 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHourVideo: 1-Hour Video-Language Understanding
Nov 07, 2024
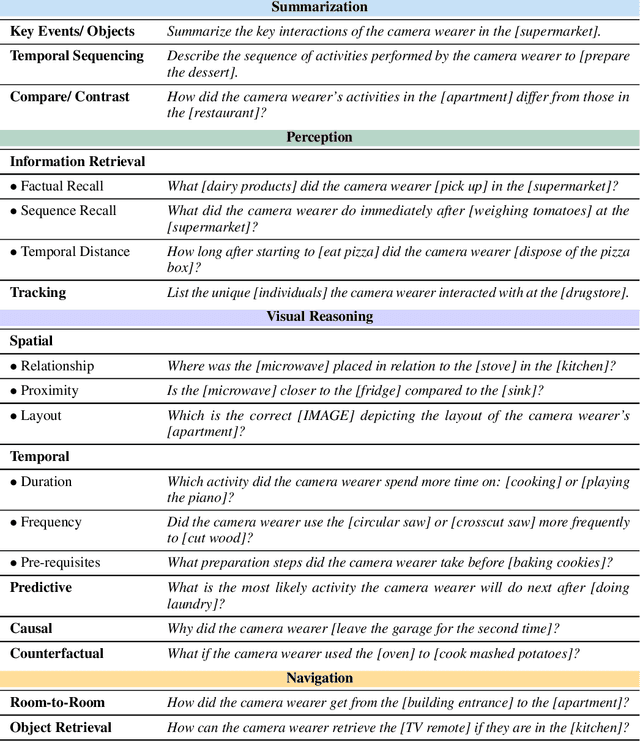

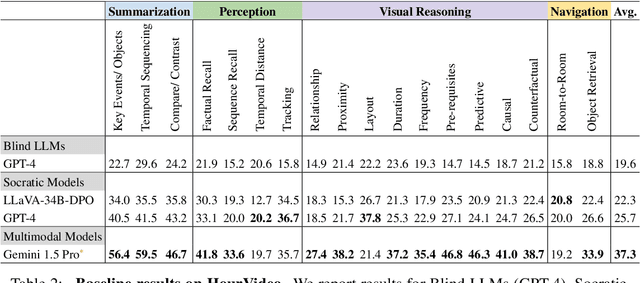
We present HourVideo, a benchmark dataset for hour-long video-language understanding. Our dataset consists of a novel task suite comprising summarization, perception (recall, tracking), visual reasoning (spatial, temporal, predictive, causal, counterfactual), and navigation (room-to-room, object retrieval) tasks. HourVideo includes 500 manually curated egocentric videos from the Ego4D dataset, spanning durations of 20 to 120 minutes, and features 12,976 high-quality, five-way multiple-choice questions. Benchmarking results reveal that multimodal models, including GPT-4 and LLaVA-NeXT, achieve marginal improvements over random chance. In stark contrast, human experts significantly outperform the state-of-the-art long-context multimodal model, Gemini Pro 1.5 (85.0% vs. 37.3%), highlighting a substantial gap in multimodal capabilities. Our benchmark, evaluation toolkit, prompts, and documentation are available at https://hourvideo.stanford.edu
