 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuity and Isolation Lead to Doubts or Dilemmas in Large Language Models
May 15, 2025Understanding how Transformers work and how they process information is key to the theoretical and empirical advancement of these machines. In this work, we demonstrate the existence of two phenomena in Transformers, namely isolation and continuity. Both of these phenomena hinder Transformers to learn even simple pattern sequences. Isolation expresses that any learnable sequence must be isolated from another learnable sequence, and hence some sequences cannot be learned by a single Transformer at the same time. Continuity entails that an attractor basin forms around a learned sequence, such that any sequence falling in that basin will collapse towards the learned sequence. Here, we mathematically prove these phenomena emerge in all Transformers that use compact positional encoding, and design rigorous experiments, demonstrating that the theoretical limitations we shed light on occur on the practical scale.
Strassen Attention: Unlocking Compositional Abilities in Transformers Based on a New Lower Bound Method
Jan 31, 2025



We propose a novel method to evaluate the theoretical limits of Transformers, allowing us to prove the first lower bounds against one-layer softmax Transformers with infinite precision. We establish those bounds for three tasks that require advanced reasoning. The first task, Match3 (Sanford et al., 2023), requires looking at all triples of positions. The second and third tasks address compositionality-based reasoning: one is composition of functions (Peng et al., 2024) and the other is composition of binary relations. We formally prove the inability of one-layer softmax Transformers to solve any of these tasks. In an attempt to overcome these limitations, we introduce Strassen attention and prove that with this mechanism a one-layer Transformer can in principle solve all these tasks. We also show that it enjoys sub-cubic running-time complexity, making it more scalable than similar previously proposed mechanisms, such as higher-order attention (Sanford et al., 2023). To complement our theoretical findings, we experimentally studied Strassen attention and compared it against standard (Vaswani et al, 2017), higher-order attention (Sanford et al., 2023) and triangular attention (Bergen et al. 2021). Our results help to disentangle all these attention mechanisms, highlighting their strengths and limitations. In particular, Strassen attention outperforms standard attention significantly on all the tasks. Altogether, understanding the theoretical limitations can guide research towards scalable attention mechanisms that improve the reasoning abilities of Transformers.
On dimensionality of feature vectors in MPNNs
Feb 14, 2024We revisit the classical result of Morris et al.~(AAAI'19) that message-passing graphs neural networks (MPNNs) are equal in their distinguishing power to the Weisfeiler--Leman (WL) isomorphism test. Morris et al.~show their simulation result with ReLU activation function and $O(n)$-dimensional feature vectors, where $n$ is the number of nodes of the graph. By introducing randomness into the architecture, Aamand et al.~(NeurIPS'22) were able to improve this bound to $O(\log n)$-dimensional feature vectors, again for ReLU activation, although at the expense of guaranteeing perfect simulation only with high probability. Recently, Amir et al.~(NeurIPS'23) have shown that for any non-polynomial analytic activation function, it is enough to use just 1-dimensional feature vectors. In this paper, we give a simple proof of the result of Amit et al.~and provide an independent experimental validation of it.
Three iterations of $$-WL test distinguish non isometric clouds of $d$-dimensional points
Mar 28, 2023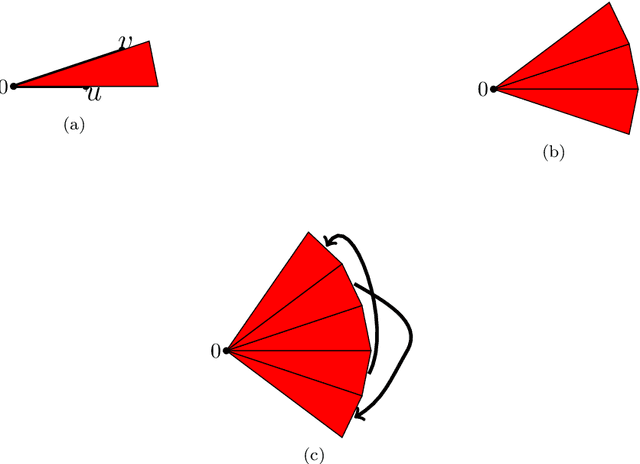
The Weisfeiler--Lehman (WL) test is a fundamental iterative algorithm for checking isomorphism of graphs. It has also been observed that it underlies the design of several graph neural network architectures, whose capabilities and performance can be understood in terms of the expressive power of this test. Motivated by recent developments in machine learning applications to datasets involving three-dimensional objects, we study when the WL test is {\em complete} for clouds of euclidean points represented by complete distance graphs, i.e., when it can distinguish, up to isometry, any arbitrary such cloud. Our main result states that the $(d-1)$-dimensional WL test is complete for point clouds in $d$-dimensional Euclidean space, for any $d\ge 2$, and that only three iterations of the test suffice. Our result is tight for $d = 2, 3$. We also observe that the $d$-dimensional WL test only requires one iteration to achieve completeness.
No Agreement Without Loss: Learning and Social Choice in Peer Review
Nov 03, 2022In peer review systems, reviewers are often asked to evaluate various features of submissions, such as technical quality or novelty. A score is given to each of the predefined features and based on these the reviewer has to provide an overall quantitative recommendation. However, reviewers differ in how much they value different features. It may be assumed that each reviewer has her own mapping from a set of criteria scores (score vectors) to a recommendation, and that different reviewers have different mappings in mind. Recently, Noothigattu, Shah and Procaccia introduced a novel framework for obtaining an aggregated mapping by means of Empirical Risk Minimization based on $L(p,q)$ loss functions, and studied its axiomatic properties in the sense of social choice theory. We provide a body of new results about this framework. On the one hand we study a trade-off between strategy-proofness and the ability of the method to properly capture agreements of the majority of reviewers. On the other hand, we show that dropping a certain unrealistic assumption makes the previously reported results to be no longer valid. Moreover, in the general case, strategy-proofness fails dramatically in the sense that a reviewer is able to make significant changes to the solution in her favor by arbitrarily small changes to their true beliefs. In particular, no approximate version of strategy-proofness is possible in this general setting since the method is not even continuous w.r.t. the data. Finally we propose a modified aggregation algorithm which is continuous and show that it has good axiomatic properties.