 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Interpretable Features in Computational Super-Resolution microscopy via Regularized Latent Search
May 29, 2024Supervised deep learning approaches can artificially increase the resolution of microscopy images by learning a mapping between two image resolutions or modalities. However, such methods often require a large set of hard-to-get low-res/high-res image pairs and produce synthetic images with a moderate increase in resolution. Conversely, recent methods based on GAN latent search offered a drastic increase in resolution without the need of paired images. However, they offer limited reconstruction of the high-resolution image interpretable features. Here, we propose a robust super-resolution method based on regularized latent search~(RLS) that offers an actionable balance between fidelity to the ground-truth and realism of the recovered image given a distribution prior. The latter allows to split the analysis of a low-resolution image into a computational super-resolution task performed by deep learning followed by a quantification task performed by a handcrafted algorithm and based on interpretable biological features. This two-step process holds potential for various applications such as diagnostics on mobile devices, where the main aim is not to recover the high-resolution details of a specific sample but rather to obtain high-resolution images that preserve explainable and quantifiable differences between conditions.
Super-Resolution through StyleGAN Regularized Latent Search: A Realism-Fidelity Trade-off
Nov 28, 2023This paper addresses the problem of super-resolution: constructing a highly resolved (HR) image from a low resolved (LR) one. Recent unsupervised approaches search the latent space of a StyleGAN pre-trained on HR images, for the image that best downscales to the input LR image. However, they tend to produce out-of-domain images and fail to accurately reconstruct HR images that are far from the original domain. Our contribution is twofold. Firstly, we introduce a new regularizer to constrain the search in the latent space, ensuring that the inverted code lies in the original image manifold. Secondly, we further enhanced the reconstruction through expanding the image prior around the optimal latent code. Our results show that the proposed approach recovers realistic high-quality images for large magnification factors. Furthermore, for low magnification factors, it can still reconstruct details that the generator could not have produced otherwise. Altogether, our approach achieves a good trade-off between fidelity and realism for the super-resolution task.
AggNet: Learning to Aggregate Faces for Group Membership Verification
Jun 17, 2022

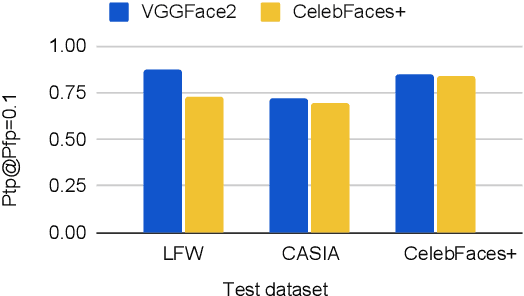
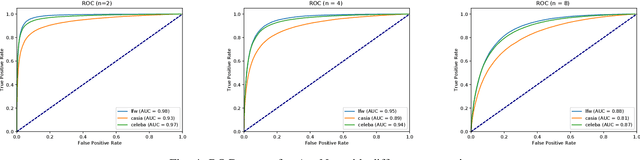
In some face recognition applications, we are interested to verify whether an individual is a member of a group, without revealing their identity. Some existing methods, propose a mechanism for quantizing precomputed face descriptors into discrete embeddings and aggregating them into one group representation. However, this mechanism is only optimized for a given closed set of individuals and needs to learn the group representations from scratch every time the groups are changed. In this paper, we propose a deep architecture that jointly learns face descriptors and the aggregation mechanism for better end-to-end performances. The system can be applied to new groups with individuals never seen before and the scheme easily manages new memberships or membership endings. We show through experiments on multiple large-scale wild-face datasets, that the proposed method leads to higher verification performance compared to other baselines.
Joint Learning of Assignment and Representation for Biometric Group Membership
Feb 24, 2020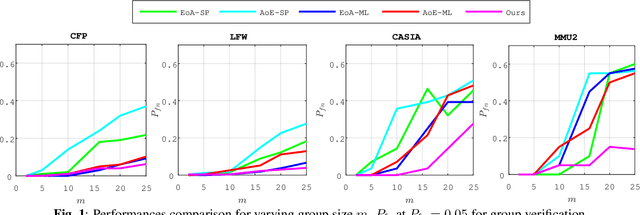

