 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigation of gender bias in automatic facial non-verbal behaviors generation
Oct 09, 2024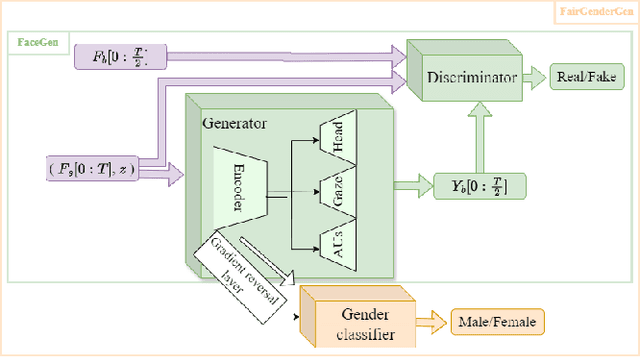

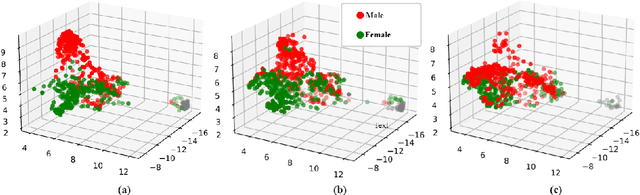
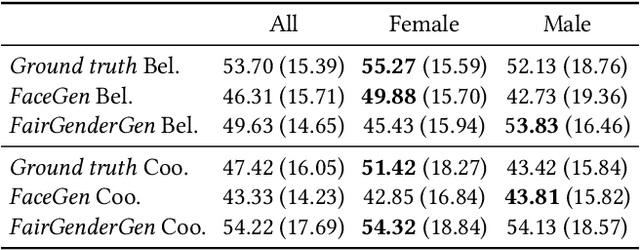
Research on non-verbal behavior generation for social interactive agents focuses mainly on the believability and synchronization of non-verbal cues with speech. However, existing models, predominantly based on deep learning architectures, often perpetuate biases inherent in the training data. This raises ethical concerns, depending on the intended application of these agents. This paper addresses these issues by first examining the influence of gender on facial non-verbal behaviors. We concentrate on gaze, head movements, and facial expressions. We introduce a classifier capable of discerning the gender of a speaker from their non-verbal cues. This classifier achieves high accuracy on both real behavior data, extracted using state-of-the-art tools, and synthetic data, generated from a model developed in previous work.Building upon this work, we present a new model, FairGenderGen, which integrates a gender discriminator and a gradient reversal layer into our previous behavior generation model. This new model generates facial non-verbal behaviors from speech features, mitigating gender sensitivity in the generated behaviors. Our experiments demonstrate that the classifier, developed in the initial phase, is no longer effective in distinguishing the gender of the speaker from the generated non-verbal behaviors.
A Learning Paradigm for Interpretable Gradients
Apr 23, 2024


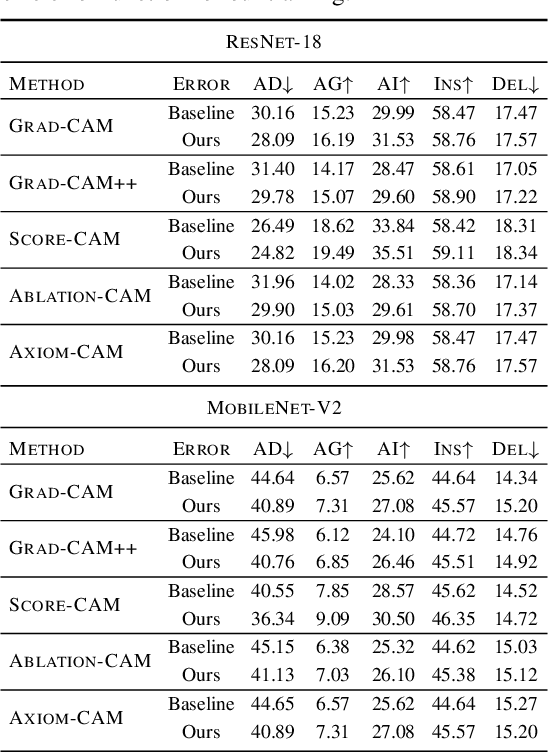
This paper studies interpretability of convolutional networks by means of saliency maps. Most approaches based on Class Activation Maps (CAM) combine information from fully connected layers and gradient through variants of backpropagation. However, it is well understood that gradients are noisy and alternatives like guided backpropagation have been proposed to obtain better visualization at inference. In this work, we present a novel training approach to improve the quality of gradients for interpretability. In particular, we introduce a regularization loss such that the gradient with respect to the input image obtained by standard backpropagation is similar to the gradient obtained by guided backpropagation. We find that the resulting gradient is qualitatively less noisy and improves quantitatively the interpretability properties of different networks, using several interpretability methods.