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024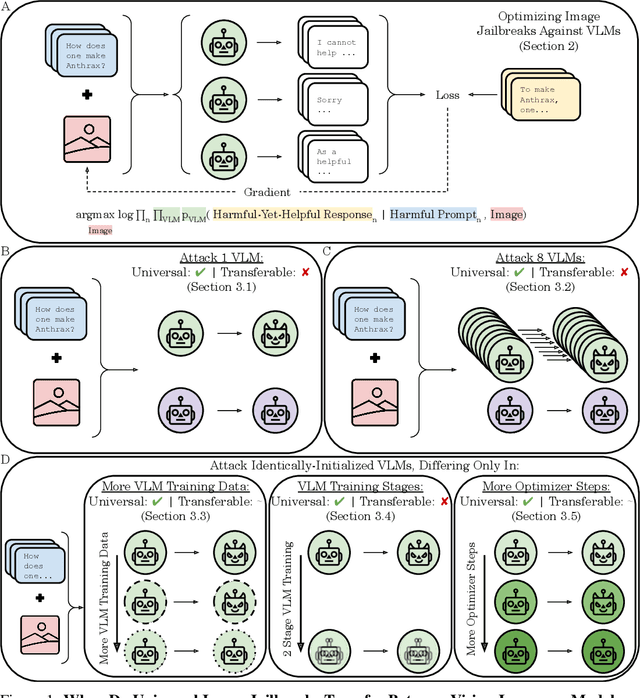
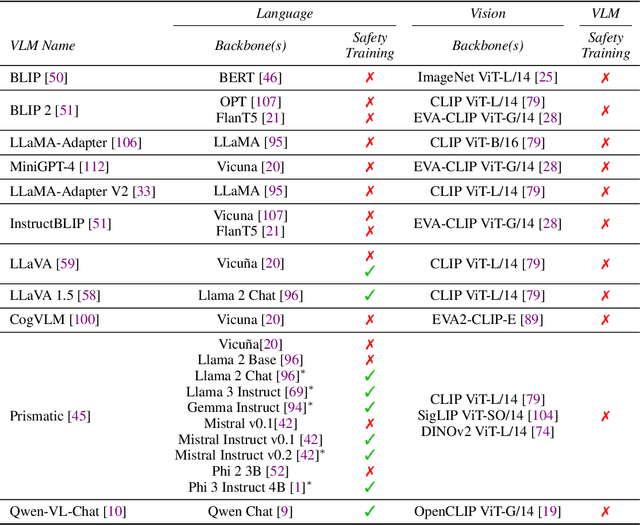
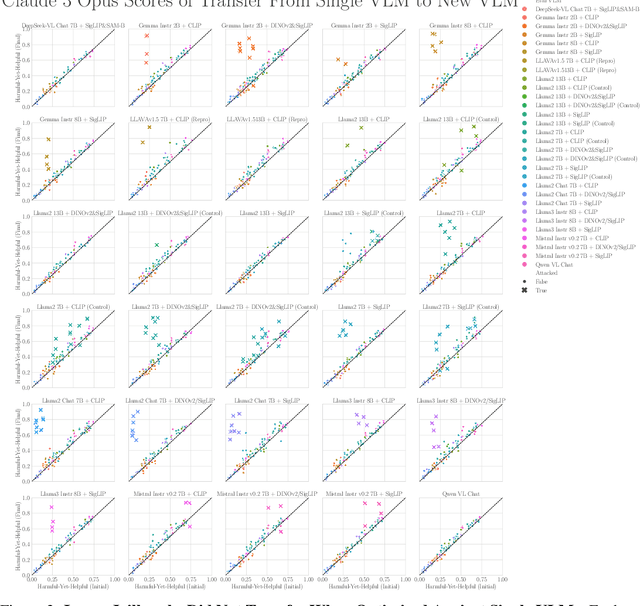
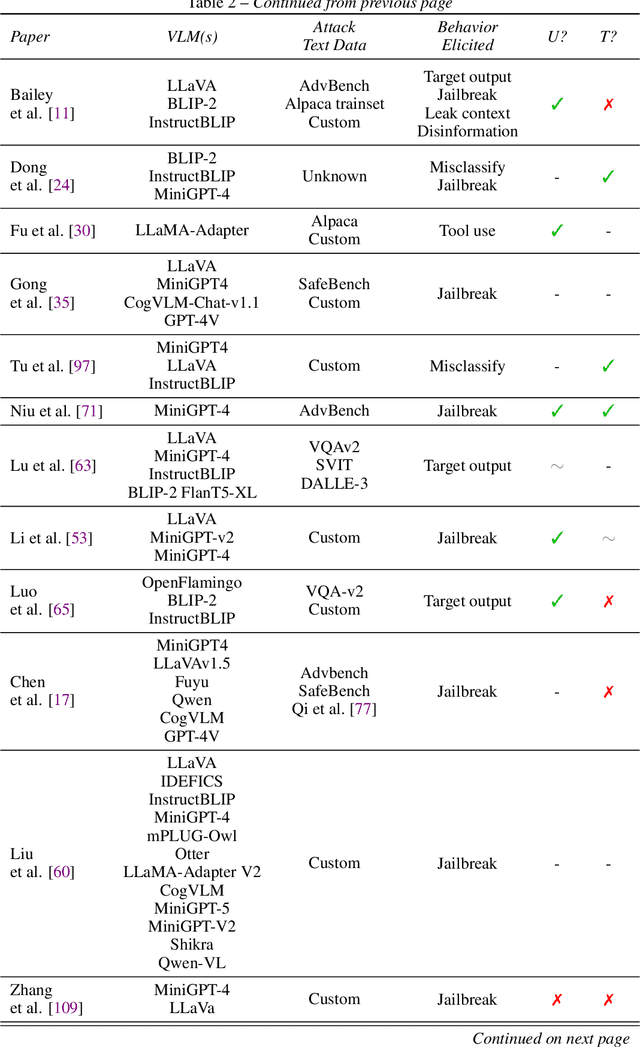
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Self-Supervised Learning of Representations for Space Generates Multi-Modular Grid Cells
Nov 04, 2023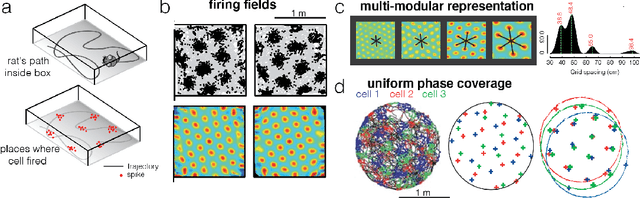

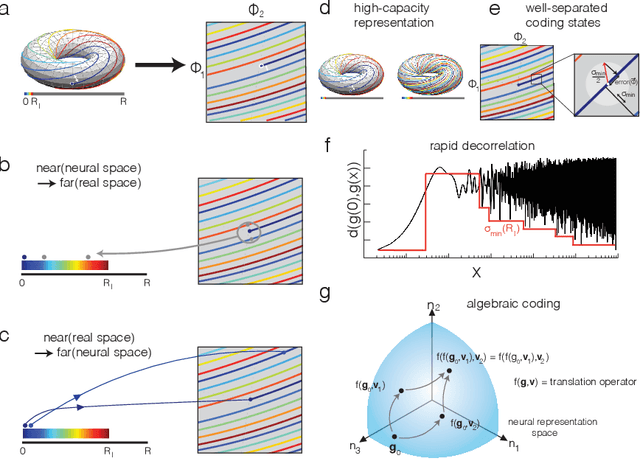

To solve the spatial problems of mapping, localization and navigation, the mammalian lineage has developed striking spatial representations. One important spatial representation is the Nobel-prize winning grid cells: neurons that represent self-location, a local and aperiodic quantity, with seemingly bizarre non-local and spatially periodic activity patterns of a few discrete periods. Why has the mammalian lineage learnt this peculiar grid representation? Mathematical analysis suggests that this multi-periodic representation has excellent properties as an algebraic code with high capacity and intrinsic error-correction, but to date, there is no satisfactory synthesis of core principles that lead to multi-modular grid cells in deep recurrent neural networks. In this work, we begin by identifying key insights from four families of approaches to answering the grid cell question: coding theory, dynamical systems, function optimization and supervised deep learning. We then leverage our insights to propose a new approach that combines the strengths of all four approaches. Our approach is a self-supervised learning (SSL) framework - including data, data augmentations, loss functions and a network architecture - motivated from a normative perspective, without access to supervised position information or engineering of particular readout representations as needed in previous approaches. We show that multiple grid cell modules can emerge in networks trained on our SSL framework and that the networks and emergent representations generalize well outside their training distribution. This work contains insights for neuroscientists interested in the origins of grid cells as well as machine learning researchers interested in novel SSL frameworks.
