 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the contribution of different passively collected data to predict Stress and Depression
Oct 20, 2023
The possibility of recognizing diverse aspects of human behavior and environmental context from passively captured data motivates its use for mental health assessment. In this paper, we analyze the contribution of different passively collected sensor data types (WiFi, GPS, Social interaction, Phone Log, Physical Activity, Audio, and Academic features) to predict daily selfreport stress and PHQ-9 depression score. First, we compute 125 mid-level features from the original raw data. These 125 features include groups of features from the different sensor data types. Then, we evaluate the contribution of each feature type by comparing the performance of Neural Network models trained with all features against Neural Network models trained with specific feature groups. Our results show that WiFi features (which encode mobility patterns) and Phone Log features (which encode information correlated with sleep patterns), provide significative information for stress and depression prediction.
ChaLearn Looking at People: Inpainting and Denoising challenges
Jun 24, 2021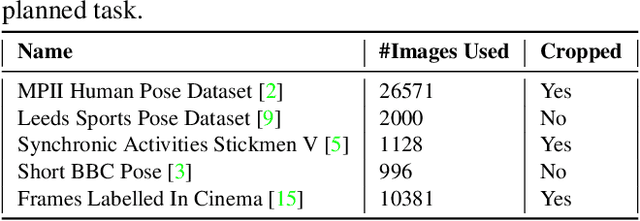
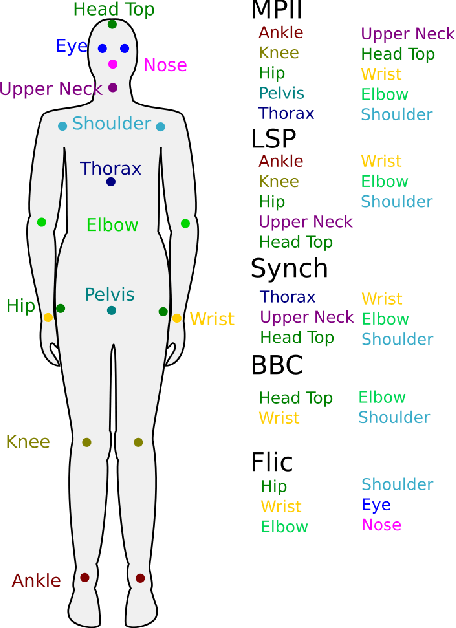
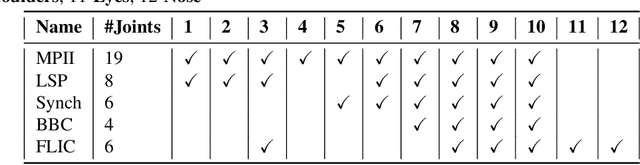