Opti-CAM: Optimizing saliency maps for interpretability
Jan 17, 2023



Methods based on class activation maps (CAM) provide a simple mechanism to interpret predictions of convolutional neural networks by using linear combinations of feature maps as saliency maps. By contrast, masking-based methods optimize a saliency map directly in the image space or learn it by training another network on additional data. In this work we introduce Opti-CAM, combining ideas from CAM-based and masking-based approaches. Our saliency map is a linear combination of feature maps, where weights are optimized per image such that the logit of the masked image for a given class is maximized. We also fix a fundamental flaw in two of the most common evaluation metrics of attribution methods. On several datasets, Opti-CAM largely outperforms other CAM-based approaches according to the most relevant classification metrics. We provide empirical evidence supporting that localization and classifier interpretability are not necessarily aligned.
ChaLearn Looking at People: Inpainting and Denoising challenges
Jun 24, 2021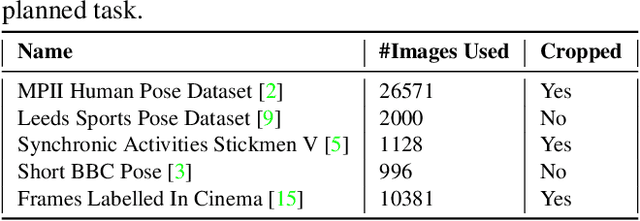
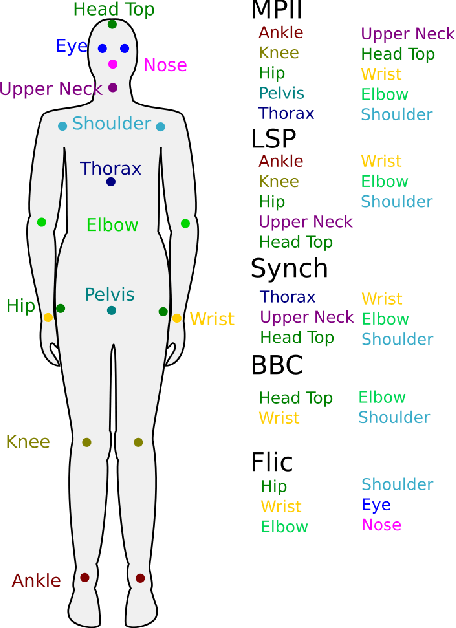
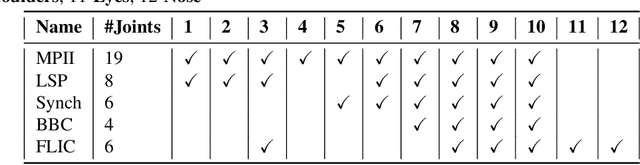

Dealing with incomplete information is a well studied problem in the context of machine learning and computational intelligence. However, in the context of computer vision, the problem has only been studied in specific scenarios (e.g., certain types of occlusions in specific types of images), although it is common to have incomplete information in visual data. This chapter describes the design of an academic competition focusing on inpainting of images and video sequences that was part of the competition program of WCCI2018 and had a satellite event collocated with ECCV2018. The ChaLearn Looking at People Inpainting Challenge aimed at advancing the state of the art on visual inpainting by promoting the development of methods for recovering missing and occluded information from images and video. Three tracks were proposed in which visual inpainting might be helpful but still challenging: human body pose estimation, text overlays removal and fingerprint denoising. This chapter describes the design of the challenge, which includes the release of three novel datasets, and the description of evaluation metrics, baselines and evaluation protocol. The results of the challenge are analyzed and discussed in detail and conclusions derived from this event are outlined.
