 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Space Interpolation Beyond Mini-Batch, Beyond Pairs and Beyond Examples
Nov 09, 2023Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Its extensions mostly focus on the definition of interpolation and the space (input or feature) where it takes place, while the augmentation process itself is less studied. In most methods, the number of generated examples is limited to the mini-batch size and the number of examples being interpolated is limited to two (pairs), in the input space. We make progress in this direction by introducing MultiMix, which generates an arbitrarily large number of interpolated examples beyond the mini-batch size and interpolates the entire mini-batch in the embedding space. Effectively, we sample on the entire convex hull of the mini-batch rather than along linear segments between pairs of examples. On sequence data, we further extend to Dense MultiMix. We densely interpolate features and target labels at each spatial location and also apply the loss densely. To mitigate the lack of dense labels, we inherit labels from examples and weight interpolation factors by attention as a measure of confidence. Overall, we increase the number of loss terms per mini-batch by orders of magnitude at little additional cost. This is only possible because of interpolating in the embedding space. We empirically show that our solutions yield significant improvement over state-of-the-art mixup methods on four different benchmarks, despite interpolation being only linear. By analyzing the embedding space, we show that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
Revisiting Transferable Adversarial Image Examples: Attack Categorization, Evaluation Guidelines, and New Insights
Oct 18, 2023



Transferable adversarial examples raise critical security concerns in real-world, black-box attack scenarios. However, in this work, we identify two main problems in common evaluation practices: (1) For attack transferability, lack of systematic, one-to-one attack comparison and fair hyperparameter settings. (2) For attack stealthiness, simply no comparisons. To address these problems, we establish new evaluation guidelines by (1) proposing a novel attack categorization strategy and conducting systematic and fair intra-category analyses on transferability, and (2) considering diverse imperceptibility metrics and finer-grained stealthiness characteristics from the perspective of attack traceback. To this end, we provide the first large-scale evaluation of transferable adversarial examples on ImageNet, involving 23 representative attacks against 9 representative defenses. Our evaluation leads to a number of new insights, including consensus-challenging ones: (1) Under a fair attack hyperparameter setting, one early attack method, DI, actually outperforms all the follow-up methods. (2) A state-of-the-art defense, DiffPure, actually gives a false sense of (white-box) security since it is indeed largely bypassed by our (black-box) transferable attacks. (3) Even when all attacks are bounded by the same $L_p$ norm, they lead to dramatically different stealthiness performance, which negatively correlates with their transferability performance. Overall, our work demonstrates that existing problematic evaluations have indeed caused misleading conclusions and missing points, and as a result, hindered the assessment of the actual progress in this field.
Towards Good Practices in Evaluating Transfer Adversarial Attacks
Nov 17, 2022
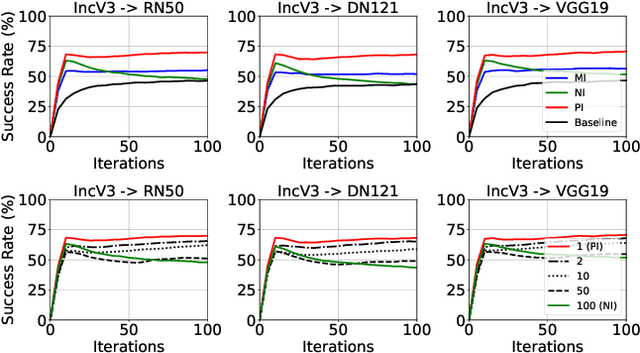

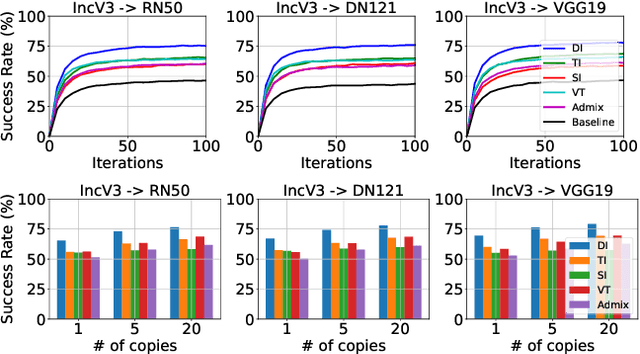
Transfer adversarial attacks raise critical security concerns in real-world, black-box scenarios. However, the actual progress of attack methods is difficult to assess due to two main limitations in existing evaluations. First, existing evaluations are unsystematic and sometimes unfair since new methods are often directly added to old ones without complete comparisons to similar methods. Second, existing evaluations mainly focus on transferability but overlook another key attack property: stealthiness. In this work, we design good practices to address these limitations. We first introduce a new attack categorization, which enables our systematic analyses of similar attacks in each specific category. Our analyses lead to new findings that complement or even challenge existing knowledge. Furthermore, we comprehensively evaluate 23 representative attacks against 9 defenses on ImageNet. We pay particular attention to stealthiness, by adopting diverse imperceptibility metrics and looking into new, finer-grained characteristics. Our evaluation reveals new important insights: 1) Transferability is highly contextual, and some white-box defenses may give a false sense of security since they are actually vulnerable to (black-box) transfer attacks; 2) All transfer attacks are less stealthy, and their stealthiness can vary dramatically under the same $L_{\infty}$ bound.
