 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Optimization for Backpropagation-Free Continual Test-Time Adaptation
Mar 30, 2026We introduce PACE, a backpropagation-free continual test-time adaptation system that directly optimizes the affine parameters of normalization layers. Existing derivative-free approaches struggle to balance runtime efficiency with learning capacity, as they either restrict updates to input prompts or require continuous, resource-intensive adaptation regardless of domain stability. To address these limitations, PACE leverages the Covariance Matrix Adaptation Evolution Strategy with the Fastfood projection to optimize high-dimensional affine parameters within a low-dimensional subspace, leading to superior adaptive performance. Furthermore, we enhance the runtime efficiency by incorporating an adaptation stopping criterion and a domain-specialized vector bank to eliminate redundant computation. Our framework achieves state-of-the-art accuracy across multiple benchmarks under continual distribution shifts, reducing runtime by over 50% compared to existing backpropagation-free methods.
YawDD+: Frame-level Annotations for Accurate Yawn Prediction
Dec 15, 2025Driver fatigue remains a leading cause of road accidents, with 24% of crashes involving drowsy drivers. While yawning serves as an early behavioral indicator of fatigue, existing machine learning approaches face significant challenges due to video-annotated datasets that introduce systematic noise from coarse temporal annotations. We develop a semi-automated labeling pipeline with human-in-the-loop verification, which we apply to YawDD, enabling more accurate model training. Training the established MNasNet classifier and YOLOv11 detector architectures on YawDD+ improves frame accuracy by up to 6% and mAP by 5% over video-level supervision, achieving 99.34% classification accuracy and 95.69% detection mAP. The resulting approach deliver up to 59.8 FPS on edge AI hardware (NVIDIA Jetson Nano), confirming that enhanced data quality alone supports on-device yawning monitoring without server-side computation.
Federated Distillation on Edge Devices: Efficient Client-Side Filtering for Non-IID Data
Aug 20, 2025Federated distillation has emerged as a promising collaborative machine learning approach, offering enhanced privacy protection and reduced communication compared to traditional federated learning by exchanging model outputs (soft logits) rather than full model parameters. However, existing methods employ complex selective knowledge-sharing strategies that require clients to identify in-distribution proxy data through computationally expensive statistical density ratio estimators. Additionally, server-side filtering of ambiguous knowledge introduces latency to the process. To address these challenges, we propose a robust, resource-efficient EdgeFD method that reduces the complexity of the client-side density ratio estimation and removes the need for server-side filtering. EdgeFD introduces an efficient KMeans-based density ratio estimator for effectively filtering both in-distribution and out-of-distribution proxy data on clients, significantly improving the quality of knowledge sharing. We evaluate EdgeFD across diverse practical scenarios, including strong non-IID, weak non-IID, and IID data distributions on clients, without requiring a pre-trained teacher model on the server for knowledge distillation. Experimental results demonstrate that EdgeFD outperforms state-of-the-art methods, consistently achieving accuracy levels close to IID scenarios even under heterogeneous and challenging conditions. The significantly reduced computational overhead of the KMeans-based estimator is suitable for deployment on resource-constrained edge devices, thereby enhancing the scalability and real-world applicability of federated distillation. The code is available online for reproducibility.
Incremental Learning with Repetition via Pseudo-Feature Projection
Feb 27, 2025Incremental Learning scenarios do not always represent real-world inference use-cases, which tend to have less strict task boundaries, and exhibit repetition of common classes and concepts in their continual data stream. To better represent these use-cases, new scenarios with partial repetition and mixing of tasks are proposed, where the repetition patterns are innate to the scenario and unknown to the strategy. We investigate how exemplar-free incremental learning strategies are affected by data repetition, and we adapt a series of state-of-the-art approaches to analyse and fairly compare them under both settings. Further, we also propose a novel method (Horde), able to dynamically adjust an ensemble of self-reliant feature extractors, and align them by exploiting class repetition. Our proposed exemplar-free method achieves competitive results in the classic scenario without repetition, and state-of-the-art performance in the one with repetition.
Leveraging Intermediate Representations for Better Out-of-Distribution Detection
Feb 18, 2025In real-world applications, machine learning models must reliably detect Out-of-Distribution (OoD) samples to prevent unsafe decisions. Current OoD detection methods often rely on analyzing the logits or the embeddings of the penultimate layer of a neural network. However, little work has been conducted on the exploitation of the rich information encoded in intermediate layers. To address this, we analyze the discriminative power of intermediate layers and show that they can positively be used for OoD detection. Therefore, we propose to regularize intermediate layers with an energy-based contrastive loss, and by grouping multiple layers in a single aggregated response. We demonstrate that intermediate layer activations improves OoD detection performance by running a comprehensive evaluation across multiple datasets.
