 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?
Feb 26, 2026Open-vocabulary segmentation (OVS) extends the zero-shot recognition capabilities of vision-language models (VLMs) to pixel-level prediction, enabling segmentation of arbitrary categories specified by text prompts. Despite recent progress, OVS lags behind fully supervised approaches due to two challenges: the coarse image-level supervision used to train VLMs and the semantic ambiguity of natural language. We address these limitations by introducing a few-shot setting that augments textual prompts with a support set of pixel-annotated images. Building on this, we propose a retrieval-augmented test-time adapter that learns a lightweight, per-image classifier by fusing textual and visual support features. Unlike prior methods relying on late, hand-crafted fusion, our approach performs learned, per-query fusion, achieving stronger synergy between modalities. The method supports continually expanding support sets, and applies to fine-grained tasks such as personalized segmentation. Experiments show that we significantly narrow the gap between zero-shot and supervised segmentation while preserving open-vocabulary ability.
REGLUE Your Latents with Global and Local Semantics for Entangled Diffusion
Dec 18, 2025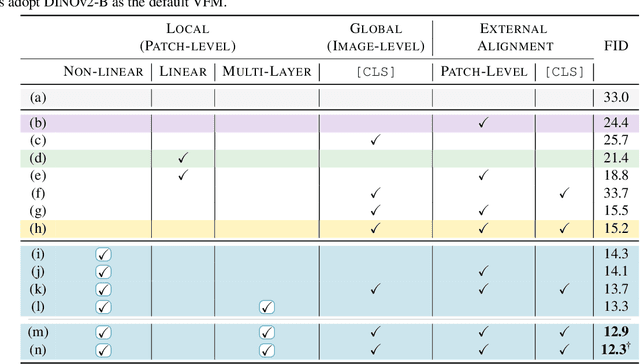

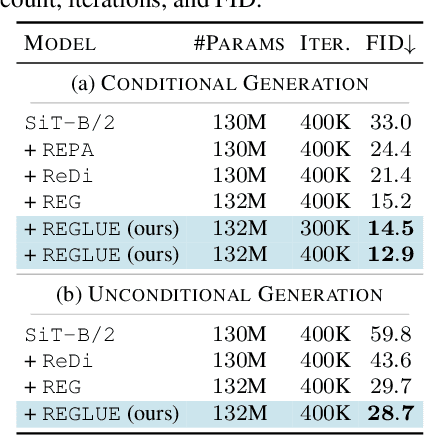
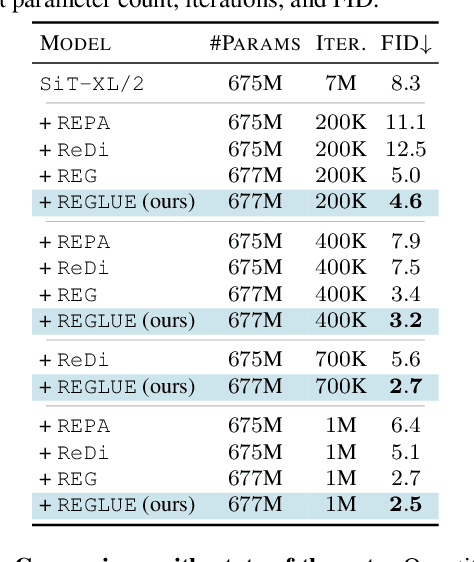
Latent diffusion models (LDMs) achieve state-of-the-art image synthesis, yet their reconstruction-style denoising objective provides only indirect semantic supervision: high-level semantics emerge slowly, requiring longer training and limiting sample quality. Recent works inject semantics from Vision Foundation Models (VFMs) either externally via representation alignment or internally by jointly modeling only a narrow slice of VFM features inside the diffusion process, under-utilizing the rich, nonlinear, multi-layer spatial semantics available. We introduce REGLUE (Representation Entanglement with Global-Local Unified Encoding), a unified latent diffusion framework that jointly models (i) VAE image latents, (ii) compact local (patch-level) VFM semantics, and (iii) a global (image-level) [CLS] token within a single SiT backbone. A lightweight convolutional semantic compressor nonlinearly aggregates multi-layer VFM features into a low-dimensional, spatially structured representation, which is entangled with the VAE latents in the diffusion process. An external alignment loss further regularizes internal representations toward frozen VFM targets. On ImageNet 256x256, REGLUE consistently improves FID and accelerates convergence over SiT-B/2 and SiT-XL/2 baselines, as well as over REPA, ReDi, and REG. Extensive experiments show that (a) spatial VFM semantics are crucial, (b) non-linear compression is key to unlocking their full benefit, and (c) global tokens and external alignment act as complementary, lightweight enhancements within our global-local-latent joint modeling framework. The code is available at https://github.com/giorgospets/reglue .