Intrinsic Dimensionality Estimation within Tight Localities: A Theoretical and Experimental Analysis
Sep 29, 2022
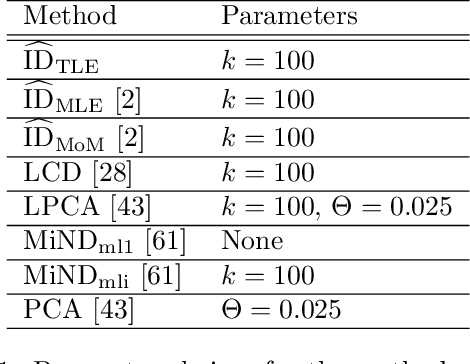
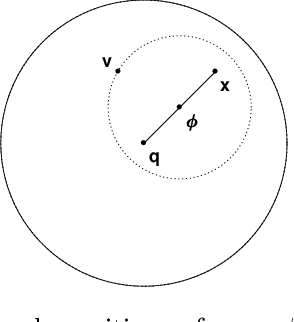
Accurate estimation of Intrinsic Dimensionality (ID) is of crucial importance in many data mining and machine learning tasks, including dimensionality reduction, outlier detection, similarity search and subspace clustering. However, since their convergence generally requires sample sizes (that is, neighborhood sizes) on the order of hundreds of points, existing ID estimation methods may have only limited usefulness for applications in which the data consists of many natural groups of small size. In this paper, we propose a local ID estimation strategy stable even for `tight' localities consisting of as few as 20 sample points. The estimator applies MLE techniques over all available pairwise distances among the members of the sample, based on a recent extreme-value-theoretic model of intrinsic dimensionality, the Local Intrinsic Dimension (LID). Our experimental results show that our proposed estimation technique can achieve notably smaller variance, while maintaining comparable levels of bias, at much smaller sample sizes than state-of-the-art estimators.
Teach me how to Interpolate a Myriad of Embeddings
Jun 29, 2022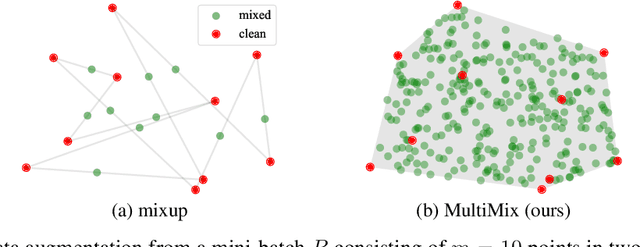
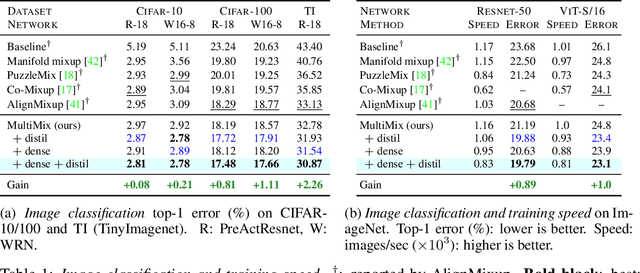
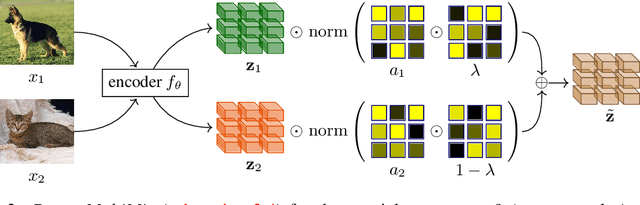
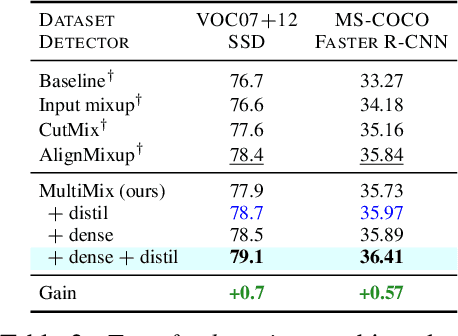
Mixup refers to interpolation-based data augmentation, originally motivated as a way to go beyond empirical risk minimization (ERM). Yet, its extensions focus on the definition of interpolation and the space where it takes place, while the augmentation itself is less studied: For a mini-batch of size $m$, most methods interpolate between $m$ pairs with a single scalar interpolation factor $\lambda$. In this work, we make progress in this direction by introducing MultiMix, which interpolates an arbitrary number $n$ of tuples, each of length $m$, with one vector $\lambda$ per tuple. On sequence data, we further extend to dense interpolation and loss computation over all spatial positions. Overall, we increase the number of tuples per mini-batch by orders of magnitude at little additional cost. This is possible by interpolating at the very last layer before the classifier. Finally, to address inconsistencies due to linear target interpolation, we introduce a self-distillation approach to generate and interpolate synthetic targets. We empirically show that our contributions result in significant improvement over state-of-the-art mixup methods on four benchmarks. By analyzing the embedding space, we observe that the classes are more tightly clustered and uniformly spread over the embedding space, thereby explaining the improved behavior.
