 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMRNet: Quality Metric Regression for EO Image Quality Assessment and Super-Resolution
Oct 14, 2022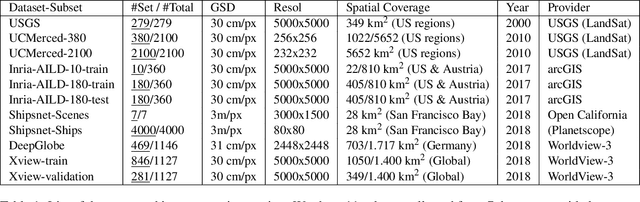
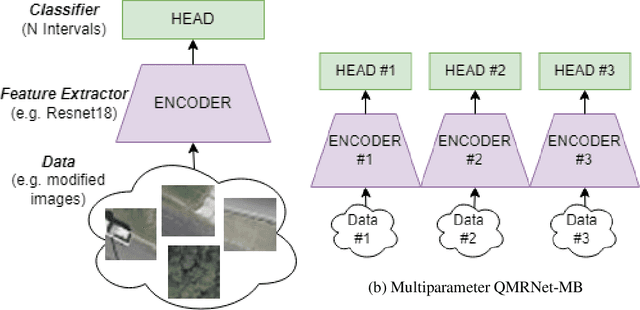

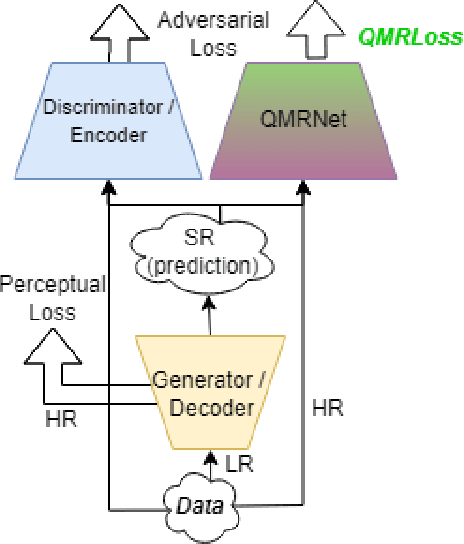
Latest advances in Super-Resolution (SR) have been tested with general purpose images such as faces, landscapes and objects, mainly unused for the task of super-resolving Earth Observation (EO) images. In this research paper, we benchmark state-of-the-art SR algorithms for distinct EO datasets using both Full-Reference and No-Reference Image Quality Assessment (IQA) metrics. We also propose a novel Quality Metric Regression Network (QMRNet) that is able to predict quality (as a No-Reference metric) by training on any property of the image (i.e. its resolution, its distortions...) and also able to optimize SR algorithms for a specific metric objective. This work is part of the implementation of the framework IQUAFLOW which has been developed for evaluating image quality, detection and classification of objects as well as image compression in EO use cases. We integrated our experimentation and tested our QMRNet algorithm on predicting features like blur, sharpness, snr, rer and ground sampling distance (GSD) and obtain validation medRs below 1.0 (out of N=50) and recall rates above 95\%. Overall benchmark shows promising results for LIIF, CAR and MSRN and also the potential use of QMRNet as Loss for optimizing SR predictions. Due to its simplicity, QMRNet could also be used for other use cases and image domains, as its architecture and data processing is fully scalable.
Saliency for free: Saliency prediction as a side-effect of object recognition
Jul 20, 2021
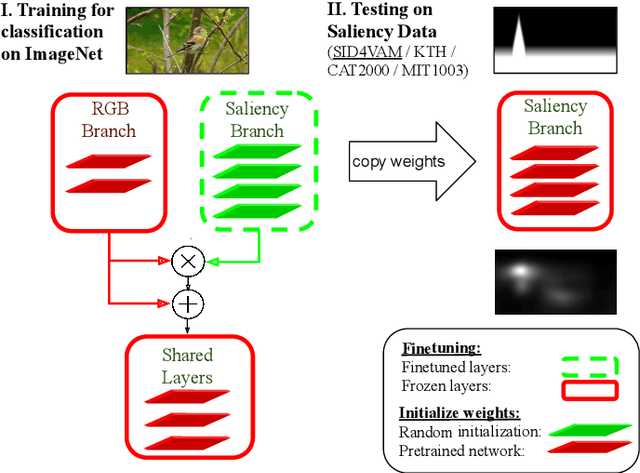

Saliency is the perceptual capacity of our visual system to focus our attention (i.e. gaze) on relevant objects. Neural networks for saliency estimation require ground truth saliency maps for training which are usually achieved via eyetracking experiments. In the current paper, we demonstrate that saliency maps can be generated as a side-effect of training an object recognition deep neural network that is endowed with a saliency branch. Such a network does not require any ground-truth saliency maps for training.Extensive experiments carried out on both real and synthetic saliency datasets demonstrate that our approach is able to generate accurate saliency maps, achieving competitive results on both synthetic and real datasets when compared to methods that do require ground truth data.