Attention, Please! Revisiting Attentive Probing for Masked Image Modeling
Jun 11, 2025As fine-tuning (FT) becomes increasingly impractical at scale, probing is emerging as the preferred evaluation protocol for self-supervised learning (SSL). Yet, the standard linear probing (LP) fails to adequately reflect the potential of models trained with Masked Image Modeling (MIM), due to the distributed nature of patch tokens. This motivates the need for attentive probing, an alternative that uses attention to selectively aggregate patch-level features. Despite its growing adoption, attentive probing remains under-explored, with existing methods suffering from excessive parameterization and poor computational efficiency. In this work, we revisit attentive probing through the lens of the accuracy-efficiency trade-off. We conduct a systematic study of existing methods, analyzing their mechanisms and benchmarking their performance. We introduce efficient probing (EP), a multi-query cross-attention mechanism that eliminates redundant projections, reduces the number of trainable parameters, and achieves up to a 10$\times$ speed-up over conventional multi-head attention. Despite its simplicity, EP outperforms LP and prior attentive probing approaches across seven benchmarks, generalizes well beyond MIM to diverse pre-training paradigms, produces interpretable attention maps, and achieves strong gains in low-shot and layer-wise settings. Code available at https://github.com/billpsomas/efficient-probing.
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024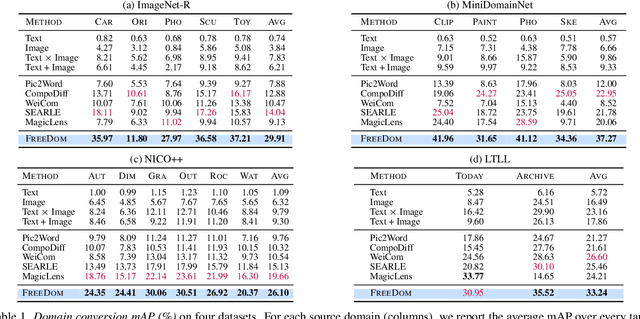
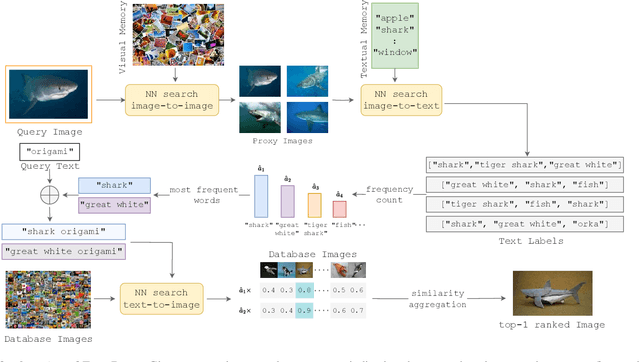


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
Composed Image Retrieval for Remote Sensing
May 29, 2024
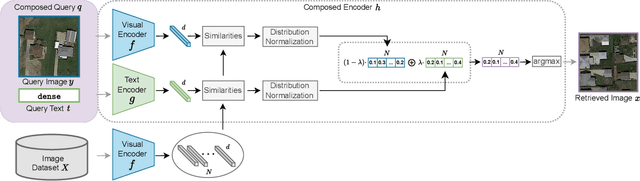


This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
