 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Method to Enhance Pre-trained Language Models with Speech Tokens for Classification
Dec 08, 2025This paper presents a simple method that allows to easily enhance textual pre-trained large language models with speech information, when fine-tuned for a specific classification task. A classical issue with the fusion of many embeddings from audio with text is the large length of the audio sequence compared to the text one. Our method benefits from an existing speech tokenizer trained for Audio Speech Recognition that output long sequences of tokens from a large vocabulary, making it difficult to integrate it at low cost in a large language model. By applying a simple lasso-based feature selection on multimodal Bag-of-Words representation, we retain only the most important audio tokens for the task, and adapt the language model to them with a self-supervised language modeling objective, before fine-tuning it on the downstream task. We show this helps to improve the performances compared to an unimodal model, to a bigger SpeechLM or to integrating audio via a learned representation. We show the effectiveness of our method on two recent Argumentative Fallacy Detection and Classification tasks where the use of audio was believed counterproductive, reaching state-of-the-art results. We also provide an in-depth analysis of the method, showing that even a random audio token selection helps enhancing the unimodal model. Our code is available [online](https://github.com/salocinc/EACL26SpeechTokFallacy/).
StandUp4AI: A New Multilingual Dataset for Humor Detection in Stand-up Comedy Videos
May 24, 2025Aiming towards improving current computational models of humor detection, we propose a new multimodal dataset of stand-up comedies, in seven languages: English, French, Spanish, Italian, Portuguese, Hungarian and Czech. Our dataset of more than 330 hours, is at the time of writing the biggest available for this type of task, and the most diverse. The whole dataset is automatically annotated in laughter (from the audience), and the subpart left for model validation is manually annotated. Contrary to contemporary approaches, we do not frame the task of humor detection as a binary sequence classification, but as word-level sequence labeling, in order to take into account all the context of the sequence and to capture the continuous joke tagging mechanism typically occurring in natural conversations. As par with unimodal baselines results, we propose a method for e propose a method to enhance the automatic laughter detection based on Audio Speech Recognition errors. Our code and data are available online: https://tinyurl.com/EMNLPHumourStandUpPublic
Fantastic Biases (What are They) and Where to Find Them
Nov 22, 2024Deep Learning models tend to learn correlations of patterns on huge datasets. The bigger these systems are, the more complex are the phenomena they can detect, and the more data they need for this. The use of Artificial Intelligence (AI) is becoming increasingly ubiquitous in our society, and its impact is growing everyday. The promises it holds strongly depend on their fair and universal use, such as access to information or education for all. In a world of inequalities, they can help to reach the most disadvantaged areas. However, such a universal systems must be able to represent society, without benefiting some at the expense of others. We must not reproduce the inequalities observed throughout the world, but educate these IAs to go beyond them. We have seen cases where these systems use gender, race, or even class information in ways that are not appropriate for resolving their tasks. Instead of real causal reasoning, they rely on spurious correlations, which is what we usually call a bias. In this paper, we first attempt to define what is a bias in general terms. It helps us to demystify the concept of bias, to understand why we can find them everywhere and why they are sometimes useful. Second, we focus over the notion of what is generally seen as negative bias, the one we want to avoid in machine learning, before presenting a general zoology containing the most common of these biases. We finally conclude by looking at classical methods to detect them, by means of specially crafted datasets of templates and specific algorithms, and also classical methods to mitigate them.
* Publication in Spanish in the Journal Bits de Ciencias: https://www.dcc.uchile.cl/media/bits/pdfs/bits26.2-sesgos-fantasticos.pdf
A Study of Nationality Bias in Names and Perplexity using Off-the-Shelf Affect-related Tweet Classifiers
Jul 01, 2024



In this paper, we apply a method to quantify biases associated with named entities from various countries. We create counterfactual examples with small perturbations on target-domain data instead of relying on templates or specific datasets for bias detection. On widely used classifiers for subjectivity analysis, including sentiment, emotion, hate speech, and offensive text using Twitter data, our results demonstrate positive biases related to the language spoken in a country across all classifiers studied. Notably, the presence of certain country names in a sentence can strongly influence predictions, up to a 23\% change in hate speech detection and up to a 60\% change in the prediction of negative emotions such as anger. We hypothesize that these biases stem from the training data of pre-trained language models (PLMs) and find correlations between affect predictions and PLMs likelihood in English and unknown languages like Basque and Maori, revealing distinct patterns with exacerbate correlations. Further, we followed these correlations in-between counterfactual examples from a same sentence to remove the syntactical component, uncovering interesting results suggesting the impact of the pre-training data was more important for English-speaking-country names. Our anonymized code is [https://anonymous.4open.science/r/biases_ppl-576B/README.md](available here).
