 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSID4VAM: A Benchmark Dataset with Synthetic Images for Visual Attention Modeling
Oct 29, 2019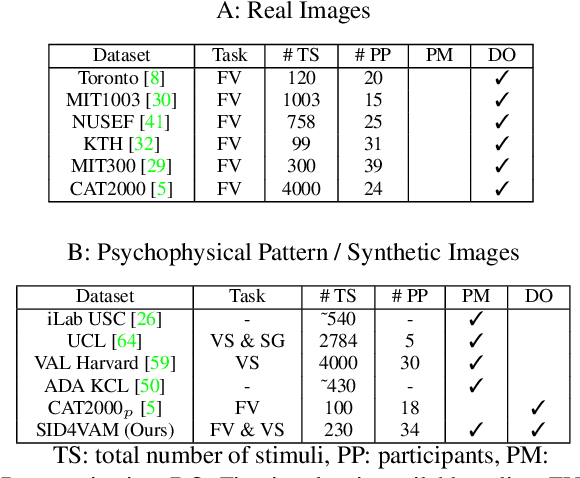
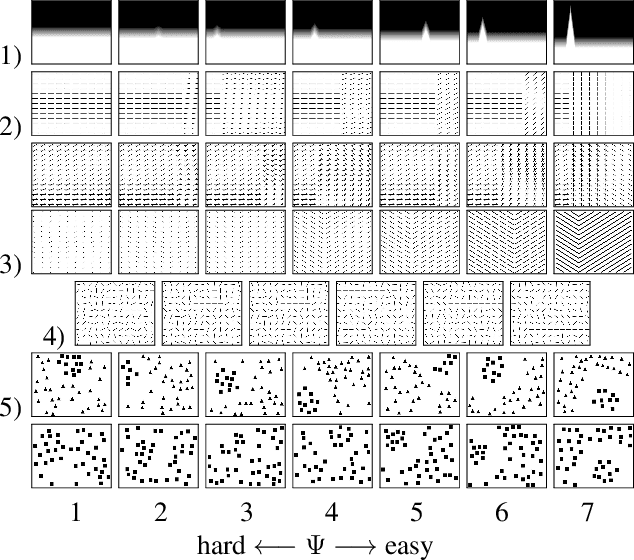
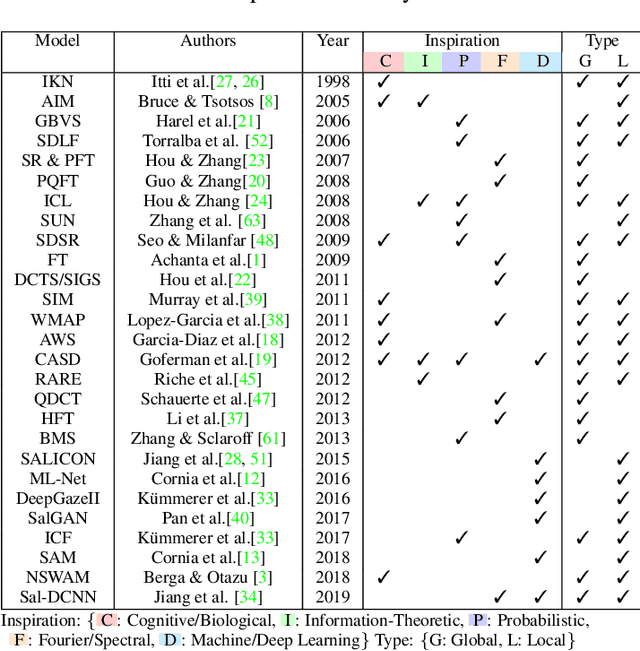
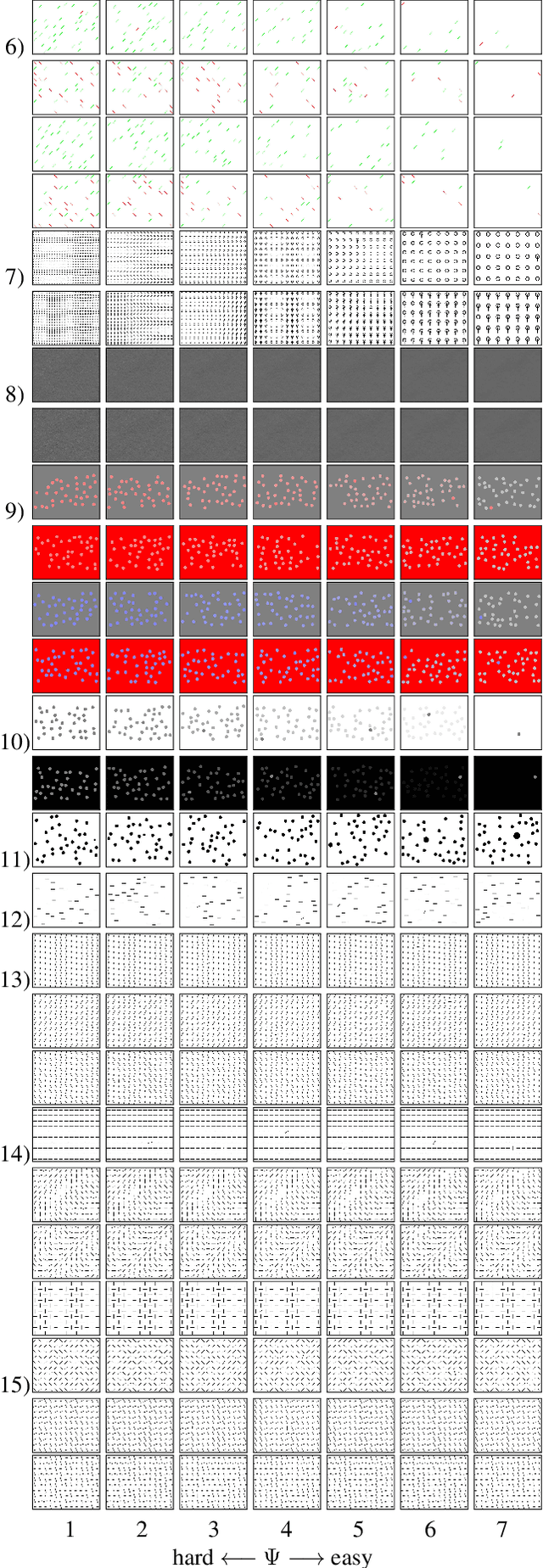
A benchmark of saliency models performance with a synthetic image dataset is provided. Model performance is evaluated through saliency metrics as well as the influence of model inspiration and consistency with human psychophysics. SID4VAM is composed of 230 synthetic images, with known salient regions. Images were generated with 15 distinct types of low-level features (e.g. orientation, brightness, color, size...) with a target-distractor pop-out type of synthetic patterns. We have used Free-Viewing and Visual Search task instructions and 7 feature contrasts for each feature category. Our study reveals that state-of-the-art Deep Learning saliency models do not perform well with synthetic pattern images, instead, models with Spectral/Fourier inspiration outperform others in saliency metrics and are more consistent with human psychophysical experimentation. This study proposes a new way to evaluate saliency models in the forthcoming literature, accounting for synthetic images with uniquely low-level feature contexts, distinct from previous eye tracking image datasets.
* 10 pages, 8 figures, 3 tables, conference paper (ICCV 2019), http://openaccess.thecvf.com/content_ICCV_2019/papers/Berga_SID4VAM_A_Benchmark_Dataset_With_Synthetic_Images_for_Visual_Attention_ICCV_2019_paper.pdf