Evaluation of Resource-Efficient Crater Detectors on Embedded Systems
May 27, 2024
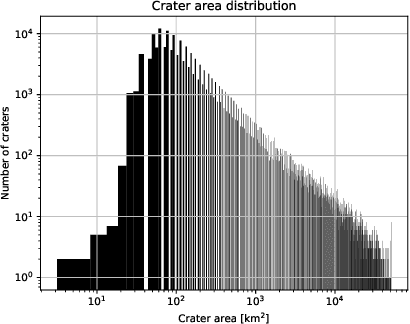
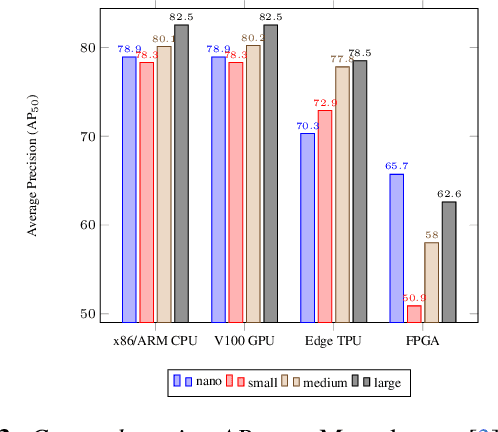
Real-time analysis of Martian craters is crucial for mission-critical operations, including safe landings and geological exploration. This work leverages the latest breakthroughs for on-the-edge crater detection aboard spacecraft. We rigorously benchmark several YOLO networks using a Mars craters dataset, analyzing their performance on embedded systems with a focus on optimization for low-power devices. We optimize this process for a new wave of cost-effective, commercial-off-the-shelf-based smaller satellites. Implementations on diverse platforms, including Google Coral Edge TPU, AMD Versal SoC VCK190, Nvidia Jetson Nano and Jetson AGX Orin, undergo a detailed trade-off analysis. Our findings identify optimal network-device pairings, enhancing the feasibility of crater detection on resource-constrained hardware and setting a new precedent for efficient and resilient extraterrestrial imaging. Code at: https://github.com/billpsomas/mars_crater_detection.
Keep It SimPool: Who Said Supervised Transformers Suffer from Attention Deficit?
Sep 13, 2023
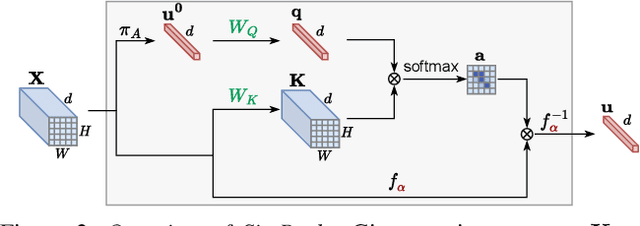
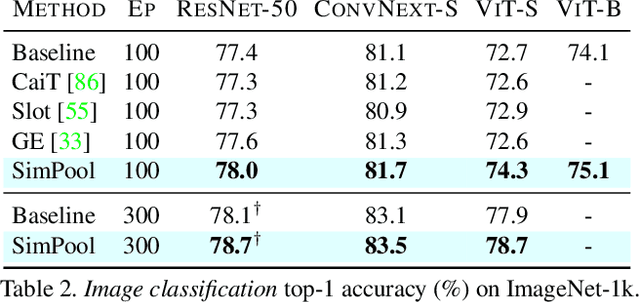
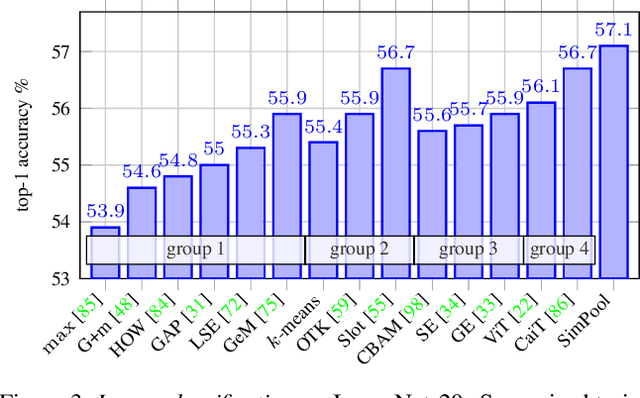
Convolutional networks and vision transformers have different forms of pairwise interactions, pooling across layers and pooling at the end of the network. Does the latter really need to be different? As a by-product of pooling, vision transformers provide spatial attention for free, but this is most often of low quality unless self-supervised, which is not well studied. Is supervision really the problem? In this work, we develop a generic pooling framework and then we formulate a number of existing methods as instantiations. By discussing the properties of each group of methods, we derive SimPool, a simple attention-based pooling mechanism as a replacement of the default one for both convolutional and transformer encoders. We find that, whether supervised or self-supervised, this improves performance on pre-training and downstream tasks and provides attention maps delineating object boundaries in all cases. One could thus call SimPool universal. To our knowledge, we are the first to obtain attention maps in supervised transformers of at least as good quality as self-supervised, without explicit losses or modifying the architecture. Code at: https://github.com/billpsomas/simpool.
* ICCV 2023. Code and models: https://github.com/billpsomas/simpool
What to Hide from Your Students: Attention-Guided Masked Image Modeling
Mar 23, 2022
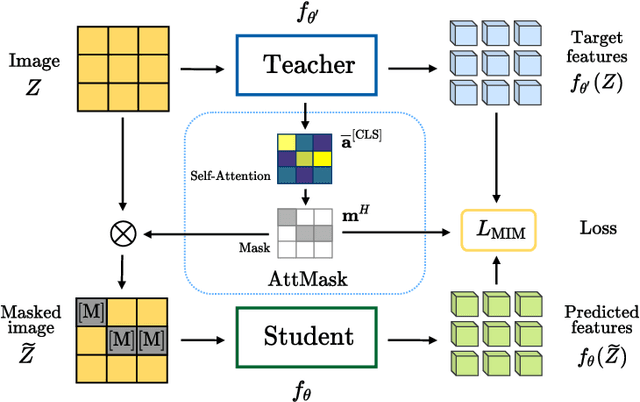
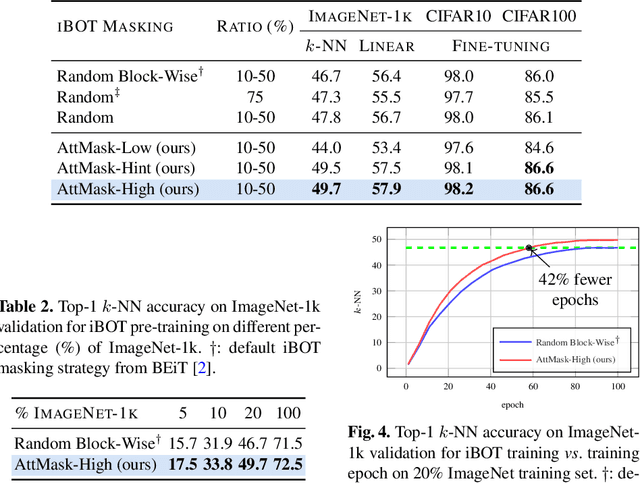

Transformers and masked language modeling are quickly being adopted and explored in computer vision as vision transformers and masked image modeling (MIM). In this work, we argue that image token masking is fundamentally different from token masking in text, due to the amount and correlation of tokens in an image. In particular, to generate a challenging pretext task for MIM, we advocate a shift from random masking to informed masking. We develop and exhibit this idea in the context of distillation-based MIM, where a teacher transformer encoder generates an attention map, which we use to guide masking for the student encoder. We thus introduce a novel masking strategy, called attention-guided masking (AttMask), and we demonstrate its effectiveness over random masking for dense distillation-based MIM as well as plain distillation-based self-supervised learning on classification tokens. We confirm that AttMask accelerates the learning process and improves the performance on a variety of downstream tasks.