* Paper published to Pattern Recognition Letter
Hallucinating Saliency Maps for Fine-Grained Image Classification for Limited Data Domains
Jul 24, 2020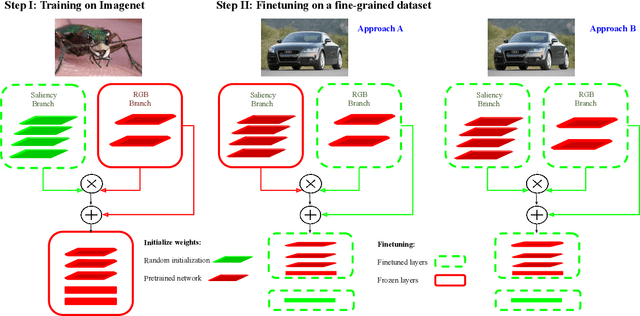


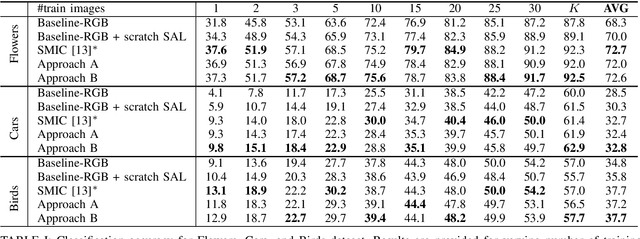
Most of the saliency methods are evaluated on their ability to generate saliency maps, and not on their functionality in a complete vision pipeline, like for instance, image classification. In the current paper, we propose an approach which does not require explicit saliency maps to improve image classification, but they are learned implicitely, during the training of an end-to-end image classification task. We show that our approach obtains similar results as the case when the saliency maps are provided explicitely. Combining RGB data with saliency maps represents a significant advantage for object recognition, especially for the case when training data is limited. We validate our method on several datasets for fine-grained classification tasks (Flowers, Birds and Cars). In addition, we show that our saliency estimation method, which is trained without any saliency groundtruth data, obtains competitive results on real image saliency benchmark (Toronto), and outperforms deep saliency models with synthetic images (SID4VAM).