Dealing with incomplete information is a well studied problem in the context of machine learning and computational intelligence. However, in the context of computer vision, the problem has only been studied in specific scenarios (e.g., certain types of occlusions in specific types of images), although it is common to have incomplete information in visual data. This chapter describes the design of an academic competition focusing on inpainting of images and video sequences that was part of the competition program of WCCI2018 and had a satellite event collocated with ECCV2018. The ChaLearn Looking at People Inpainting Challenge aimed at advancing the state of the art on visual inpainting by promoting the development of methods for recovering missing and occluded information from images and video. Three tracks were proposed in which visual inpainting might be helpful but still challenging: human body pose estimation, text overlays removal and fingerprint denoising. This chapter describes the design of the challenge, which includes the release of three novel datasets, and the description of evaluation metrics, baselines and evaluation protocol. The results of the challenge are analyzed and discussed in detail and conclusions derived from this event are outlined.
Explaining First Impressions: Modeling, Recognizing, and Explaining Apparent Personality from Videos
Oct 15, 2018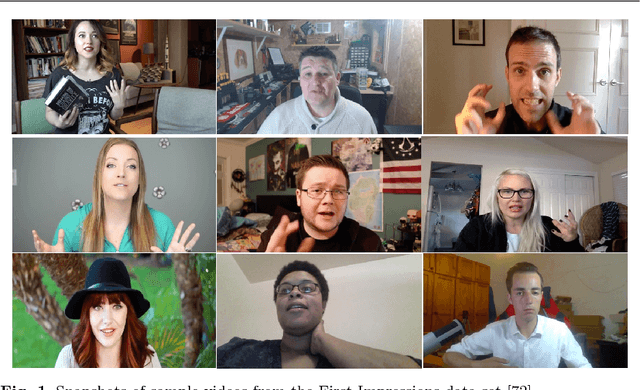
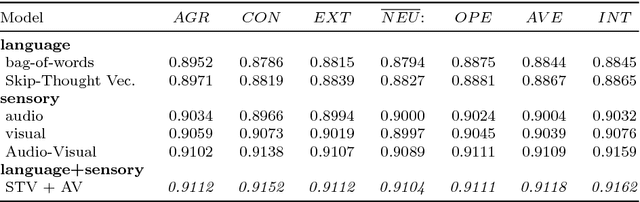
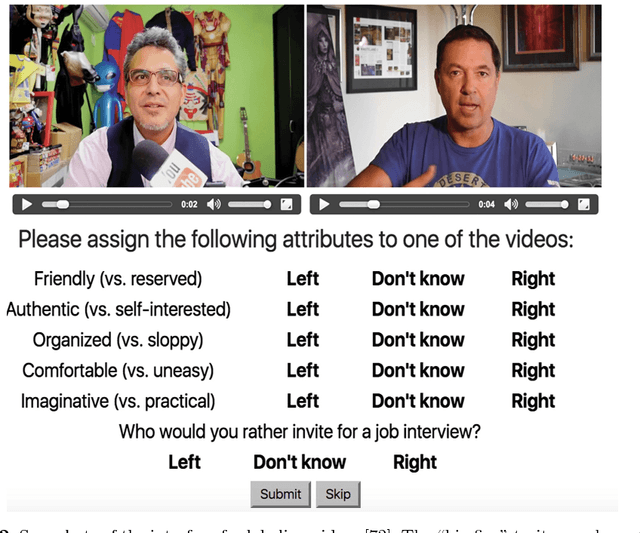
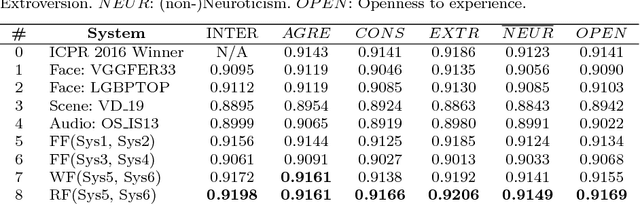
Explainability and interpretability are two critical aspects of decision support systems. Within computer vision, they are critical in certain tasks related to human behavior analysis such as in health care applications. Despite their importance, it is only recently that researchers are starting to explore these aspects. This paper provides an introduction to explainability and interpretability in the context of computer vision with an emphasis on looking at people tasks. Specifically, we review and study those mechanisms in the context of first impressions analysis. To the best of our knowledge, this is the first effort in this direction. Additionally, we describe a challenge we organized on explainability in first impressions analysis from video. We analyze in detail the newly introduced data set, the evaluation protocol, and summarize the results of the challenge. Finally, derived from our study, we outline research opportunities that we foresee will be decisive in the near future for the development of the explainable computer vision field.
From 2D to 3D Geodesic-based Garment Matching
Sep 21, 2018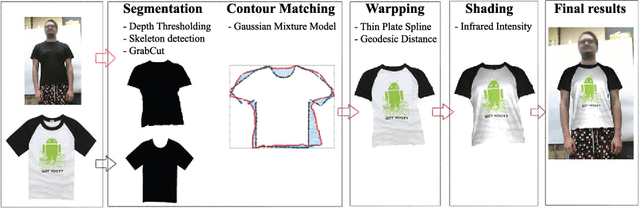

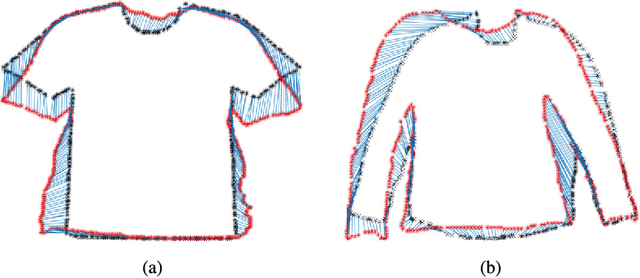
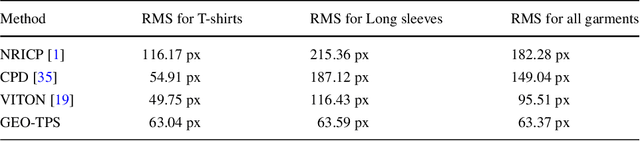
A new approach for 2D to 3D garment retexturing is proposed based on Gaussian mixture models and thin plate splines (TPS). An automatically segmented garment of an individual is matched to a new source garment and rendered, resulting in augmented images in which the target garment has been retextured by using the texture of the source garment. We divide the problem into garment boundary matching based on Gaussian mixture models and then interpolate inner points using surface topology extracted through geodesic paths, which leads to a more realistic result than standard approaches. We evaluated and compared our system quantitatively by mean square error (MSE) and qualitatively using the mean opinion score (MOS), showing the benefits of the proposed methodology on our gathered dataset.
End-to-end Global to Local CNN Learning for Hand Pose Recovery in Depth Data
Apr 11, 2018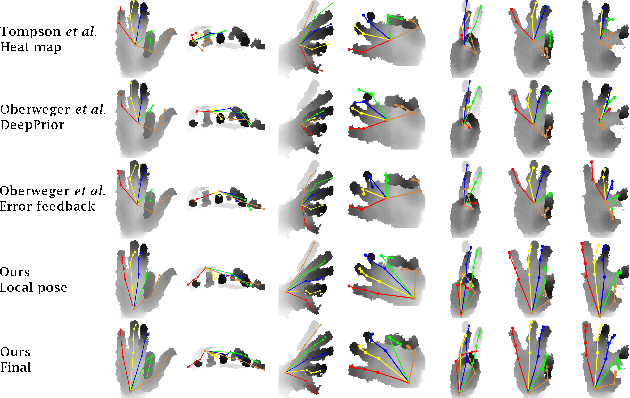

