 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Semantic Knowledge of Pre-trained Text-Encoders for Continual Learning
Aug 02, 2024


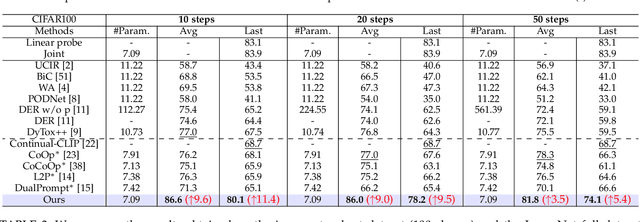
Deep neural networks (DNNs) excel on fixed datasets but struggle with incremental and shifting data in real-world scenarios. Continual learning addresses this challenge by allowing models to learn from new data while retaining previously learned knowledge. Existing methods mainly rely on visual features, often neglecting the rich semantic information encoded in text. The semantic knowledge available in the label information of the images, offers important semantic information that can be related with previously acquired knowledge of semantic classes. Consequently, effectively leveraging this information throughout continual learning is expected to be beneficial. To address this, we propose integrating semantic guidance within and across tasks by capturing semantic similarity using text embeddings. We start from a pre-trained CLIP model, employ the \emph{Semantically-guided Representation Learning (SG-RL)} module for a soft-assignment towards all current task classes, and use the Semantically-guided Knowledge Distillation (SG-KD) module for enhanced knowledge transfer. Experimental results demonstrate the superiority of our method on general and fine-grained datasets. Our code can be found in https://github.com/aprilsveryown/semantically-guided-continual-learning.
Continual Evidential Deep Learning for Out-of-Distribution Detection
Sep 06, 2023



Uncertainty-based deep learning models have attracted a great deal of interest for their ability to provide accurate and reliable predictions. Evidential deep learning stands out achieving remarkable performance in detecting out-of-distribution (OOD) data with a single deterministic neural network. Motivated by this fact, in this paper we propose the integration of an evidential deep learning method into a continual learning framework in order to perform simultaneously incremental object classification and OOD detection. Moreover, we analyze the ability of vacuity and dissonance to differentiate between in-distribution data belonging to old classes and OOD data. The proposed method, called CEDL, is evaluated on CIFAR-100 considering two settings consisting of 5 and 10 tasks, respectively. From the obtained results, we could appreciate that the proposed method, in addition to provide comparable results in object classification with respect to the baseline, largely outperforms OOD detection compared to several posthoc methods on three evaluation metrics: AUROC, AUPR and FPR95.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Improving Online Continual Learning Performance and Stability with Temporal Ensembles
Jul 03, 2023



Neural networks are very effective when trained on large datasets for a large number of iterations. However, when they are trained on non-stationary streams of data and in an online fashion, their performance is reduced (1) by the online setup, which limits the availability of data, (2) due to catastrophic forgetting because of the non-stationary nature of the data. Furthermore, several recent works (Caccia et al., 2022; Lange et al., 2023) arXiv:2205.13452 showed that replay methods used in continual learning suffer from the stability gap, encountered when evaluating the model continually (rather than only on task boundaries). In this article, we study the effect of model ensembling as a way to improve performance and stability in online continual learning. We notice that naively ensembling models coming from a variety of training tasks increases the performance in online continual learning considerably. Starting from this observation, and drawing inspirations from semi-supervised learning ensembling methods, we use a lightweight temporal ensemble that computes the exponential moving average of the weights (EMA) at test time, and show that it can drastically increase the performance and stability when used in combination with several methods from the literature.