Disentanglement of Color and Shape Representations for Continual Learning
Jul 13, 2020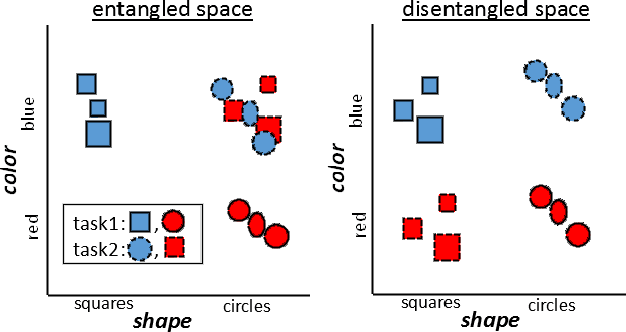
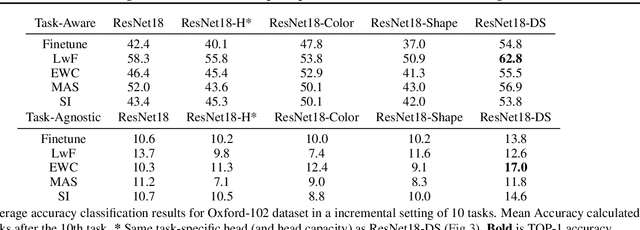
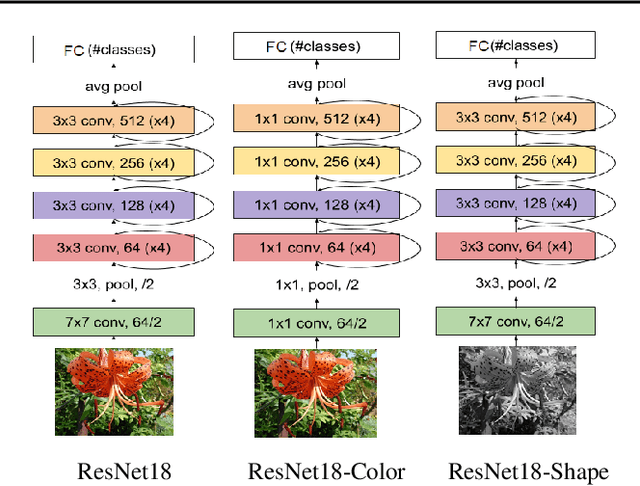
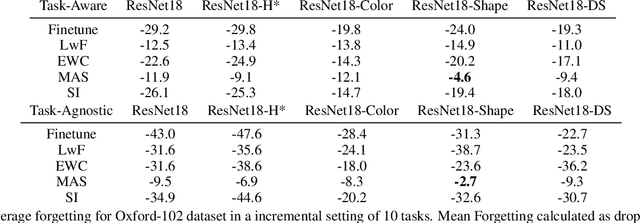
We hypothesize that disentangled feature representations suffer less from catastrophic forgetting. As a case study we perform explicit disentanglement of color and shape, by adjusting the network architecture. We tested classification accuracy and forgetting in a task-incremental setting with Oxford-102 Flowers dataset. We combine our method with Elastic Weight Consolidation, Learning without Forgetting, Synaptic Intelligence and Memory Aware Synapses, and show that feature disentanglement positively impacts continual learning performance.
MineGAN: effective knowledge transfer from GANs to target domains with few images
Dec 11, 2019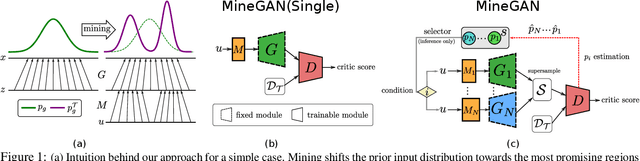

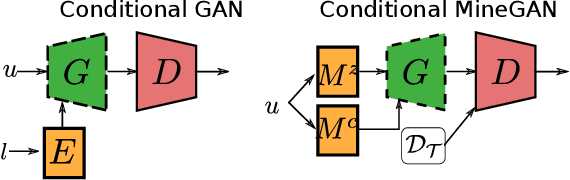
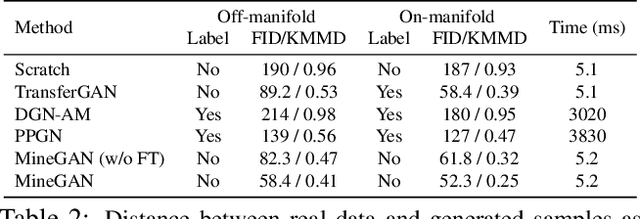