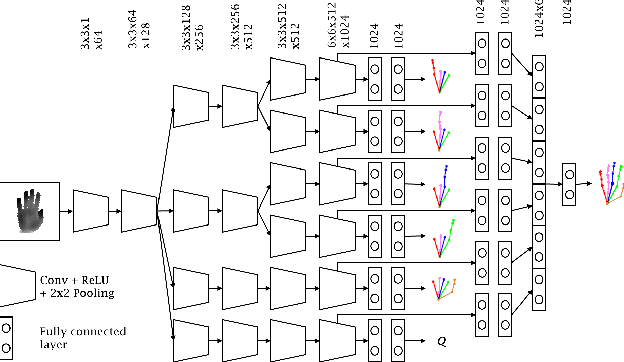

Despite recent advances in 3D pose estimation of human hands, especially thanks to the advent of CNNs and depth cameras, this task is still far from being solved. This is mainly due to the highly non-linear dynamics of fingers, which make hand model training a challenging task. In this paper, we exploit a novel hierarchical tree-like structured CNN, in which branches are trained to become specialized in predefined subsets of hand joints, called local poses. We further fuse local pose features, extracted from hierarchical CNN branches, to learn higher order dependencies among joints in the final pose by end-to-end training. Lastly, the loss function used is also defined to incorporate appearance and physical constraints about doable hand motion and deformation. Finally, we introduce a non-rigid data augmentation approach to increase the amount of training depth data. Experimental results suggest that feeding a tree-shaped CNN, specialized in local poses, into a fusion network for modeling joints correlations and dependencies, helps to increase the precision of final estimations, outperforming state-of-the-art results on NYU and SyntheticHand datasets.
Automatic Recognition of Facial Displays of Unfelt Emotions
Jan 09, 2018
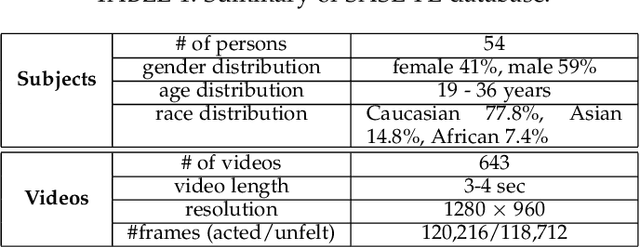

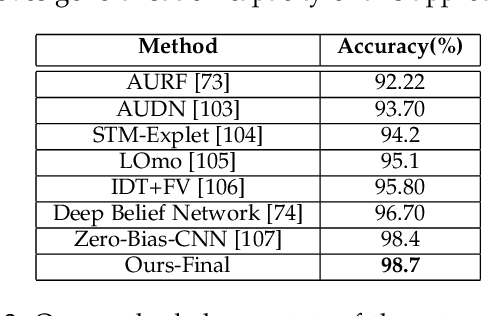
Humans modify their facial expressions in order to communicate their internal states and sometimes to mislead observers regarding their true emotional states. Evidence in experimental psychology shows that discriminative facial responses are short and subtle. This suggests that such behavior would be easier to distinguish when captured in high resolution at an increased frame rate. We are proposing SASE-FE, the first dataset of facial expressions that are either congruent or incongruent with underlying emotion states. We show that overall the problem of recognizing whether facial movements are expressions of authentic emotions or not can be successfully addressed by learning spatio-temporal representations of the data. For this purpose, we propose a method that aggregates features along fiducial trajectories in a deeply learnt space. Performance of the proposed model shows that on average it is easier to distinguish among genuine facial expressions of emotion than among unfelt facial expressions of emotion and that certain emotion pairs such as contempt and disgust are more difficult to distinguish than the rest. Furthermore, the proposed methodology improves state of the art results on CK+ and OULU-CASIA datasets for video emotion recognition, and achieves competitive results when classifying facial action units on BP4D datase.