* Code is available at https://github.com/gigug/LIR
Sit Back and Relax: Learning to Drive Incrementally in All Weather Conditions
May 30, 2023



In autonomous driving scenarios, current object detection models show strong performance when tested in clear weather. However, their performance deteriorates significantly when tested in degrading weather conditions. In addition, even when adapted to perform robustly in a sequence of different weather conditions, they are often unable to perform well in all of them and suffer from catastrophic forgetting. To efficiently mitigate forgetting, we propose Domain-Incremental Learning through Activation Matching (DILAM), which employs unsupervised feature alignment to adapt only the affine parameters of a clear weather pre-trained network to different weather conditions. We propose to store these affine parameters as a memory bank for each weather condition and plug-in their weather-specific parameters during driving (i.e. test time) when the respective weather conditions are encountered. Our memory bank is extremely lightweight, since affine parameters account for less than 2% of a typical object detector. Furthermore, contrary to previous domain-incremental learning approaches, we do not require the weather label when testing and propose to automatically infer the weather condition by a majority voting linear classifier.
An Efficient Domain-Incremental Learning Approach to Drive in All Weather Conditions
Apr 21, 2022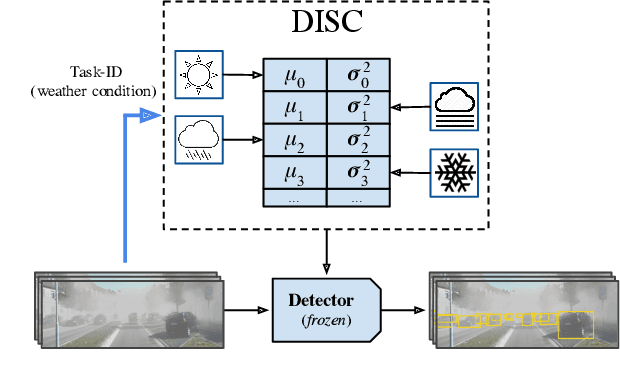
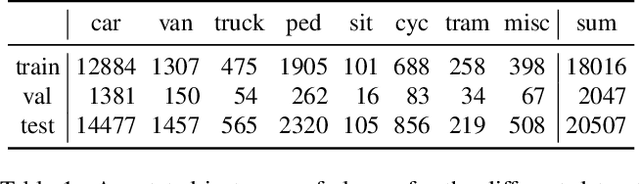
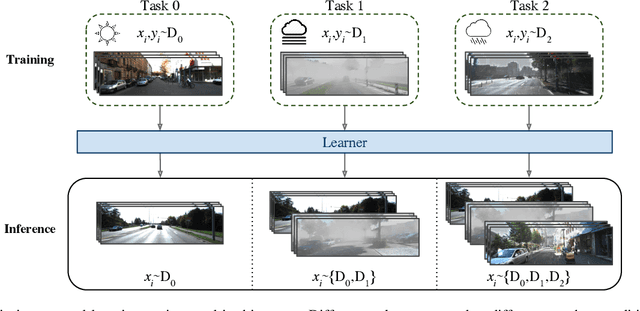
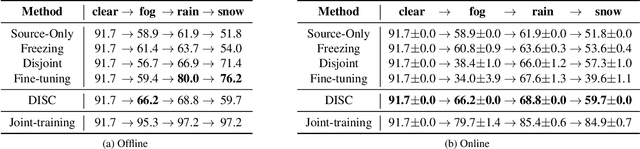
Although deep neural networks enable impressive visual perception performance for autonomous driving, their robustness to varying weather conditions still requires attention. When adapting these models for changed environments, such as different weather conditions, they are prone to forgetting previously learned information. This catastrophic forgetting is typically addressed via incremental learning approaches which usually re-train the model by either keeping a memory bank of training samples or keeping a copy of the entire model or model parameters for each scenario. While these approaches show impressive results, they can be prone to scalability issues and their applicability for autonomous driving in all weather conditions has not been shown. In this paper we propose DISC -- Domain Incremental through Statistical Correction -- a simple online zero-forgetting approach which can incrementally learn new tasks (i.e weather conditions) without requiring re-training or expensive memory banks. The only information we store for each task are the statistical parameters as we categorize each domain by the change in first and second order statistics. Thus, as each task arrives, we simply 'plug and play' the statistical vectors for the corresponding task into the model and it immediately starts to perform well on that task. We show the efficacy of our approach by testing it for object detection in a challenging domain-incremental autonomous driving scenario where we encounter different adverse weather conditions, such as heavy rain, fog, and snow.