Scrapping The Web For Early Wildfire Detection
Feb 08, 2024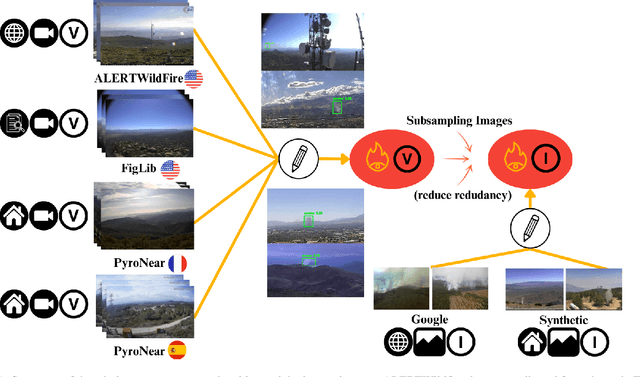
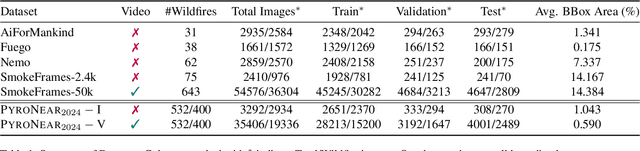

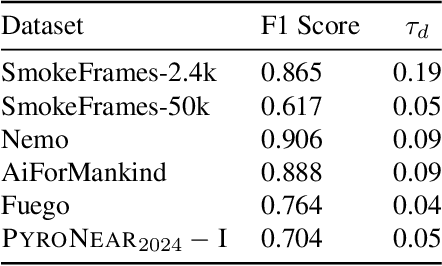
Early wildfire detection is of the utmost importance to enable rapid response efforts, and thus minimize the negative impacts of wildfire spreads. To this end, we present \Pyro, a web-scraping-based dataset composed of videos of wildfires from a network of cameras that were enhanced with manual bounding-box-level annotations. Our dataset was filtered based on a strategy to improve the quality and diversity of the data, reducing the final data to a set of 10,000 images. We ran experiments using a state-of-the-art object detection model and found out that the proposed dataset is challenging and its use in concordance with other public dataset helps to reach higher results overall. We will make our code and data publicly available.
Deep Natural Language Feature Learning for Interpretable Prediction
Nov 09, 2023We propose a general method to break down a main complex task into a set of intermediary easier sub-tasks, which are formulated in natural language as binary questions related to the final target task. Our method allows for representing each example by a vector consisting of the answers to these questions. We call this representation Natural Language Learned Features (NLLF). NLLF is generated by a small transformer language model (e.g., BERT) that has been trained in a Natural Language Inference (NLI) fashion, using weak labels automatically obtained from a Large Language Model (LLM). We show that the LLM normally struggles for the main task using in-context learning, but can handle these easiest subtasks and produce useful weak labels to train a BERT. The NLI-like training of the BERT allows for tackling zero-shot inference with any binary question, and not necessarily the ones seen during the training. We show that this NLLF vector not only helps to reach better performances by enhancing any classifier, but that it can be used as input of an easy-to-interpret machine learning model like a decision tree. This decision tree is interpretable but also reaches high performances, surpassing those of a pre-trained transformer in some cases.We have successfully applied this method to two completely different tasks: detecting incoherence in students' answers to open-ended mathematics exam questions, and screening abstracts for a systematic literature review of scientific papers on climate change and agroecology.
Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness
Sep 27, 2023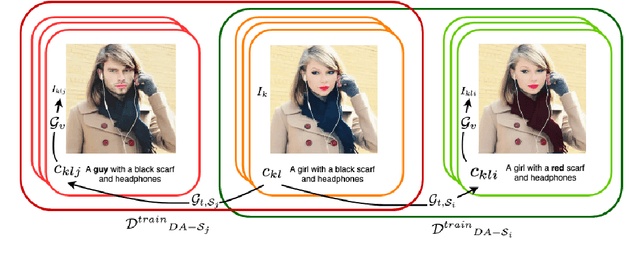
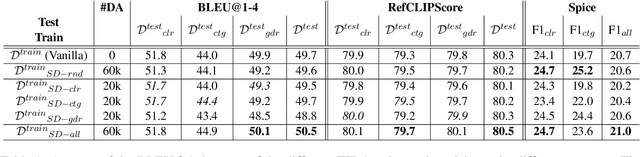
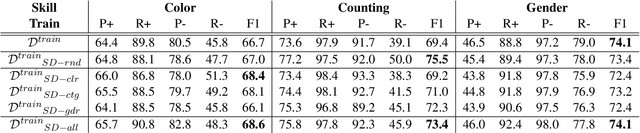
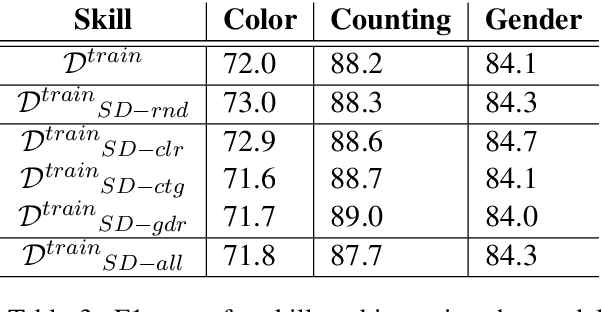
Artificial neural networks typically struggle in generalizing to out-of-context examples. One reason for this limitation is caused by having datasets that incorporate only partial information regarding the potential correlational structure of the world. In this work, we propose TIDA (Targeted Image-editing Data Augmentation), a targeted data augmentation method focused on improving models' human-like abilities (e.g., gender recognition) by filling the correlational structure gap using a text-to-image generative model. More specifically, TIDA identifies specific skills in captions describing images (e.g., the presence of a specific gender in the image), changes the caption (e.g., "woman" to "man"), and then uses a text-to-image model to edit the image in order to match the novel caption (e.g., uniquely changing a woman to a man while maintaining the context identical). Based on the Flickr30K benchmark, we show that, compared with the original data set, a TIDA-enhanced dataset related to gender, color, and counting abilities induces better performance in several image captioning metrics. Furthermore, on top of relying on the classical BLEU metric, we conduct a fine-grained analysis of the improvements of our models against the baseline in different ways. We compared text-to-image generative models and found different behaviors of the image captioning models in terms of encoding visual encoding and textual decoding.
Boosting Crop Classification by Hierarchically Fusing Satellite, Rotational, and Contextual Data
May 25, 2023Accurate in-season crop type classification is crucial for the crop production estimation and monitoring of agricultural parcels. However, the complexity of the plant growth patterns and their spatio-temporal variability present significant challenges. While current deep learning-based methods show promise in crop type classification from single- and multi-modal time series, most existing methods rely on a single modality, such as satellite optical remote sensing data or crop rotation patterns. We propose a novel approach to fuse multimodal information into a model for improved accuracy and robustness across multiple years and countries. The approach relies on three modalities used: remote sensing time series from Sentinel-2 and Landsat 8 observations, parcel crop rotation and local crop distribution. To evaluate our approach, we release a new annotated dataset of 7.4 million agricultural parcels in France and Netherlands. We associate each parcel with time-series of surface reflectance (Red and NIR) and biophysical variables (LAI, FAPAR). Additionally, we propose a new approach to automatically aggregate crop types into a hierarchical class structure for meaningful model evaluation and a novel data-augmentation technique for early-season classification. Performance of the multimodal approach was assessed at different aggregation level in the semantic domain spanning from 151 to 8 crop types or groups. It resulted in accuracy ranging from 91\% to 95\% for NL dataset and from 85\% to 89\% for FR dataset. Pre-training on a dataset improves domain adaptation between countries, allowing for cross-domain zero-shot learning, and robustness of the performances in a few-shot setting from France to Netherlands. Our proposed approach outperforms comparable methods by enabling learning methods to use the often overlooked spatio-temporal context of parcels, resulting in increased preci...
