreover, we show that GBI has unique advantages such as preserving information for uncertainty estimation and detecting out-of-distribution samples.
DACT-BERT: Differentiable Adaptive Computation Time for an Efficient BERT Inference
Sep 24, 2021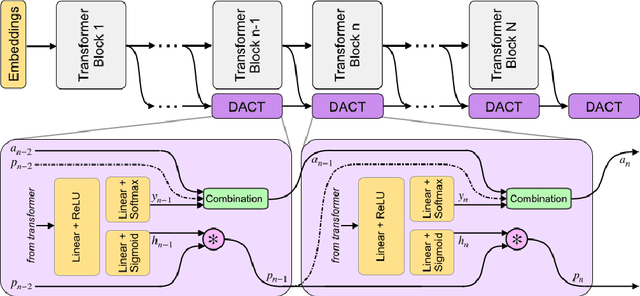
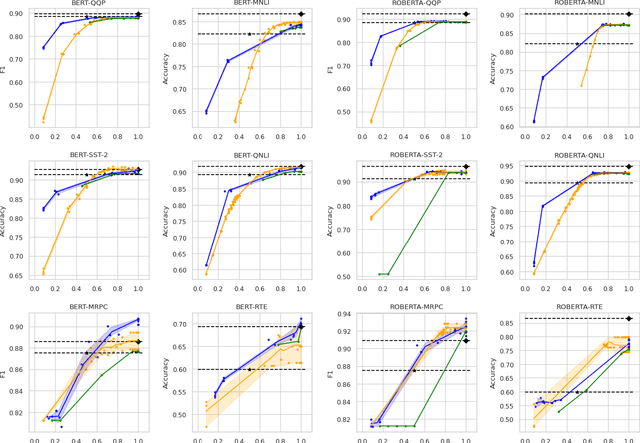
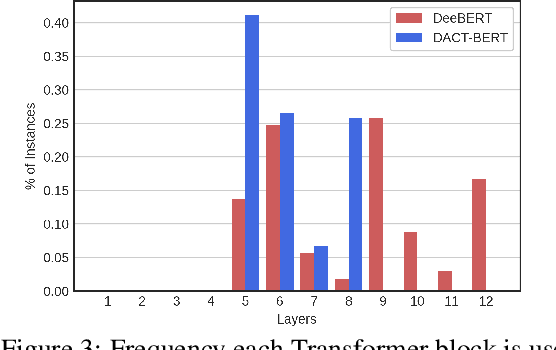
Large-scale pre-trained language models have shown remarkable results in diverse NLP applications. Unfortunately, these performance gains have been accompanied by a significant increase in computation time and model size, stressing the need to develop new or complementary strategies to increase the efficiency of these models. In this paper we propose DACT-BERT, a differentiable adaptive computation time strategy for BERT-like models. DACT-BERT adds an adaptive computational mechanism to BERT's regular processing pipeline, which controls the number of Transformer blocks that need to be executed at inference time. By doing this, the model learns to combine the most appropriate intermediate representations for the task at hand. Our experiments demonstrate that our approach, when compared to the baselines, excels on a reduced computational regime and is competitive in other less restrictive ones.