On the importance of cross-task features for class-incremental learning
Jun 22, 2021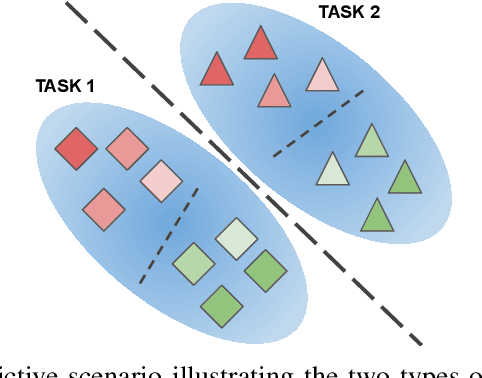
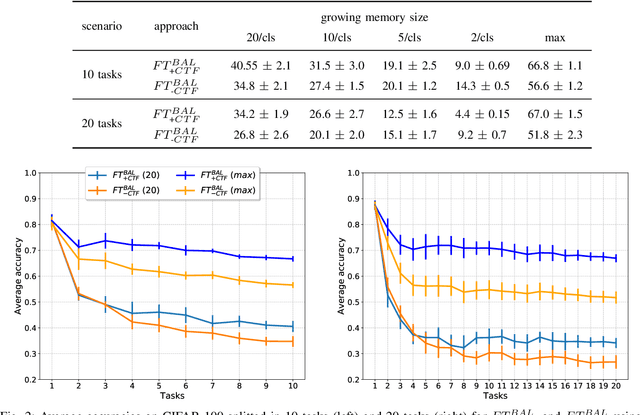
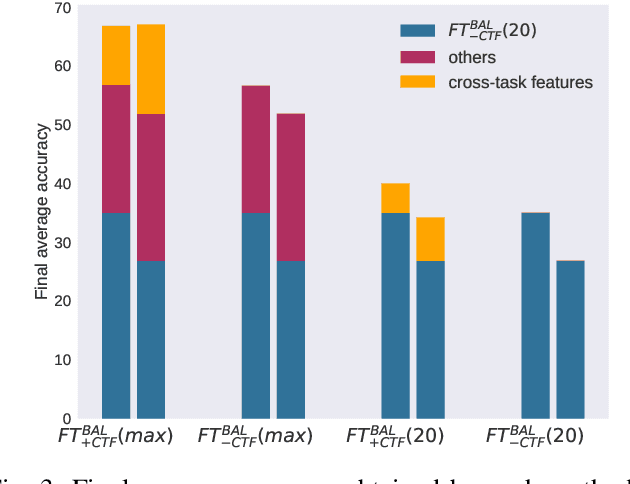
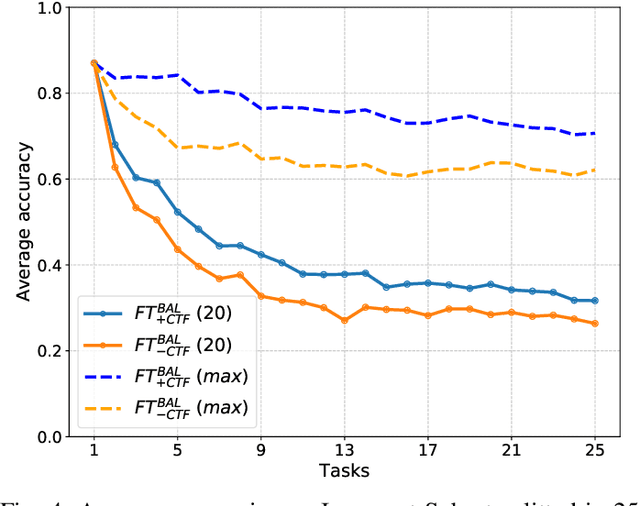
In class-incremental learning, an agent with limited resources needs to learn a sequence of classification tasks, forming an ever growing classification problem, with the constraint of not being able to access data from previous tasks. The main difference with task-incremental learning, where a task-ID is available at inference time, is that the learner also needs to perform cross-task discrimination, i.e. distinguish between classes that have not been seen together. Approaches to tackle this problem are numerous and mostly make use of an external memory (buffer) of non-negligible size. In this paper, we ablate the learning of cross-task features and study its influence on the performance of basic replay strategies used for class-IL. We also define a new forgetting measure for class-incremental learning, and see that forgetting is not the principal cause of low performance. Our experimental results show that future algorithms for class-incremental learning should not only prevent forgetting, but also aim to improve the quality of the cross-task features. This is especially important when the number of classes per task is small.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021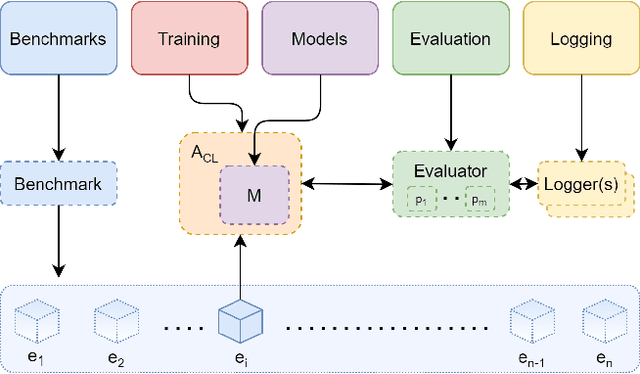

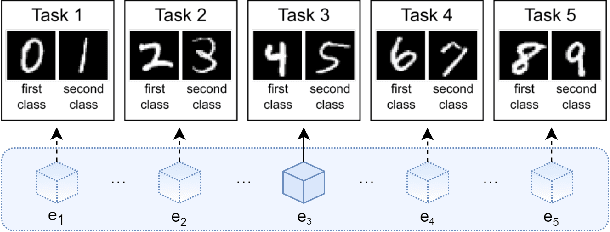

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