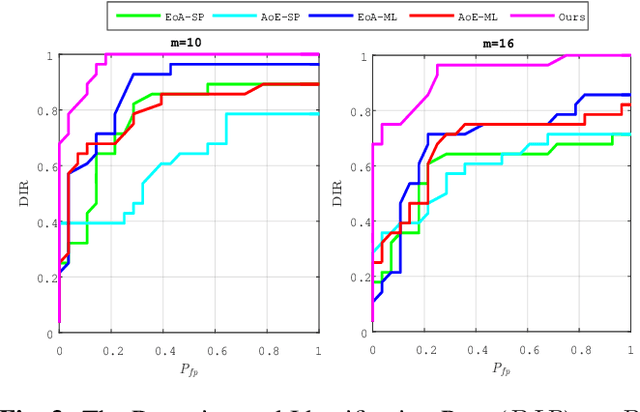
AggNet: Learning to Aggregate Faces for Group Membership Verification
Jun 17, 2022

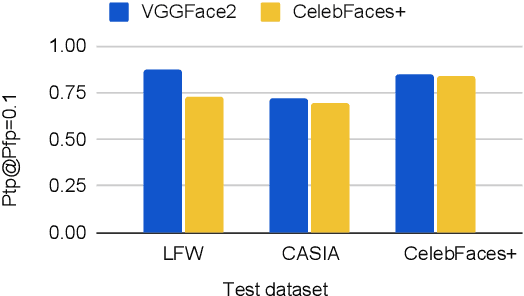
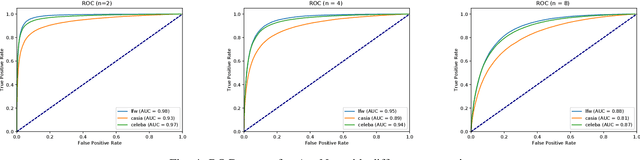
In some face recognition applications, we are interested to verify whether an individual is a member of a group, without revealing their identity. Some existing methods, propose a mechanism for quantizing precomputed face descriptors into discrete embeddings and aggregating them into one group representation. However, this mechanism is only optimized for a given closed set of individuals and needs to learn the group representations from scratch every time the groups are changed. In this paper, we propose a deep architecture that jointly learns face descriptors and the aggregation mechanism for better end-to-end performances. The system can be applied to new groups with individuals never seen before and the scheme easily manages new memberships or membership endings. We show through experiments on multiple large-scale wild-face datasets, that the proposed method leads to higher verification performance compared to other baselines.