One of the attractive characteristics of deep neural networks is their ability to transfer knowledge obtained in one domain to other related domains. As a result, high-quality networks can be trained in domains with relatively little training data. This property has been extensively studied for discriminative networks but has received significantly less attention for generative models.Given the often enormous effort required to train GANs, both computationally as well as in the dataset collection, the re-use of pretrained GANs is a desirable objective. We propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods such as mode collapse and lack of flexibility. We perform experiments on several complex datasets using various GAN architectures (BigGAN, Progressive GAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
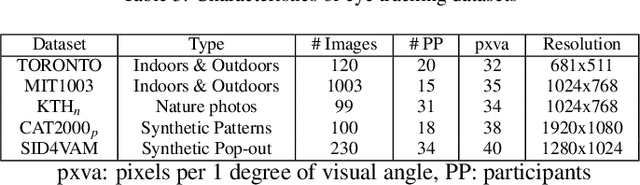
SID4VAM: A Benchmark Dataset with Synthetic Images for Visual Attention Modeling
Oct 29, 2019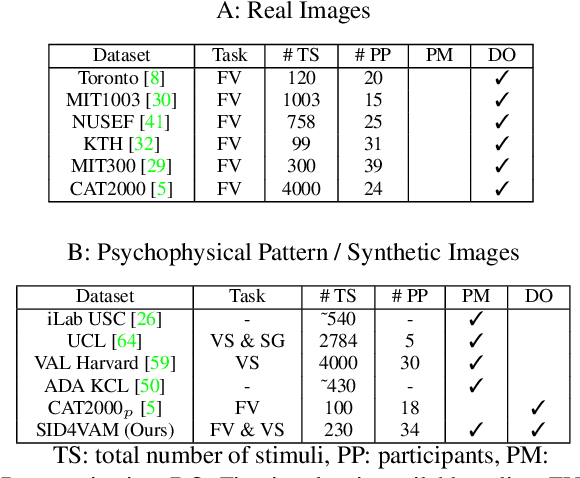
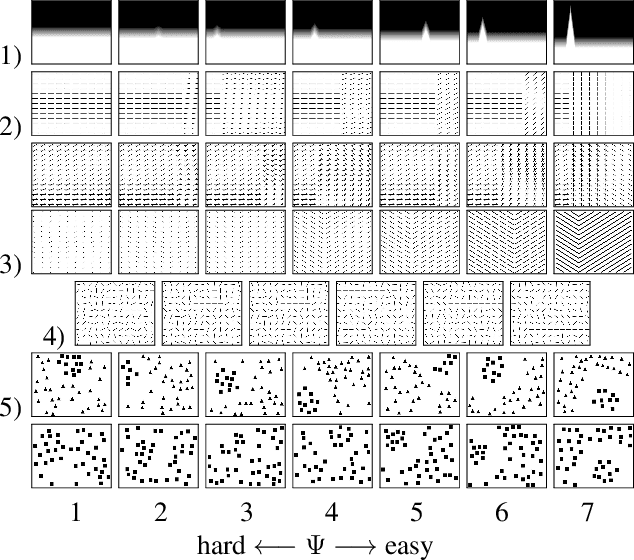
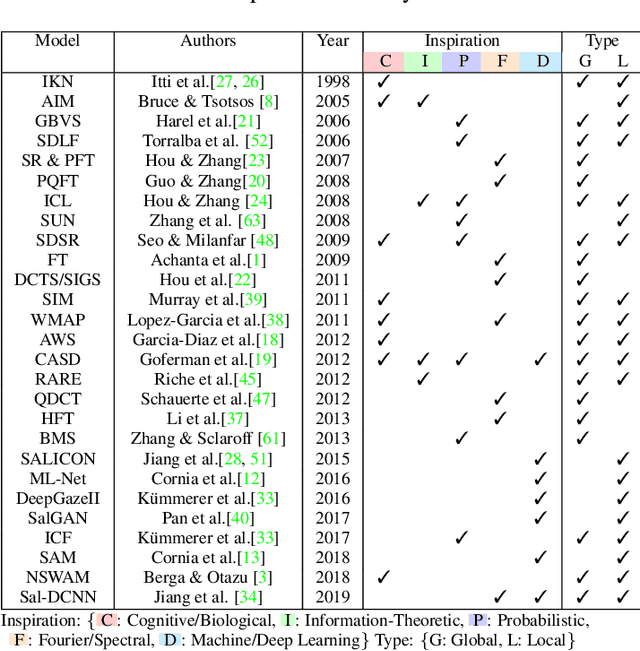
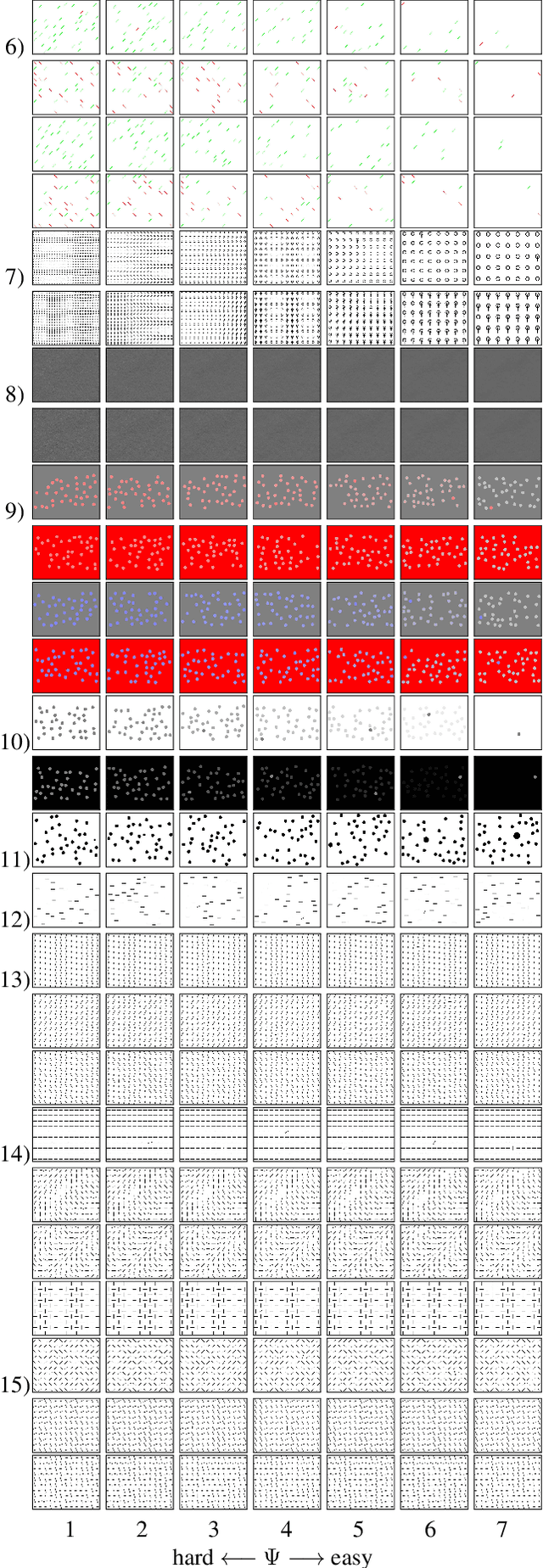
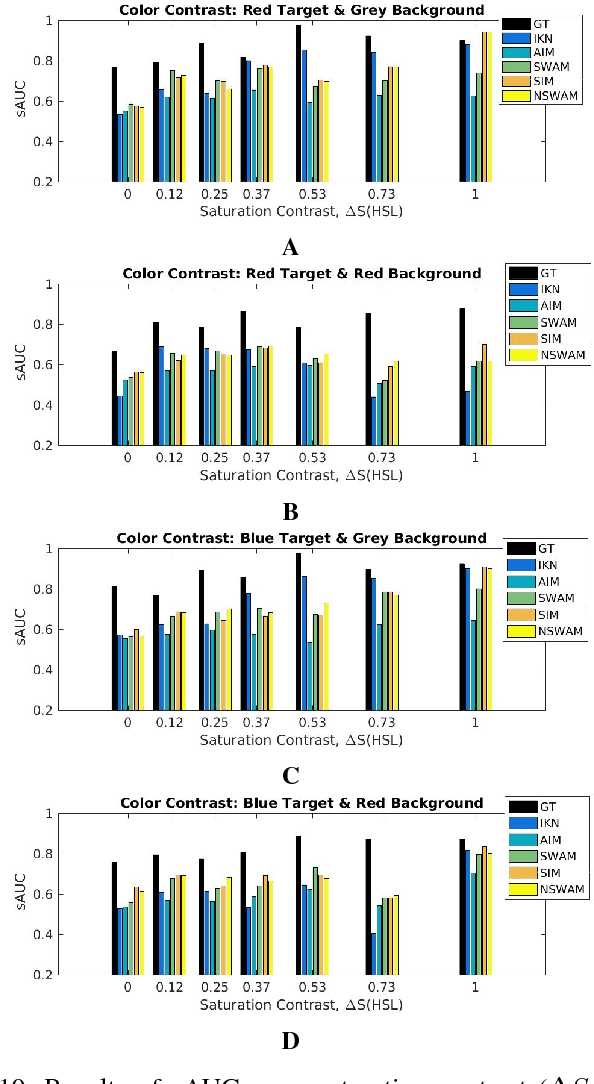