Class-incremental learning: survey and performance evaluation
Oct 28, 2020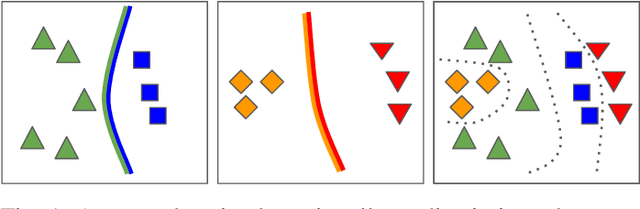
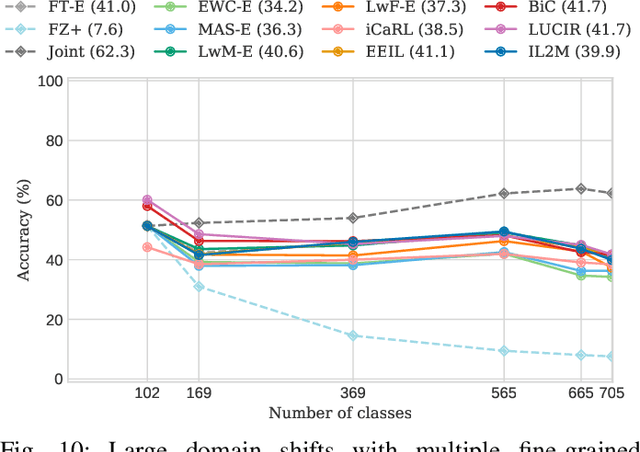
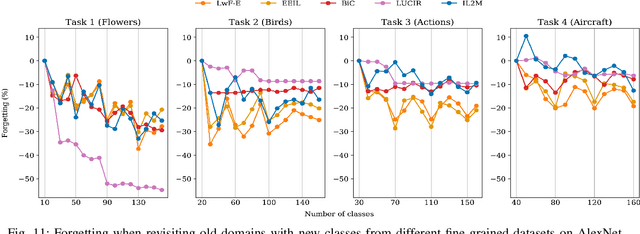
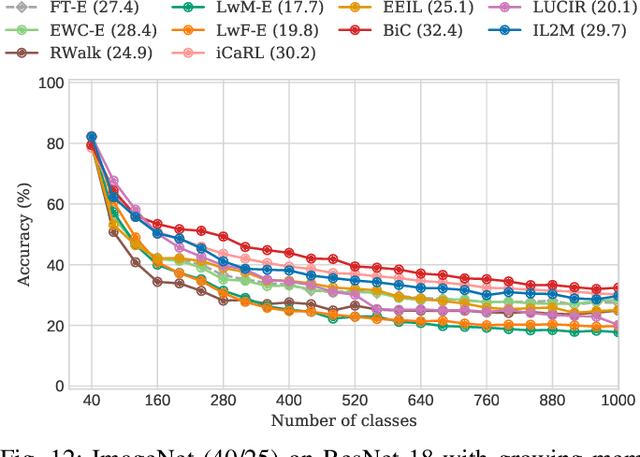
For future learning systems incremental learning is desirable, because it allows for: efficient resource usage by eliminating the need to retrain from scratch at the arrival of new data; reduced memory usage by preventing or limiting the amount of data required to be stored -- also important when privacy limitations are imposed; and learning that more closely resembles human learning. The main challenge for incremental learning is catastrophic forgetting, which refers to the precipitous drop in performance on previously learned tasks after learning a new one. Incremental learning of deep neural networks has seen explosive growth in recent years. Initial work focused on task incremental learning, where a task-ID is provided at inference time. Recently we have seen a shift towards class-incremental learning where the learner must classify at inference time between all classes seen in previous tasks without recourse to a task-ID. In this paper, we provide a complete survey of existing methods for incremental learning, and in particular we perform an extensive experimental evaluation on twelve class-incremental methods. We consider several new experimental scenarios, including a comparison of class-incremental methods on multiple large-scale datasets, investigation into small and large domain shifts, and comparison on various network architectures.