It Takes Two to Tango: Mixup for Deep Metric Learning
Jun 09, 2021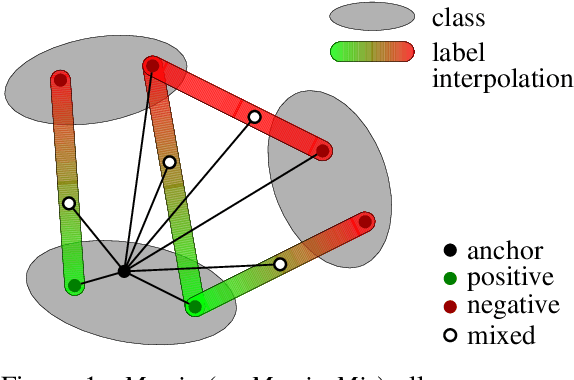

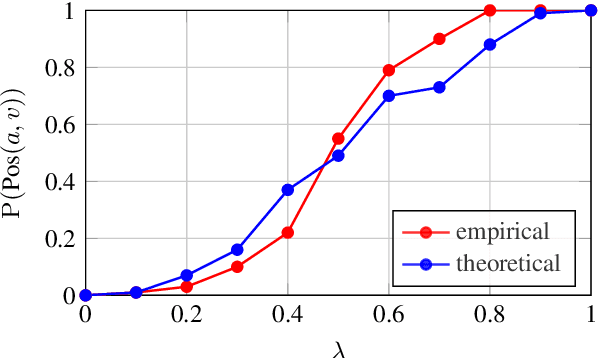
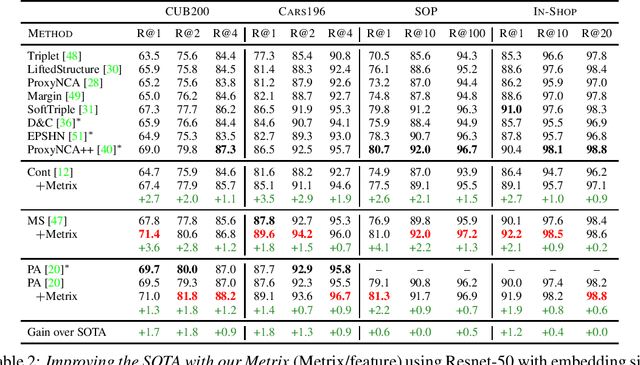
Metric learning involves learning a discriminative representation such that embeddings of similar classes are encouraged to be close, while embeddings of dissimilar classes are pushed far apart. State-of-the-art methods focus mostly on sophisticated loss functions or mining strategies. On the one hand, metric learning losses consider two or more examples at a time. On the other hand, modern data augmentation methods for classification consider two or more examples at a time. The combination of the two ideas is under-studied. In this work, we aim to bridge this gap and improve representations using mixup, which is a powerful data augmentation approach interpolating two or more examples and corresponding target labels at a time. This task is challenging because, unlike classification, the loss functions used in metric learning are not additive over examples, so the idea of interpolating target labels is not straightforward. To the best of our knowledge, we are the first to investigate mixing examples and target labels for deep metric learning. We develop a generalized formulation that encompasses existing metric learning loss functions and modify it to accommodate for mixup, introducing Metric Mix, or Metrix. We show that mixing inputs, intermediate representations or embeddings along with target labels significantly improves representations and outperforms state-of-the-art metric learning methods on four benchmark datasets.
AlignMix: Improving representation by interpolating aligned features
Mar 29, 2021
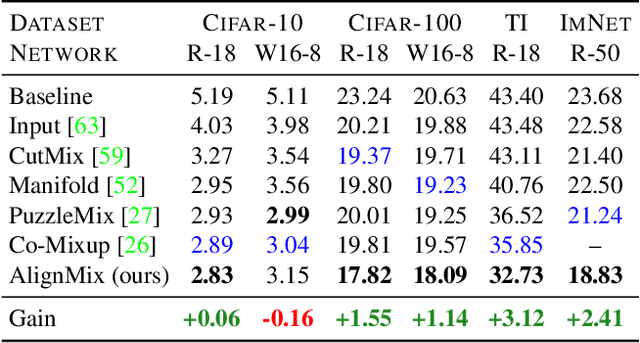
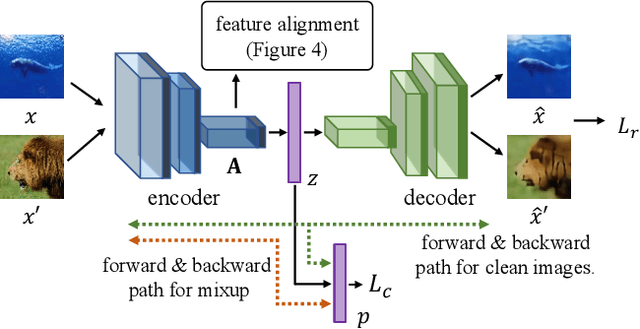
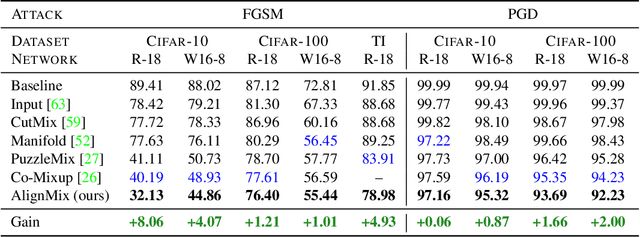
Mixup is a powerful data augmentation method that interpolates between two or more examples in the input or feature space and between the corresponding target labels. Many recent mixup methods focus on cutting and pasting two or more objects into one image, which is more about efficient processing than interpolation. However, how to best interpolate images is not well defined. In this sense, mixup has been connected to autoencoders, because often autoencoders "interpolate well", for instance generating an image that continuously deforms into another. In this work, we revisit mixup from the interpolation perspective and introduce AlignMix, where we geometrically align two images in the feature space. The correspondences allow us to interpolate between two sets of features, while keeping the locations of one set. Interestingly, this gives rise to a situation where mixup retains mostly the geometry or pose of one image and the texture of the other, connecting it to style transfer. More than that, we show that an autoencoder can still improve representation learning under mixup, without the classifier ever seeing decoded images. AlignMix outperforms state-of-the-art mixup methods on five different benchmarks.
