 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrassen Attention: Unlocking Compositional Abilities in Transformers Based on a New Lower Bound Method
Jan 31, 2025



We propose a novel method to evaluate the theoretical limits of Transformers, allowing us to prove the first lower bounds against one-layer softmax Transformers with infinite precision. We establish those bounds for three tasks that require advanced reasoning. The first task, Match3 (Sanford et al., 2023), requires looking at all triples of positions. The second and third tasks address compositionality-based reasoning: one is composition of functions (Peng et al., 2024) and the other is composition of binary relations. We formally prove the inability of one-layer softmax Transformers to solve any of these tasks. In an attempt to overcome these limitations, we introduce Strassen attention and prove that with this mechanism a one-layer Transformer can in principle solve all these tasks. We also show that it enjoys sub-cubic running-time complexity, making it more scalable than similar previously proposed mechanisms, such as higher-order attention (Sanford et al., 2023). To complement our theoretical findings, we experimentally studied Strassen attention and compared it against standard (Vaswani et al, 2017), higher-order attention (Sanford et al., 2023) and triangular attention (Bergen et al. 2021). Our results help to disentangle all these attention mechanisms, highlighting their strengths and limitations. In particular, Strassen attention outperforms standard attention significantly on all the tasks. Altogether, understanding the theoretical limitations can guide research towards scalable attention mechanisms that improve the reasoning abilities of Transformers.
Scrapping The Web For Early Wildfire Detection
Feb 08, 2024
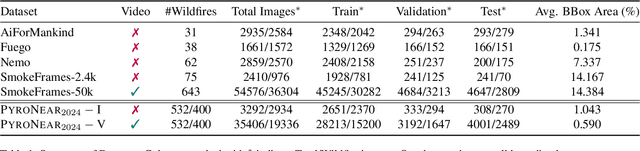

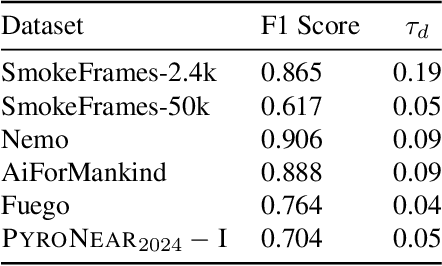
Early wildfire detection is of the utmost importance to enable rapid response efforts, and thus minimize the negative impacts of wildfire spreads. To this end, we present \Pyro, a web-scraping-based dataset composed of videos of wildfires from a network of cameras that were enhanced with manual bounding-box-level annotations. Our dataset was filtered based on a strategy to improve the quality and diversity of the data, reducing the final data to a set of 10,000 images. We ran experiments using a state-of-the-art object detection model and found out that the proposed dataset is challenging and its use in concordance with other public dataset helps to reach higher results overall. We will make our code and data publicly available.
Deep Natural Language Feature Learning for Interpretable Prediction
Nov 09, 2023We propose a general method to break down a main complex task into a set of intermediary easier sub-tasks, which are formulated in natural language as binary questions related to the final target task. Our method allows for representing each example by a vector consisting of the answers to these questions. We call this representation Natural Language Learned Features (NLLF). NLLF is generated by a small transformer language model (e.g., BERT) that has been trained in a Natural Language Inference (NLI) fashion, using weak labels automatically obtained from a Large Language Model (LLM). We show that the LLM normally struggles for the main task using in-context learning, but can handle these easiest subtasks and produce useful weak labels to train a BERT. The NLI-like training of the BERT allows for tackling zero-shot inference with any binary question, and not necessarily the ones seen during the training. We show that this NLLF vector not only helps to reach better performances by enhancing any classifier, but that it can be used as input of an easy-to-interpret machine learning model like a decision tree. This decision tree is interpretable but also reaches high performances, surpassing those of a pre-trained transformer in some cases.We have successfully applied this method to two completely different tasks: detecting incoherence in students' answers to open-ended mathematics exam questions, and screening abstracts for a systematic literature review of scientific papers on climate change and agroecology.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 20, 2023



One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.