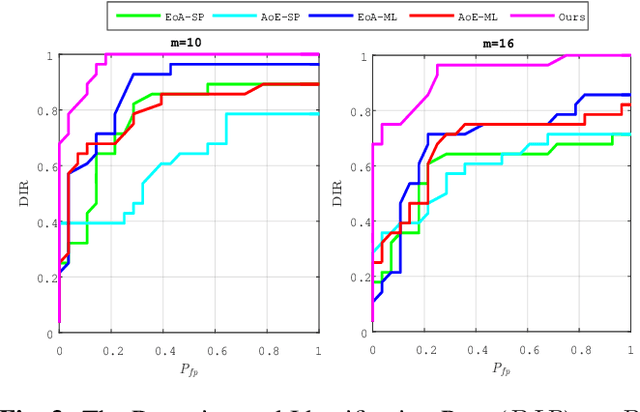
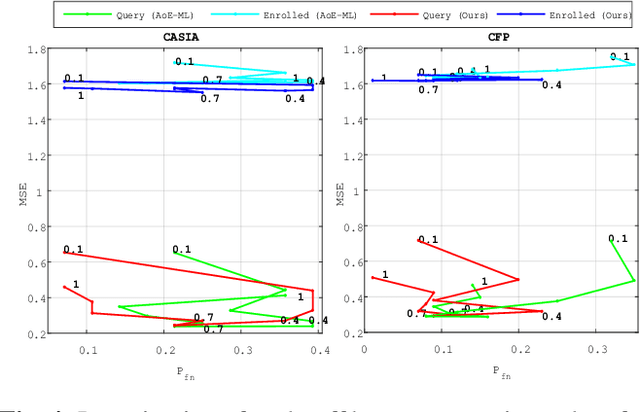
This paper proposes a framework for group membership protocols preventing the curious but honest server from reconstructing the enrolled biometric signatures and inferring the identity of querying clients. This framework learns the embedding parameters, group representations and assignments simultaneously. Experiments show the trade-off between security/privacy and verification/identification performances.
Group Membership Verification with Privacy: Sparse or Dense?
Feb 24, 2020


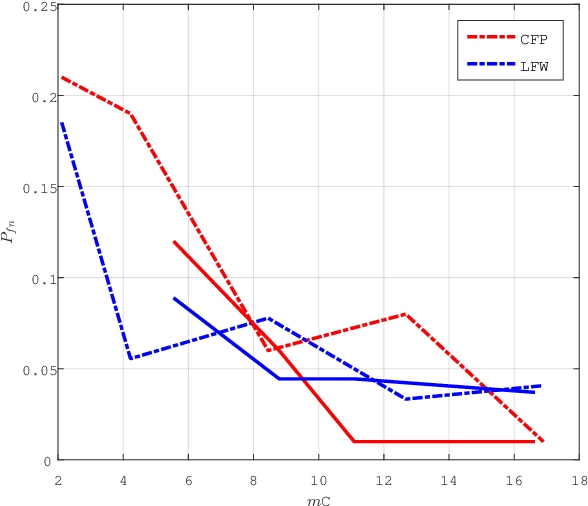
Group membership verification checks if a biometric trait corresponds to one member of a group without revealing the identity of that member. Recent contributions provide privacy for group membership protocols through the joint use of two mechanisms: quantizing templates into discrete embeddings and aggregating several templates into one group representation. However, this scheme has one drawback: the data structure representing the group has a limited size and cannot recognize noisy queries when many templates are aggregated. Moreover, the sparsity of the embeddings seemingly plays a crucial role on the performance verification. This paper proposes a mathematical model for group membership verification allowing to reveal the impact of sparsity on both security, compactness, and verification performances. This model bridges the gap towards a Bloom filter robust to noisy queries. It shows that a dense solution is more competitive unless the queries are almost noiseless.
Privacy Preserving Group Membership Verification and Identification
Apr 23, 2019


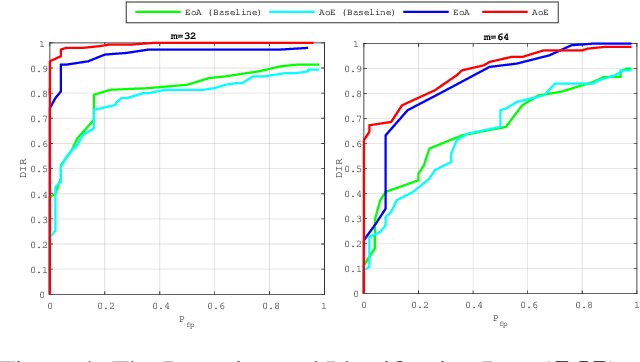
When convoking privacy, group membership verification checks if a biometric trait corresponds to one member of a group without revealing the identity of that member. Similarly, group membership identification states which group the individual belongs to, without knowing his/her identity. A recent contribution provides privacy and security for group membership protocols through the joint use of two mechanisms: quantizing biometric templates into discrete embeddings and aggregating several templates into one group representation. This paper significantly improves that contribution because it jointly learns how to embed and aggregate instead of imposing fixed and hard coded rules. This is demonstrated by exposing the mathematical underpinnings of the learning stage before showing the improvements through an extensive series of experiments targeting face recognition. Overall, experiments show that learning yields an excellent trade-off between security /privacy and verification /identification performances.