Joint Learning of Assignment and Representation for Biometric Group Membership
Feb 24, 2020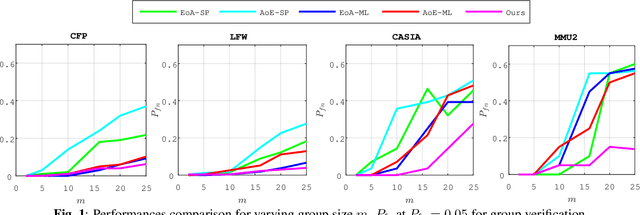

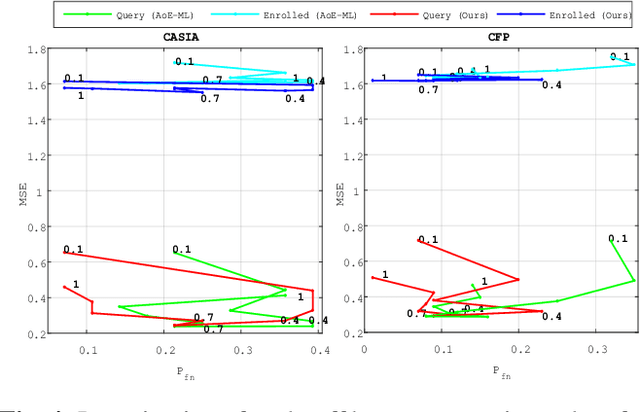
This paper proposes a framework for group membership protocols preventing the curious but honest server from reconstructing the enrolled biometric signatures and inferring the identity of querying clients. This framework learns the embedding parameters, group representations and assignments simultaneously. Experiments show the trade-off between security/privacy and verification/identification performances.
Group Membership Verification with Privacy: Sparse or Dense?
Feb 24, 2020


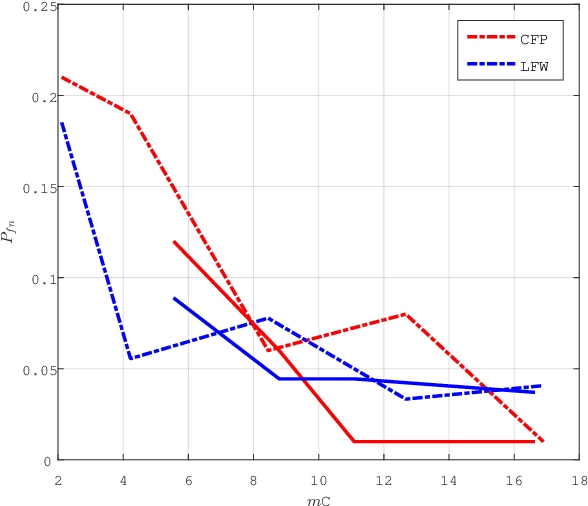
Group membership verification checks if a biometric trait corresponds to one member of a group without revealing the identity of that member. Recent contributions provide privacy for group membership protocols through the joint use of two mechanisms: quantizing templates into discrete embeddings and aggregating several templates into one group representation. However, this scheme has one drawback: the data structure representing the group has a limited size and cannot recognize noisy queries when many templates are aggregated. Moreover, the sparsity of the embeddings seemingly plays a crucial role on the performance verification. This paper proposes a mathematical model for group membership verification allowing to reveal the impact of sparsity on both security, compactness, and verification performances. This model bridges the gap towards a Bloom filter robust to noisy queries. It shows that a dense solution is more competitive unless the queries are almost noiseless.