Multimodal Crop Type Classification Fusing Multi-Spectral Satellite Time Series with Farmers Crop Rotations and Local Crop Distribution
Aug 23, 2022
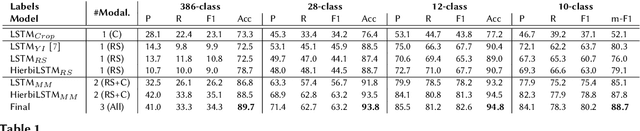

Accurate, detailed, and timely crop type mapping is a very valuable information for the institutions in order to create more accurate policies according to the needs of the citizens. In the last decade, the amount of available data dramatically increased, whether it can come from Remote Sensing (using Copernicus Sentinel-2 data) or directly from the farmers (providing in-situ crop information throughout the years and information on crop rotation). Nevertheless, the majority of the studies are restricted to the use of one modality (Remote Sensing data or crop rotation) and never fuse the Earth Observation data with domain knowledge like crop rotations. Moreover, when they use Earth Observation data they are mainly restrained to one year of data, not taking into account the past years. In this context, we propose to tackle a land use and crop type classification task using three data types, by using a Hierarchical Deep Learning algorithm modeling the crop rotations like a language model, the satellite signals like a speech signal and using the crop distribution as additional context vector. We obtained very promising results compared to classical approaches with significant performances, increasing the Accuracy by 5.1 points in a 28-class setting (.948), and the micro-F1 by 9.6 points in a 10-class setting (.887) using only a set of crop of interests selected by an expert. We finally proposed a data-augmentation technique to allow the model to classify the crop before the end of the season, which works surprisingly well in a multimodal setting.
Improving Sentiment Analysis over non-English Tweets using Multilingual Transformers and Automatic Translation for Data-Augmentation
Oct 07, 2020
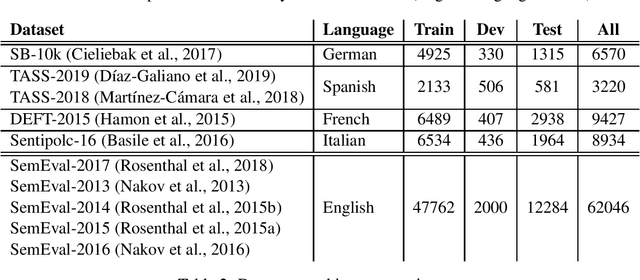
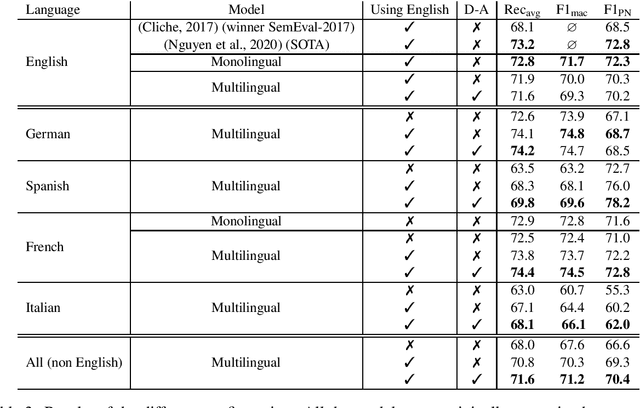
Tweets are specific text data when compared to general text. Although sentiment analysis over tweets has become very popular in the last decade for English, it is still difficult to find huge annotated corpora for non-English languages. The recent rise of the transformer models in Natural Language Processing allows to achieve unparalleled performances in many tasks, but these models need a consequent quantity of text to adapt to the tweet domain. We propose the use of a multilingual transformer model, that we pre-train over English tweets and apply data-augmentation using automatic translation to adapt the model to non-English languages. Our experiments in French, Spanish, German and Italian suggest that the proposed technique is an efficient way to improve the results of the transformers over small corpora of tweets in a non-English language.