On the importance of cross-task features for class-incremental learning
Jun 22, 2021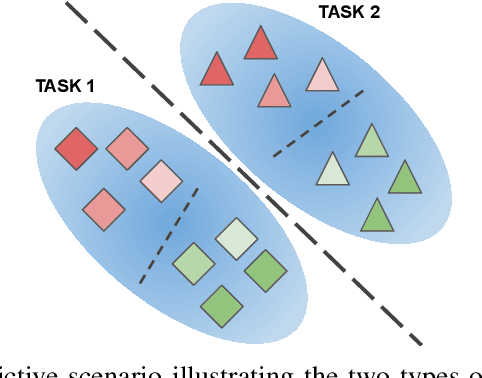
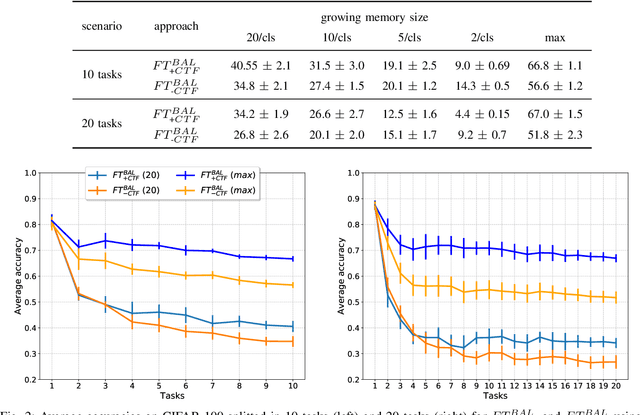
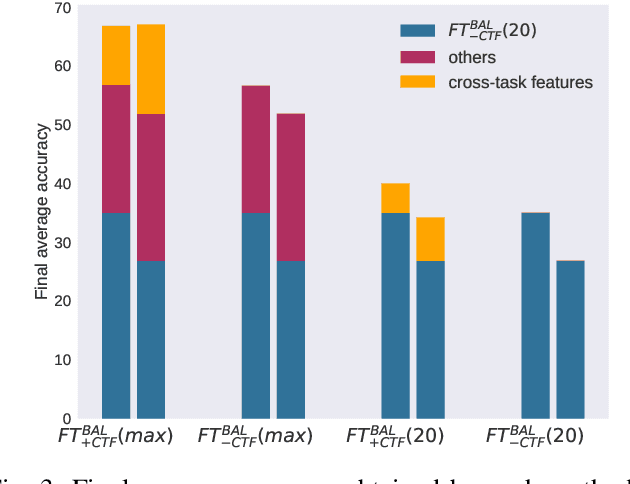
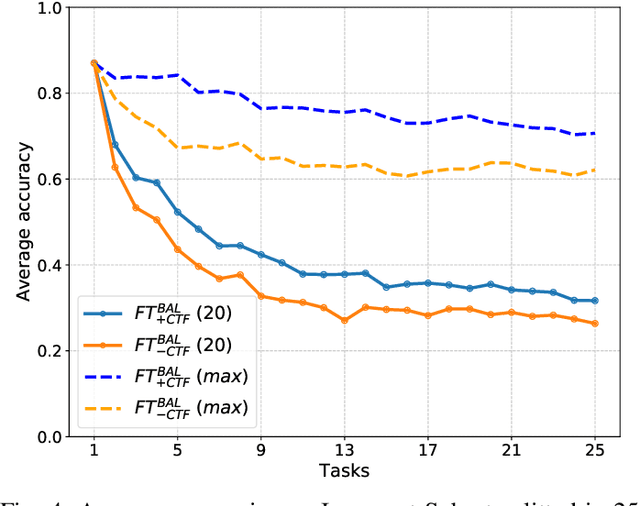
In class-incremental learning, an agent with limited resources needs to learn a sequence of classification tasks, forming an ever growing classification problem, with the constraint of not being able to access data from previous tasks. The main difference with task-incremental learning, where a task-ID is available at inference time, is that the learner also needs to perform cross-task discrimination, i.e. distinguish between classes that have not been seen together. Approaches to tackle this problem are numerous and mostly make use of an external memory (buffer) of non-negligible size. In this paper, we ablate the learning of cross-task features and study its influence on the performance of basic replay strategies used for class-IL. We also define a new forgetting measure for class-incremental learning, and see that forgetting is not the principal cause of low performance. Our experimental results show that future algorithms for class-incremental learning should not only prevent forgetting, but also aim to improve the quality of the cross-task features. This is especially important when the number of classes per task is small.
Disentanglement of Color and Shape Representations for Continual Learning
Jul 13, 2020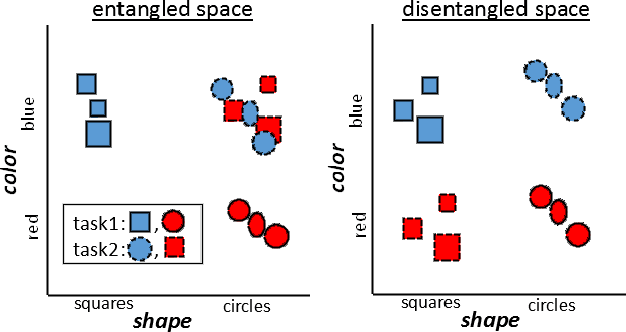
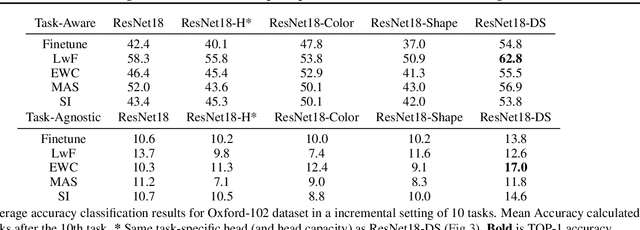
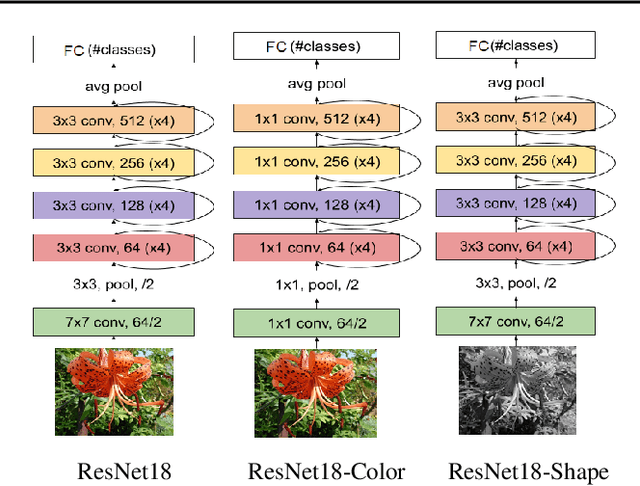
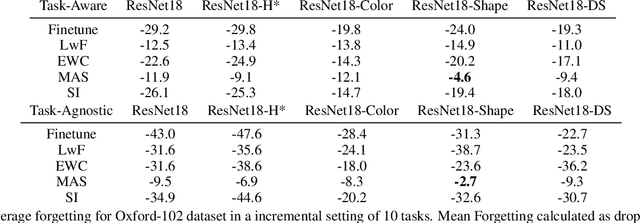
We hypothesize that disentangled feature representations suffer less from catastrophic forgetting. As a case study we perform explicit disentanglement of color and shape, by adjusting the network architecture. We tested classification accuracy and forgetting in a task-incremental setting with Oxford-102 Flowers dataset. We combine our method with Elastic Weight Consolidation, Learning without Forgetting, Synaptic Intelligence and Memory Aware Synapses, and show that feature disentanglement positively impacts continual learning performance.
