Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Feature Importance and Rule Extraction for Interpretability on Text Data
Paper and Code
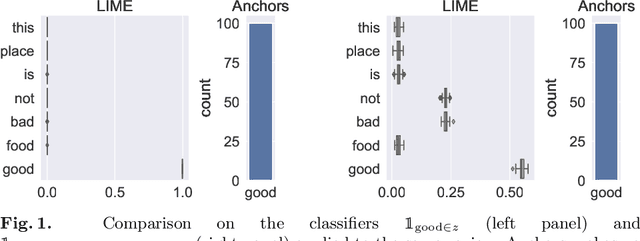
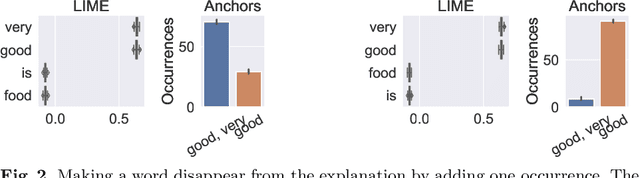
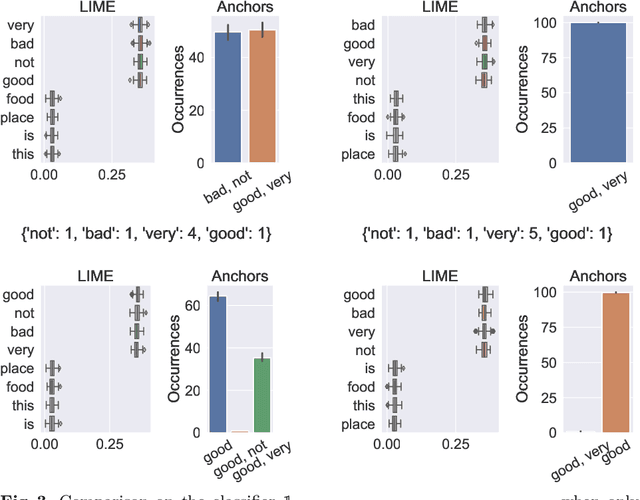
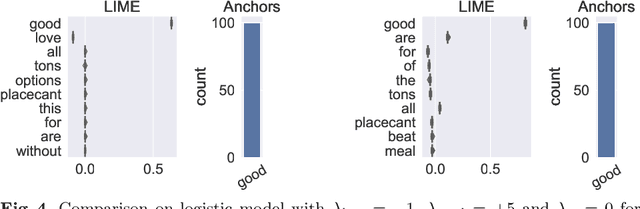
Complex machine learning algorithms are used more and more often in critical tasks involving text data, leading to the development of interpretability methods. Among local methods, two families have emerged: those computing importance scores for each feature and those extracting simple logical rules. In this paper we show that using different methods can lead to unexpectedly different explanations, even when applied to simple models for which we would expect qualitative coincidence. To quantify this effect, we propose a new approach to compare explanations produced by different methods.
* Accepted to XAIE ICPR 2022, the 2-nd Workshop on Explainable and
Ethical AI, ICPR 2022
View paper on