It Takes Two to Tango: Mixup for Deep Metric Learning
Jun 09, 2021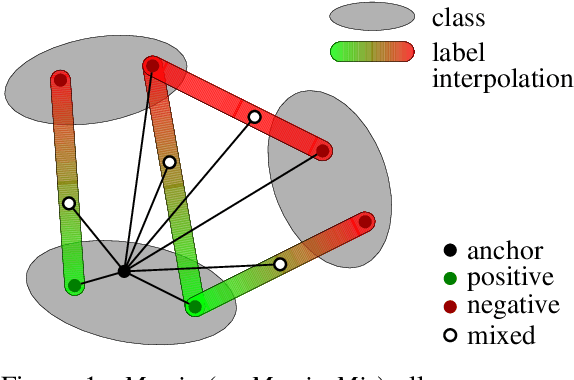

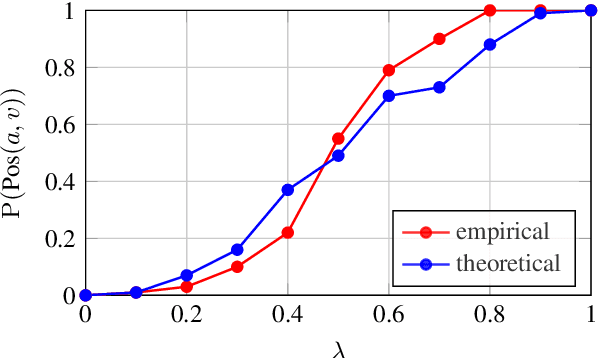
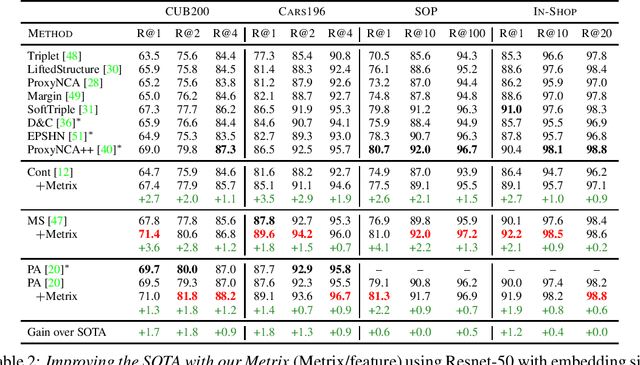
Metric learning involves learning a discriminative representation such that embeddings of similar classes are encouraged to be close, while embeddings of dissimilar classes are pushed far apart. State-of-the-art methods focus mostly on sophisticated loss functions or mining strategies. On the one hand, metric learning losses consider two or more examples at a time. On the other hand, modern data augmentation methods for classification consider two or more examples at a time. The combination of the two ideas is under-studied. In this work, we aim to bridge this gap and improve representations using mixup, which is a powerful data augmentation approach interpolating two or more examples and corresponding target labels at a time. This task is challenging because, unlike classification, the loss functions used in metric learning are not additive over examples, so the idea of interpolating target labels is not straightforward. To the best of our knowledge, we are the first to investigate mixing examples and target labels for deep metric learning. We develop a generalized formulation that encompasses existing metric learning loss functions and modify it to accommodate for mixup, introducing Metric Mix, or Metrix. We show that mixing inputs, intermediate representations or embeddings along with target labels significantly improves representations and outperforms state-of-the-art metric learning methods on four benchmark datasets.