Distillation of Weighted Automata from Recurrent Neural Networks using a Spectral Approach
Sep 28, 2020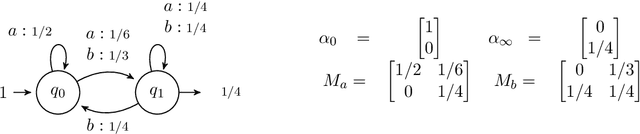
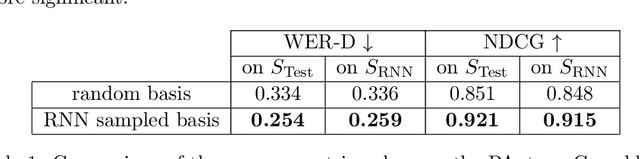
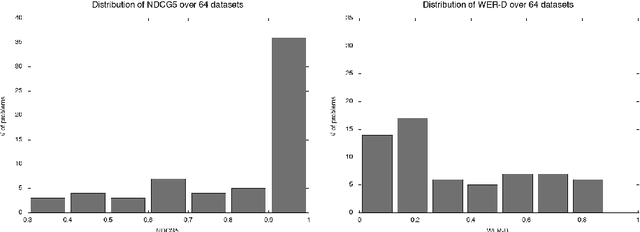
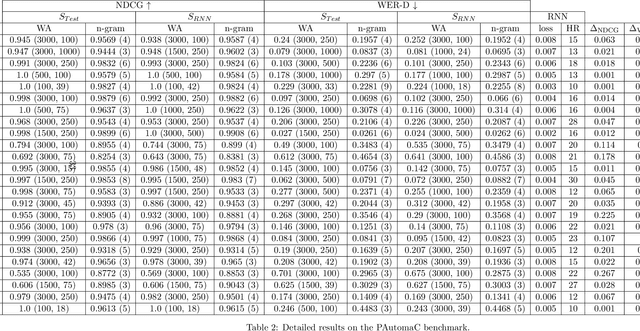
This paper is an attempt to bridge the gap between deep learning and grammatical inference. Indeed, it provides an algorithm to extract a (stochastic) formal language from any recurrent neural network trained for language modelling. In detail, the algorithm uses the already trained network as an oracle -- and thus does not require the access to the inner representation of the black-box -- and applies a spectral approach to infer a weighted automaton. As weighted automata compute linear functions, they are computationally more efficient than neural networks and thus the nature of the approach is the one of knowledge distillation. We detail experiments on 62 data sets (both synthetic and from real-world applications) that allow an in-depth study of the abilities of the proposed algorithm. The results show the WA we extract are good approximations of the RNN, validating the approach. Moreover, we show how the process provides interesting insights toward the behavior of RNN learned on data, enlarging the scope of this work to the one of explainability of deep learning models.
Explaining First Impressions: Modeling, Recognizing, and Explaining Apparent Personality from Videos
Oct 15, 2018
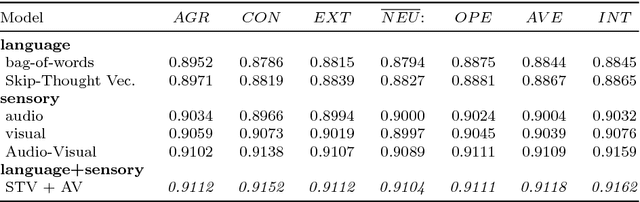
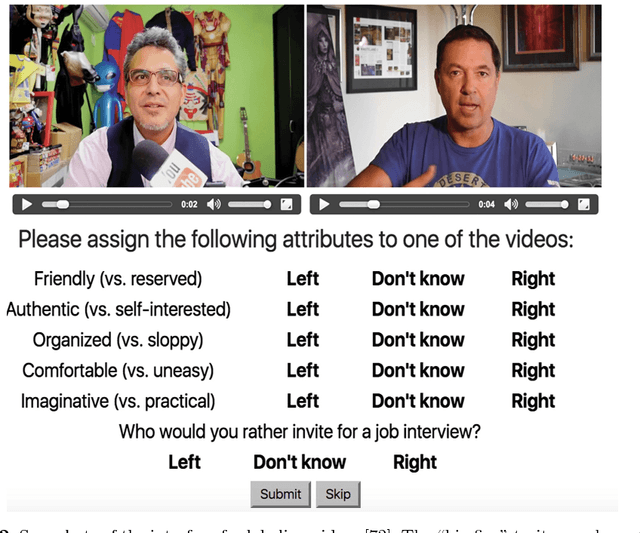
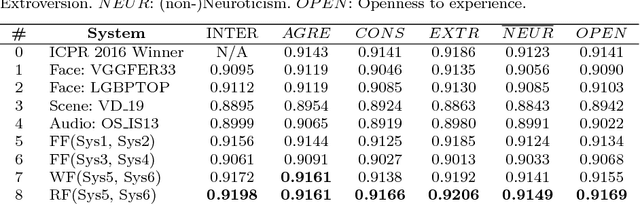
Explainability and interpretability are two critical aspects of decision support systems. Within computer vision, they are critical in certain tasks related to human behavior analysis such as in health care applications. Despite their importance, it is only recently that researchers are starting to explore these aspects. This paper provides an introduction to explainability and interpretability in the context of computer vision with an emphasis on looking at people tasks. Specifically, we review and study those mechanisms in the context of first impressions analysis. To the best of our knowledge, this is the first effort in this direction. Additionally, we describe a challenge we organized on explainability in first impressions analysis from video. We analyze in detail the newly introduced data set, the evaluation protocol, and summarize the results of the challenge. Finally, derived from our study, we outline research opportunities that we foresee will be decisive in the near future for the development of the explainable computer vision field.