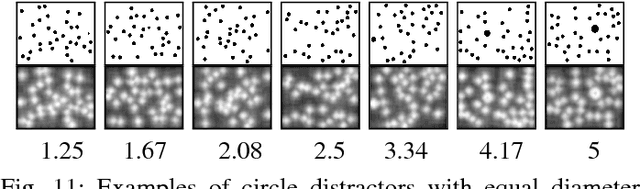
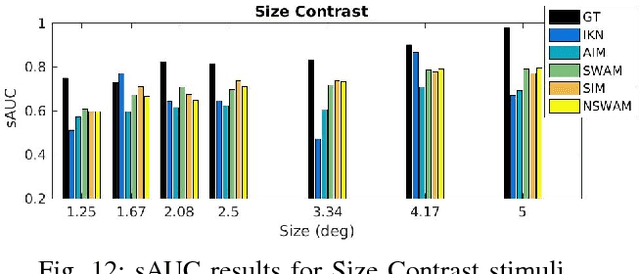
A benchmark of saliency models performance with a synthetic image dataset is provided. Model performance is evaluated through saliency metrics as well as the influence of model inspiration and consistency with human psychophysics. SID4VAM is composed of 230 synthetic images, with known salient regions. Images were generated with 15 distinct types of low-level features (e.g. orientation, brightness, color, size...) with a target-distractor pop-out type of synthetic patterns. We have used Free-Viewing and Visual Search task instructions and 7 feature contrasts for each feature category. Our study reveals that state-of-the-art Deep Learning saliency models do not perform well with synthetic pattern images, instead, models with Spectral/Fourier inspiration outperform others in saliency metrics and are more consistent with human psychophysical experimentation. This study proposes a new way to evaluate saliency models in the forthcoming literature, accounting for synthetic images with uniquely low-level feature contexts, distinct from previous eye tracking image datasets.
