 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Meets Post-hoc Interpretability: A Mathematical Perspective
Feb 05, 2024
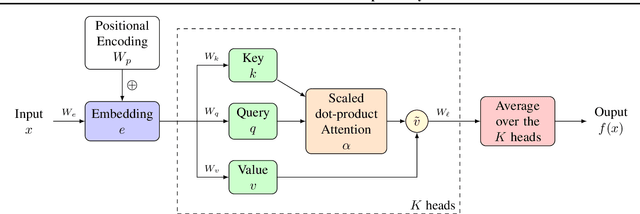
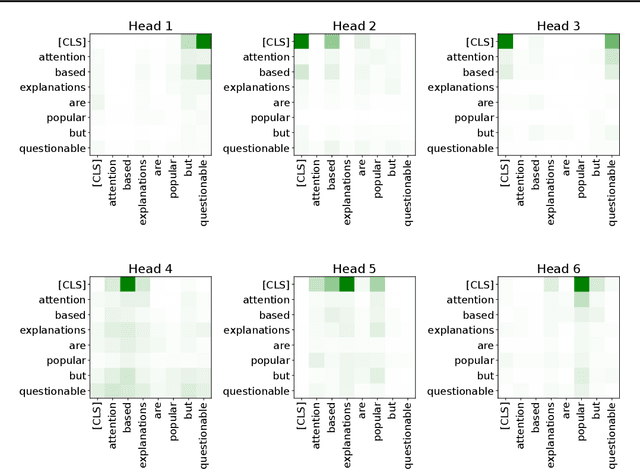
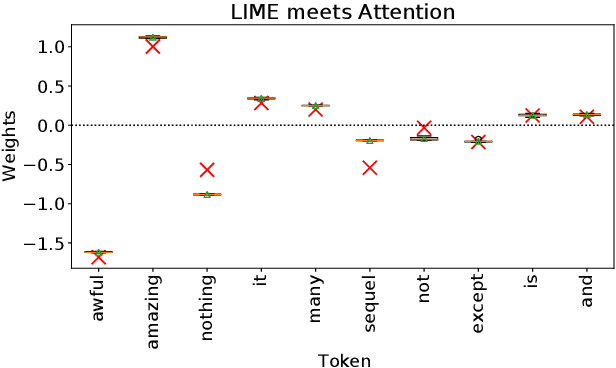
Attention-based architectures, in particular transformers, are at the heart of a technological revolution. Interestingly, in addition to helping obtain state-of-the-art results on a wide range of applications, the attention mechanism intrinsically provides meaningful insights on the internal behavior of the model. Can these insights be used as explanations? Debate rages on. In this paper, we mathematically study a simple attention-based architecture and pinpoint the differences between post-hoc and attention-based explanations. We show that they provide quite different results, and that, despite their limitations, post-hoc methods are capable of capturing more useful insights than merely examining the attention weights.
Faithful and Robust Local Interpretability for Textual Predictions
Oct 30, 2023



Interpretability is essential for machine learning models to be trusted and deployed in critical domains. However, existing methods for interpreting text models are often complex, lack solid mathematical foundations, and their performance is not guaranteed. In this paper, we propose FRED (Faithful and Robust Explainer for textual Documents), a novel method for interpreting predictions over text. FRED identifies key words in a document that significantly impact the prediction when removed. We establish the reliability of FRED through formal definitions and theoretical analyses on interpretable classifiers. Additionally, our empirical evaluation against state-of-the-art methods demonstrates the effectiveness of FRED in providing insights into text models.
Understanding Post-hoc Explainers: The Case of Anchors
Mar 15, 2023In many scenarios, the interpretability of machine learning models is a highly required but difficult task. To explain the individual predictions of such models, local model-agnostic approaches have been proposed. However, the process generating the explanations can be, for a user, as mysterious as the prediction to be explained. Furthermore, interpretability methods frequently lack theoretical guarantees, and their behavior on simple models is frequently unknown. While it is difficult, if not impossible, to ensure that an explainer behaves as expected on a cutting-edge model, we can at least ensure that everything works on simple, already interpretable models. In this paper, we present a theoretical analysis of Anchors (Ribeiro et al., 2018): a popular rule-based interpretability method that highlights a small set of words to explain a text classifier's decision. After formalizing its algorithm and providing useful insights, we demonstrate mathematically that Anchors produces meaningful results when used with linear text classifiers on top of a TF-IDF vectorization. We believe that our analysis framework can aid in the development of new explainability methods based on solid theoretical foundations.
