 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible task abstractions emerge in linear networks with fast and bounded units
Nov 06, 2024
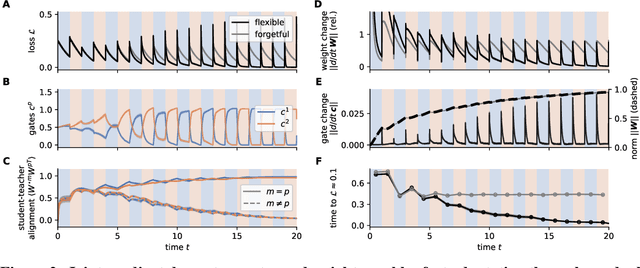


Animals survive in dynamic environments changing at arbitrary timescales, but such data distribution shifts are a challenge to neural networks. To adapt to change, neural systems may change a large number of parameters, which is a slow process involving forgetting past information. In contrast, animals leverage distribution changes to segment their stream of experience into tasks and associate them with internal task abstracts. Animals can then respond flexibly by selecting the appropriate task abstraction. However, how such flexible task abstractions may arise in neural systems remains unknown. Here, we analyze a linear gated network where the weights and gates are jointly optimized via gradient descent, but with neuron-like constraints on the gates including a faster timescale, nonnegativity, and bounded activity. We observe that the weights self-organize into modules specialized for tasks or sub-tasks encountered, while the gates layer forms unique representations that switch the appropriate weight modules (task abstractions). We analytically reduce the learning dynamics to an effective eigenspace, revealing a virtuous cycle: fast adapting gates drive weight specialization by protecting previous knowledge, while weight specialization in turn increases the update rate of the gating layer. Task switching in the gating layer accelerates as a function of curriculum block size and task training, mirroring key findings in cognitive neuroscience. We show that the discovered task abstractions support generalization through both task and subtask composition, and we extend our findings to a non-linear network switching between two tasks. Overall, our work offers a theory of cognitive flexibility in animals as arising from joint gradient descent on synaptic and neural gating in a neural network architecture.
Gradient-based inference of abstract task representations for generalization in neural networks
Jul 24, 2024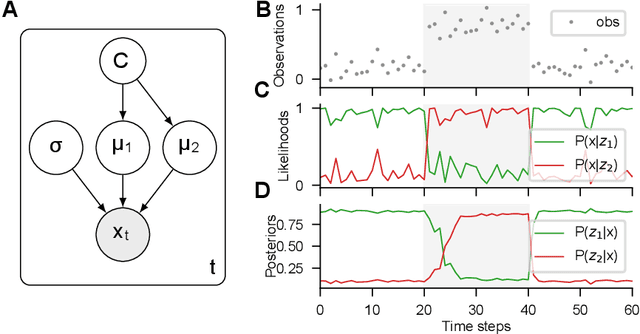



Humans and many animals show remarkably adaptive behavior and can respond differently to the same input depending on their internal goals. The brain not only represents the intermediate abstractions needed to perform a computation but also actively maintains a representation of the computation itself (task abstraction). Such separation of the computation and its abstraction is associated with faster learning, flexible decision-making, and broad generalization capacity. We investigate if such benefits might extend to neural networks trained with task abstractions. For such benefits to emerge, one needs a task inference mechanism that possesses two crucial abilities: First, the ability to infer abstract task representations when no longer explicitly provided (task inference), and second, manipulate task representations to adapt to novel problems (task recomposition). To tackle this, we cast task inference as an optimization problem from a variational inference perspective and ground our approach in an expectation-maximization framework. We show that gradients backpropagated through a neural network to a task representation layer are an efficient heuristic to infer current task demands, a process we refer to as gradient-based inference (GBI). Further iterative optimization of the task representation layer allows for recomposing abstractions to adapt to novel situations. Using a toy example, a novel image classifier, and a language model, we demonstrate that GBI provides higher learning efficiency and generalization to novel tasks and limits forgetting. Moreover, we show that GBI has unique advantages such as preserving information for uncertainty estimation and detecting out-of-distribution samples.
Thalamus: a brain-inspired algorithm for biologically-plausible continual learning and disentangled representations
May 24, 2022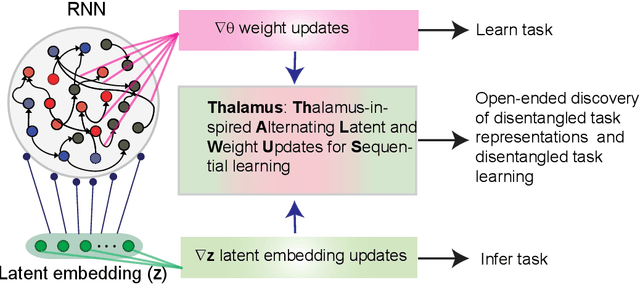

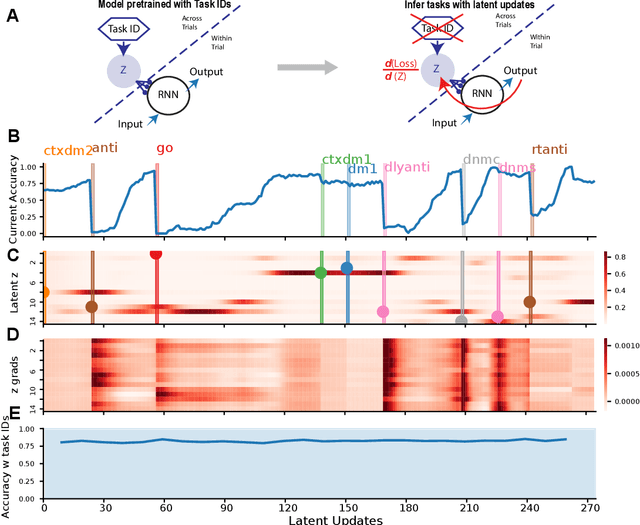

Animals thrive in a constantly changing environment and leverage the temporal structure to learn well-factorized causal representations. In contrast, traditional neural networks suffer from forgetting in changing environments and many methods have been proposed to limit forgetting with different trade-offs. Inspired by the brain thalamocortical circuit, we introduce a simple algorithm that uses optimization at inference time to generate internal representations of temporal context and to infer current context dynamically, allowing the agent to parse the stream of temporal experience into discrete events and organize learning about them. We show that a network trained on a series of tasks using traditional weight updates can infer tasks dynamically using gradient descent steps in the latent task embedding space (latent updates). We then alternate between the weight updates and the latent updates to arrive at Thalamus, a task-agnostic algorithm capable of discovering disentangled representations in a stream of unlabeled tasks using simple gradient descent. On a continual learning benchmark, it achieves competitive end average accuracy and demonstrates knowledge transfer. After learning a subset of tasks it can generalize to unseen tasks as they become reachable within the well-factorized latent space, through one-shot latent updates. The algorithm meets many of the desiderata of an ideal continually learning agent in open-ended environments, and its simplicity suggests fundamental computations in circuits with abundant feedback control loops such as the thalamocortical circuits in the brain.