* 10 pages, 8 figures, 3 tables, conference paper (ICCV 2019), http://openaccess.thecvf.com/content_ICCV_2019/papers/Berga_SID4VAM_A_Benchmark_Dataset_With_Synthetic_Images_for_Visual_Attention_ICCV_2019_paper.pdf
A Neurodynamic model of Saliency prediction in V1
Dec 04, 2018
Computations in the primary visual cortex (area V1 or striate cortex) have long been hypothesized to be responsible, among several visual processing mechanisms, of bottom-up visual attention (also named saliency). In order to validate this hypothesis, images from eye tracking datasets are processed with a biologically plausible model of V1 able to reproduce other visual processes such as brightness, chromatic induction and visual discomfort. Following Li's neurodynamic model, we define V1's lateral connections with a network of firing rate neurons, sensitive to visual features such as brightness, color, orientation and scale. The resulting saliency maps are generated from the model output, representing the neuronal activity of V1 projections towards brain areas involved in eye movement control. Our predictions are supported with eye tracking experimentation and results show an improvement with respect to previous models as well as consistency with human psychophysics. We propose a unified computational architecture of the primary visual cortex that models several visual processes without applying any type of training or optimization and keeping the same parametrization.
Psychophysical evaluation of individual low-level feature influences on visual attention
Nov 15, 2018
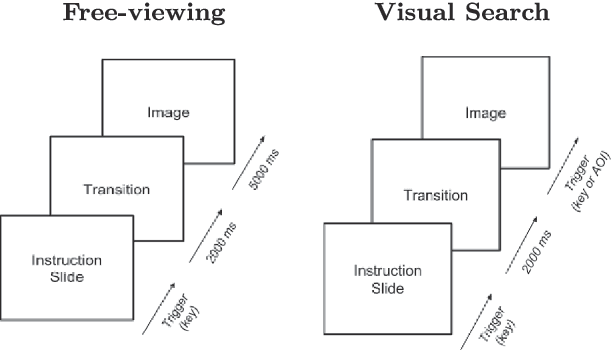

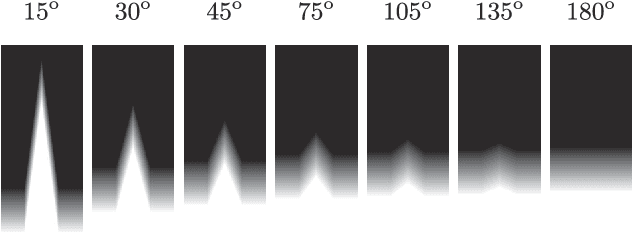
In this study we provide the analysis of eye movement behavior elicited by low-level feature distinctiveness with a dataset of synthetically-generated image patterns. Design of visual stimuli was inspired by the ones used in previous psychophysical experiments, namely in free-viewing and visual searching tasks, to provide a total of 15 types of stimuli, divided according to the task and feature to be analyzed. Our interest is to analyze the influences of low-level feature contrast between a salient region and the rest of distractors, providing fixation localization characteristics and reaction time of landing inside the salient region. Eye-tracking data was collected from 34 participants during the viewing of a 230 images dataset. Results show that saliency is predominantly and distinctively influenced by: 1. feature type, 2. feature contrast, 3. temporality of fixations, 4. task difficulty and 5. center bias. This experimentation proposes a new psychophysical basis for saliency model evaluation using synthetic images.