 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Saliency Maps for Fine-Grained Image Classification for Limited Data Domains
Paper and Code
Jul 24, 2020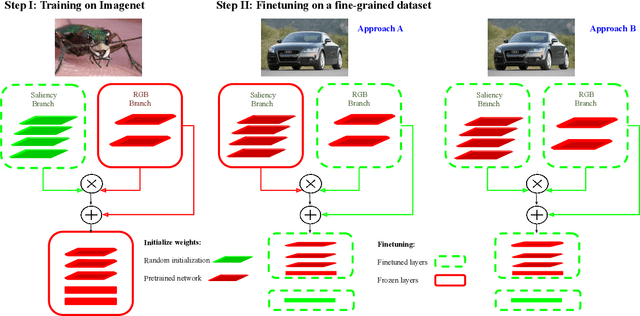


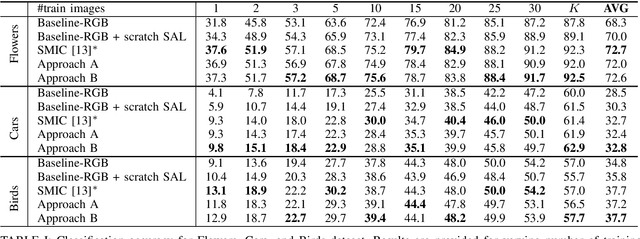
Most of the saliency methods are evaluated on their ability to generate saliency maps, and not on their functionality in a complete vision pipeline, like for instance, image classification. In the current paper, we propose an approach which does not require explicit saliency maps to improve image classification, but they are learned implicitely, during the training of an end-to-end image classification task. We show that our approach obtains similar results as the case when the saliency maps are provided explicitely. Combining RGB data with saliency maps represents a significant advantage for object recognition, especially for the case when training data is limited. We validate our method on several datasets for fine-grained classification tasks (Flowers, Birds and Cars). In addition, we show that our saliency estimation method, which is trained without any saliency groundtruth data, obtains competitive results on real image saliency benchmark (Toronto), and outperforms deep saliency models with synthetic images (SID4VAM).