Comparing Feature Importance and Rule Extraction for Interpretability on Text Data
Jul 04, 2022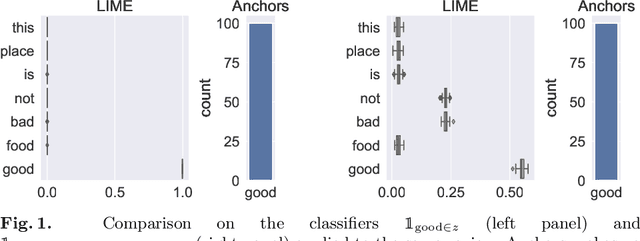
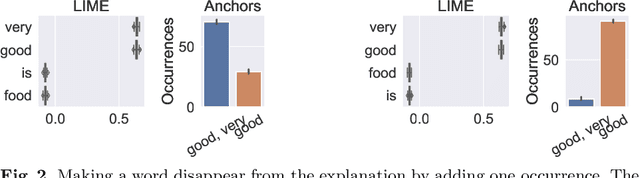
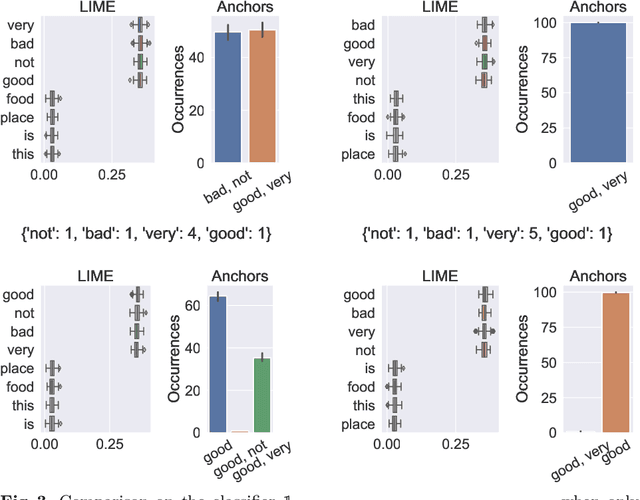
Complex machine learning algorithms are used more and more often in critical tasks involving text data, leading to the development of interpretability methods. Among local methods, two families have emerged: those computing importance scores for each feature and those extracting simple logical rules. In this paper we show that using different methods can lead to unexpectedly different explanations, even when applied to simple models for which we would expect qualitative coincidence. To quantify this effect, we propose a new approach to compare explanations produced by different methods.
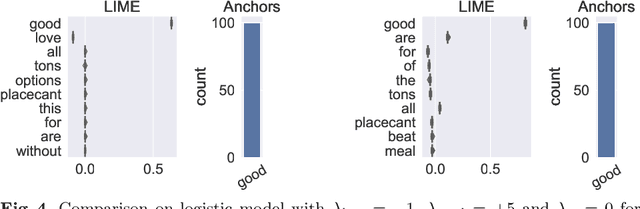
A Sea of Words: An In-Depth Analysis of Anchors for Text Data
May 27, 2022

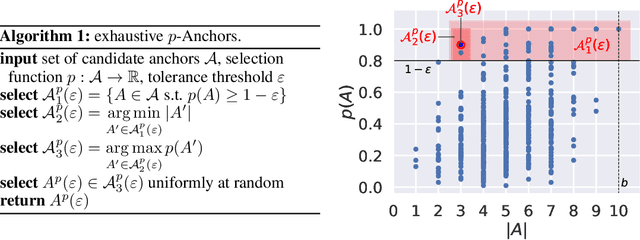
Anchors [Ribeiro et al. (2018)] is a post-hoc, rule-based interpretability method. For text data, it proposes to explain a decision by highlighting a small set of words (an anchor) such that the model to explain has similar outputs when they are present in a document. In this paper, we present the first theoretical analysis of Anchors, considering that the search for the best anchor is exhaustive. We leverage this analysis to gain insights on the behavior of Anchors on simple models, including elementary if-then rules and linear classifiers.
SMACE: A New Method for the Interpretability of Composite Decision Systems
Nov 16, 2021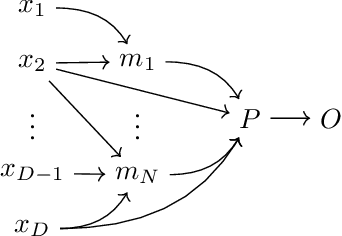
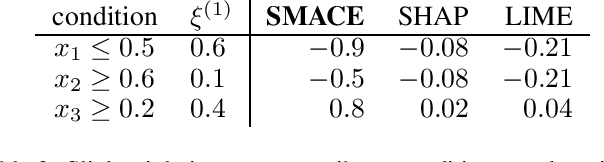
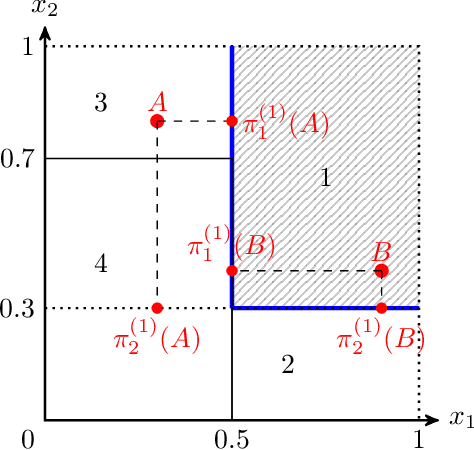
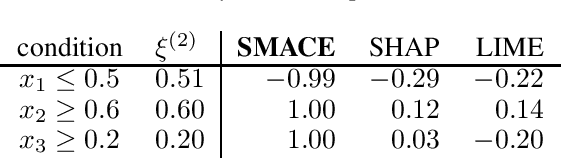
Interpretability is a pressing issue for decision systems. Many post hoc methods have been proposed to explain the predictions of any machine learning model. However, business processes and decision systems are rarely centered around a single, standalone model. These systems combine multiple models that produce key predictions, and then apply decision rules to generate the final decision. To explain such decision, we present SMACE, Semi-Model-Agnostic Contextual Explainer, a novel interpretability method that combines a geometric approach for decision rules with existing post hoc solutions for machine learning models to generate an intuitive feature ranking tailored to the end user. We show that established model-agnostic approaches produce poor results in this framework.