Rotate your Networks: Better Weight Consolidation and Less Catastrophic Forgetting
Jul 12, 2018
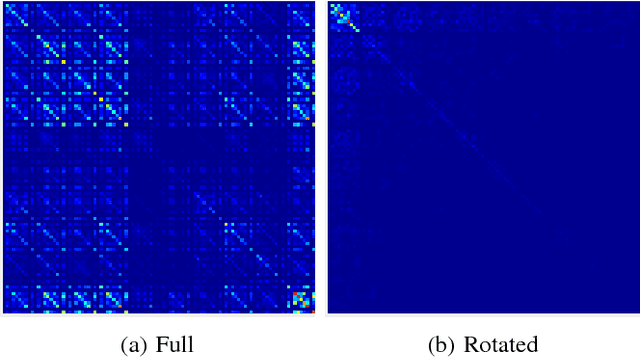
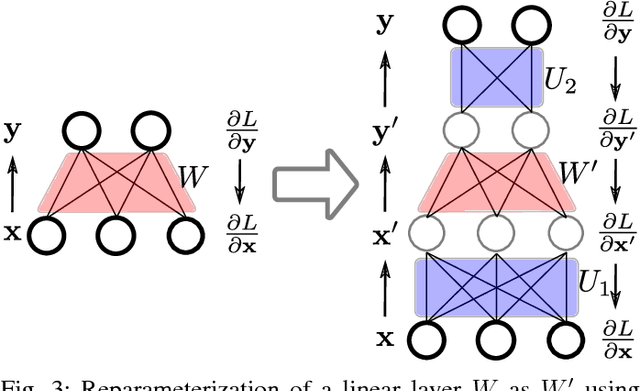
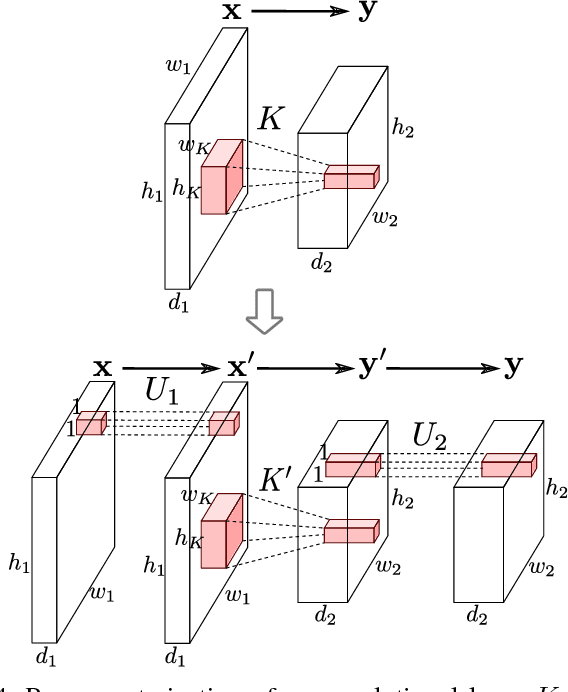
In this paper we propose an approach to avoiding catastrophic forgetting in sequential task learning scenarios. Our technique is based on a network reparameterization that approximately diagonalizes the Fisher Information Matrix of the network parameters. This reparameterization takes the form of a factorized rotation of parameter space which, when used in conjunction with Elastic Weight Consolidation (which assumes a diagonal Fisher Information Matrix), leads to significantly better performance on lifelong learning of sequential tasks. Experimental results on the MNIST, CIFAR-100, CUB-200 and Stanford-40 datasets demonstrate that we significantly improve the results of standard elastic weight consolidation, and that we obtain competitive results when compared to other state-of-the-art in lifelong learning without forgetting.