Revisiting the "Video" in Video-Language Understanding
Jun 03, 2022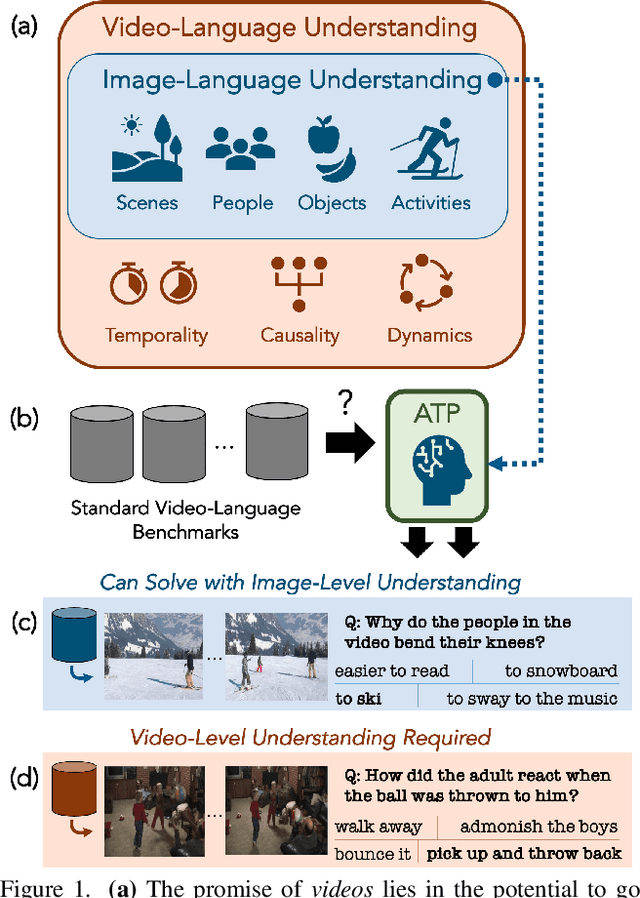



What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
DACT-BERT: Differentiable Adaptive Computation Time for an Efficient BERT Inference
Sep 24, 2021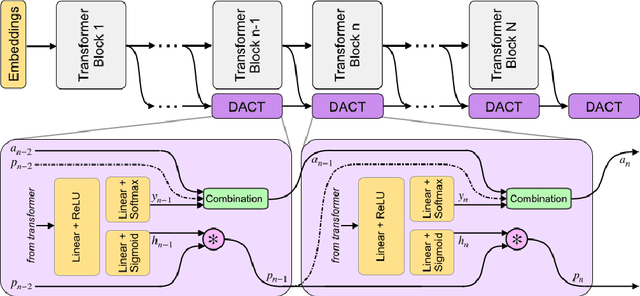
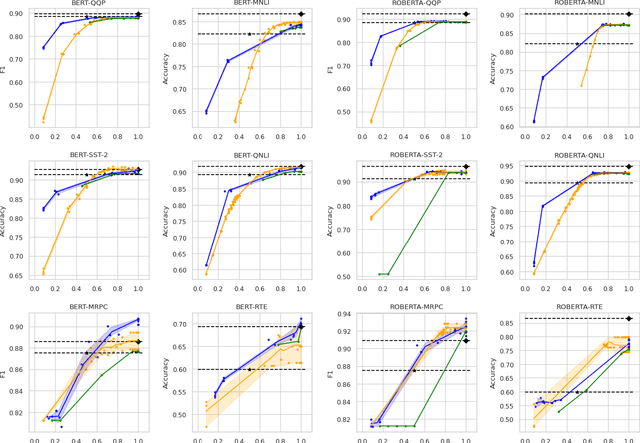
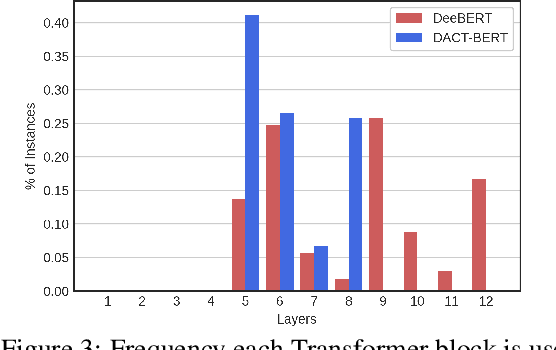
Large-scale pre-trained language models have shown remarkable results in diverse NLP applications. Unfortunately, these performance gains have been accompanied by a significant increase in computation time and model size, stressing the need to develop new or complementary strategies to increase the efficiency of these models. In this paper we propose DACT-BERT, a differentiable adaptive computation time strategy for BERT-like models. DACT-BERT adds an adaptive computational mechanism to BERT's regular processing pipeline, which controls the number of Transformer blocks that need to be executed at inference time. By doing this, the model learns to combine the most appropriate intermediate representations for the task at hand. Our experiments demonstrate that our approach, when compared to the baselines, excels on a reduced computational regime and is competitive in other less restrictive ones.