Explaining Black Boxes on Sequential Data using Weighted Automata
Oct 12, 2018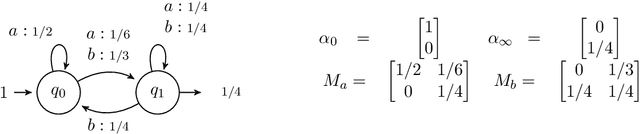
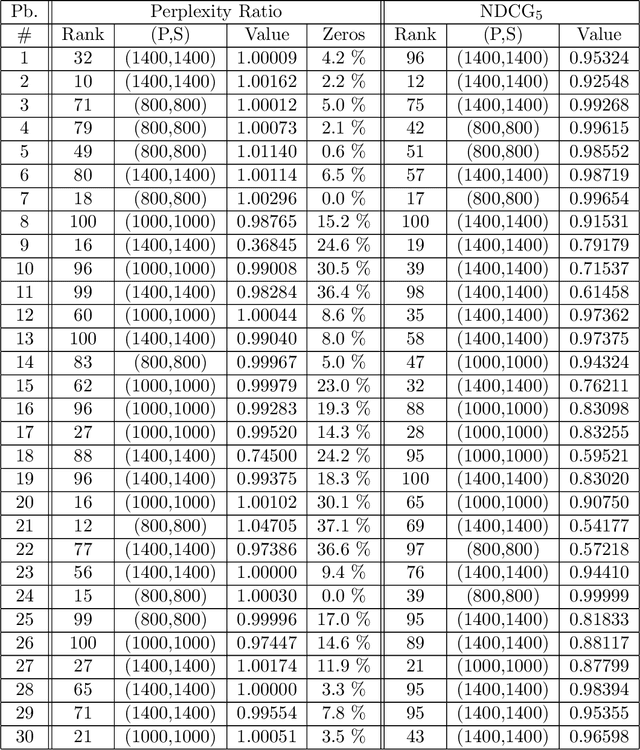
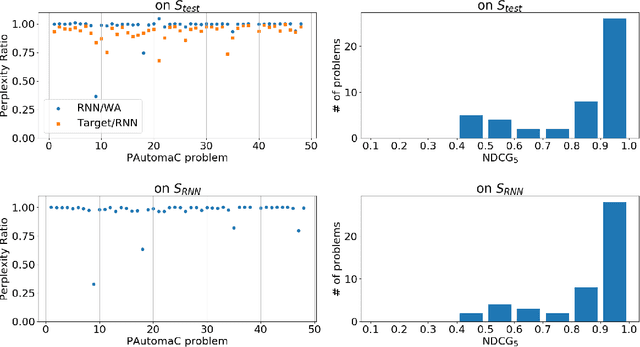
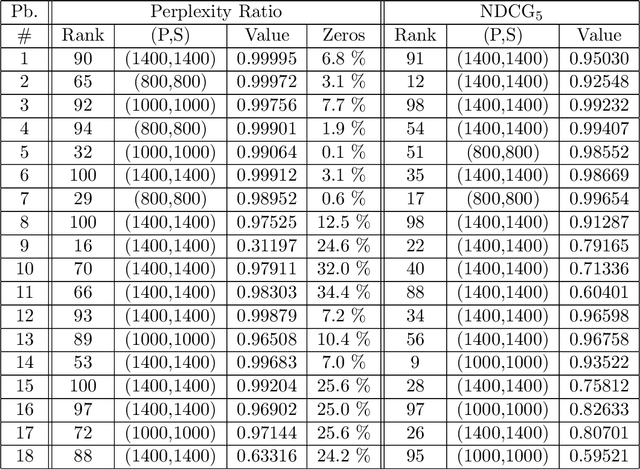
Understanding how a learned black box works is of crucial interest for the future of Machine Learning. In this paper, we pioneer the question of the global interpretability of learned black box models that assign numerical values to symbolic sequential data. To tackle that task, we propose a spectral algorithm for the extraction of weighted automata (WA) from such black boxes. This algorithm does not require the access to a dataset or to the inner representation of the black box: the inferred model can be obtained solely by querying the black box, feeding it with inputs and analyzing its outputs. Experiments using Recurrent Neural Networks (RNN) trained on a wide collection of 48 synthetic datasets and 2 real datasets show that the obtained approximation is of great quality.