 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResurrecting Old Classes with New Data for Exemplar-Free Continual Learning
May 29, 2024



Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets. Code is available at https://github.com/dipamgoswami/ADC.
An Empirical Analysis of Forgetting in Pre-trained Models with Incremental Low-Rank Updates
May 28, 2024



Broad, open source availability of large pretrained foundation models on the internet through platforms such as HuggingFace has taken the world of practical deep learning by storm. A classical pipeline for neural network training now typically consists of finetuning these pretrained network on a small target dataset instead of training from scratch. In the case of large models this can be done even on modest hardware using a low rank training technique known as Low-Rank Adaptation (LoRA). While Low Rank training has already been studied in the continual learning setting, existing works often consider storing the learned adapter along with the existing model but rarely attempt to modify the weights of the pretrained model by merging the LoRA with the existing weights after finishing the training of each task. In this article we investigate this setting and study the impact of LoRA rank on the forgetting of the pretraining foundation task and on the plasticity and forgetting of subsequent ones. We observe that this rank has an important impact on forgetting of both the pretraining and downstream tasks. We also observe that vision transformers finetuned in that way exhibit a sort of ``contextual'' forgetting, a behaviour that we do not observe for residual networks and that we believe has not been observed yet in previous continual learning works.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Improving Online Continual Learning Performance and Stability with Temporal Ensembles
Jul 03, 2023



Neural networks are very effective when trained on large datasets for a large number of iterations. However, when they are trained on non-stationary streams of data and in an online fashion, their performance is reduced (1) by the online setup, which limits the availability of data, (2) due to catastrophic forgetting because of the non-stationary nature of the data. Furthermore, several recent works (Caccia et al., 2022; Lange et al., 2023) arXiv:2205.13452 showed that replay methods used in continual learning suffer from the stability gap, encountered when evaluating the model continually (rather than only on task boundaries). In this article, we study the effect of model ensembling as a way to improve performance and stability in online continual learning. We notice that naively ensembling models coming from a variety of training tasks increases the performance in online continual learning considerably. Starting from this observation, and drawing inspirations from semi-supervised learning ensembling methods, we use a lightweight temporal ensemble that computes the exponential moving average of the weights (EMA) at test time, and show that it can drastically increase the performance and stability when used in combination with several methods from the literature.
On the importance of cross-task features for class-incremental learning
Jun 22, 2021
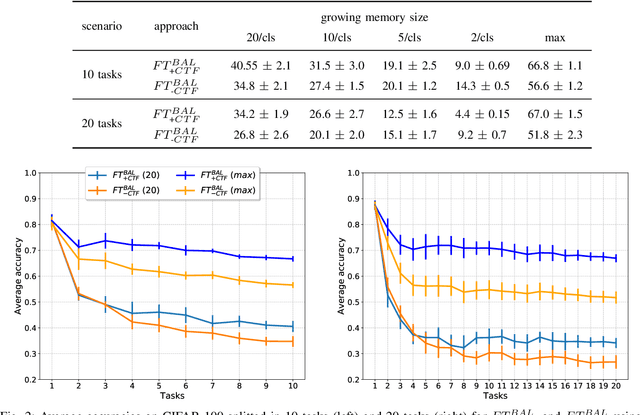
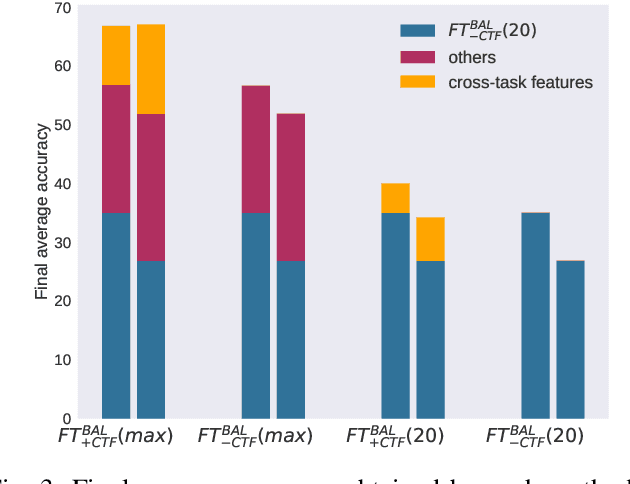
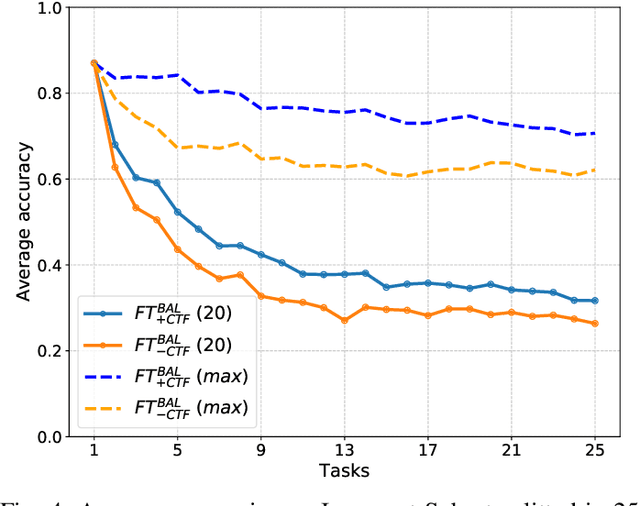
In class-incremental learning, an agent with limited resources needs to learn a sequence of classification tasks, forming an ever growing classification problem, with the constraint of not being able to access data from previous tasks. The main difference with task-incremental learning, where a task-ID is available at inference time, is that the learner also needs to perform cross-task discrimination, i.e. distinguish between classes that have not been seen together. Approaches to tackle this problem are numerous and mostly make use of an external memory (buffer) of non-negligible size. In this paper, we ablate the learning of cross-task features and study its influence on the performance of basic replay strategies used for class-IL. We also define a new forgetting measure for class-incremental learning, and see that forgetting is not the principal cause of low performance. Our experimental results show that future algorithms for class-incremental learning should not only prevent forgetting, but also aim to improve the quality of the cross-task features. This is especially important when the number of classes per task is small.