 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Image Retrieval for Training-Free Domain Conversion
Paper and Code
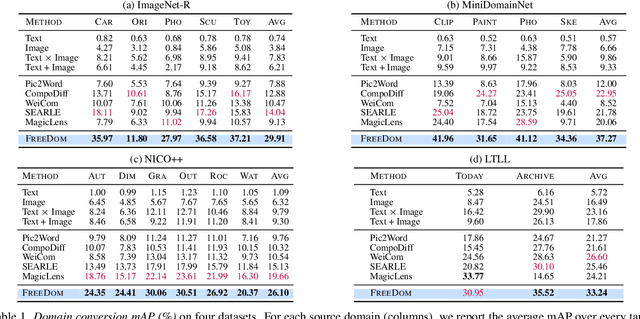
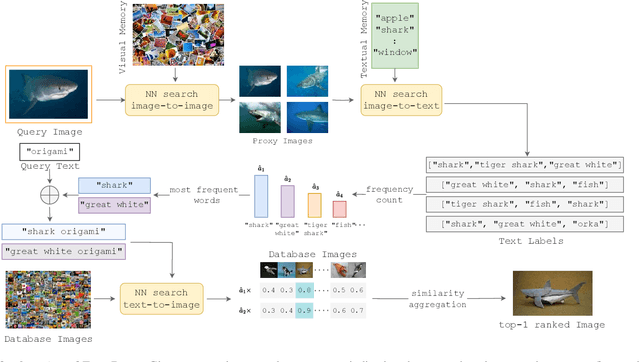


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom