Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sea of Words: An In-Depth Analysis of Anchors for Text Data
Paper and Code


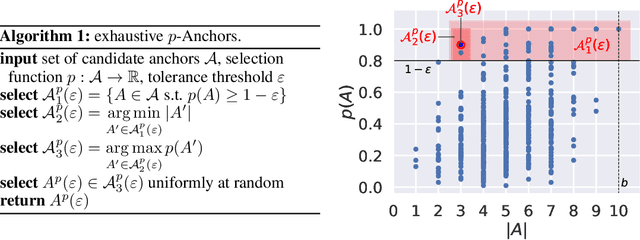
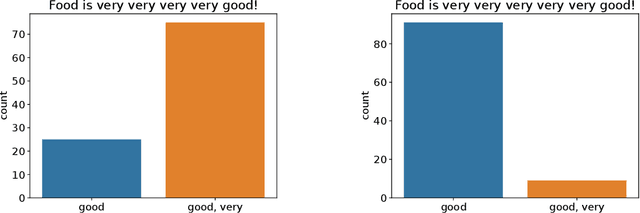
Anchors [Ribeiro et al. (2018)] is a post-hoc, rule-based interpretability method. For text data, it proposes to explain a decision by highlighting a small set of words (an anchor) such that the model to explain has similar outputs when they are present in a document. In this paper, we present the first theoretical analysis of Anchors, considering that the search for the best anchor is exhaustive. We leverage this analysis to gain insights on the behavior of Anchors on simple models, including elementary if-then rules and linear classifiers.
* 10+2 page paper, 15-page appendix
View paper on