 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mixtures and Products for Ensemble Aggregation: A Likelihood Perspective on Generalized Means
Mar 04, 2026Density aggregation is a central problem in machine learning, for instance when combining predictions from a Deep Ensemble. The choice of aggregation remains an open question with two commonly proposed approaches being linear pooling (probability averaging) and geometric pooling (logit averaging). In this work, we address this question by studying the normalized generalized mean of order $r \in \mathbb{R} \cup \{-\infty,+\infty\}$ through the lens of log-likelihood, the standard evaluation criterion in machine learning. This provides a unifying aggregation formalism and shows different optimal configurations for different situations. We show that the regime $r \in [0,1]$ is the only range ensuring systematic improvements relative to individual distributions, thereby providing a principled justification for the reliability and widespread practical use of linear ($r=1$) and geometric ($r=0$) pooling. In contrast, we show that aggregation rules with $r \notin [0,1]$ may fail to provide consistent gains with explicit counterexamples. Finally, we corroborate our theoretical findings with empirical evaluations using Deep Ensembles on image and text classification benchmarks.
The Well-Tempered Classifier: Some Elementary Properties of Temperature Scaling
Feb 16, 2026Temperature scaling is a simple method that allows to control the uncertainty of probabilistic models. It is mostly used in two contexts: improving the calibration of classifiers and tuning the stochasticity of large language models (LLMs). In both cases, temperature scaling is the most popular method for the job. Despite its popularity, a rigorous theoretical analysis of the properties of temperature scaling has remained elusive. We investigate here some of these properties. For classification, we show that increasing the temperature increases the uncertainty in the model in a very general sense (and in particular increases its entropy). However, for LLMs, we challenge the common claim that increasing temperature increases diversity. Furthermore, we introduce two new characterisations of temperature scaling. The first one is geometric: the tempered model is shown to be the information projection of the original model onto the set of models with a given entropy. The second characterisation clarifies the role of temperature scaling as a submodel of more general linear scalers such as matrix scaling and Dirichlet calibration: we show that temperature scaling is the only linear scaler that does not change the hard predictions of the model.
When Are Two Scores Better Than One? Investigating Ensembles of Diffusion Models
Jan 16, 2026Diffusion models now generate high-quality, diverse samples, with an increasing focus on more powerful models. Although ensembling is a well-known way to improve supervised models, its application to unconditional score-based diffusion models remains largely unexplored. In this work we investigate whether it provides tangible benefits for generative modelling. We find that while ensembling the scores generally improves the score-matching loss and model likelihood, it fails to consistently enhance perceptual quality metrics such as FID on image datasets. We confirm this observation across a breadth of aggregation rules using Deep Ensembles, Monte Carlo Dropout, on CIFAR-10 and FFHQ. We attempt to explain this discrepancy by investigating possible explanations, such as the link between score estimation and image quality. We also look into tabular data through random forests, and find that one aggregation strategy outperforms the others. Finally, we provide theoretical insights into the summing of score models, which shed light not only on ensembling but also on several model composition techniques (e.g. guidance).
Parsimonious Gaussian mixture models with piecewise-constant eigenvalue profiles
Jul 02, 2025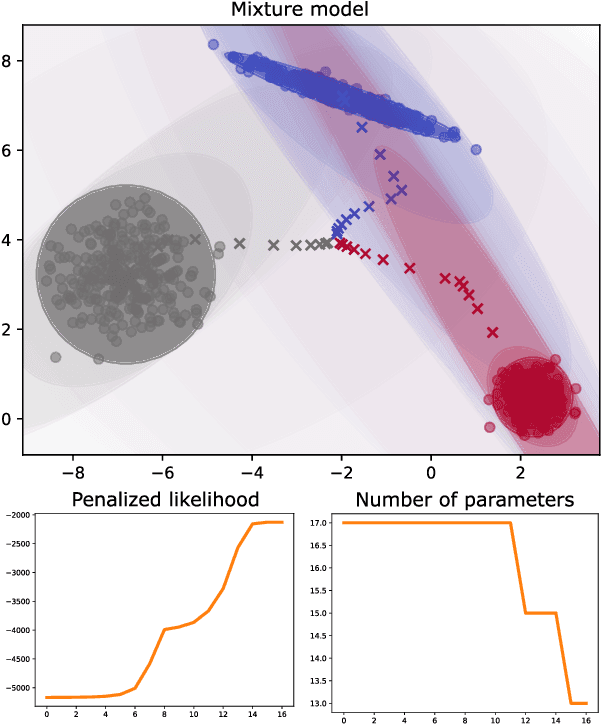



Gaussian mixture models (GMMs) are ubiquitous in statistical learning, particularly for unsupervised problems. While full GMMs suffer from the overparameterization of their covariance matrices in high-dimensional spaces, spherical GMMs (with isotropic covariance matrices) certainly lack flexibility to fit certain anisotropic distributions. Connecting these two extremes, we introduce a new family of parsimonious GMMs with piecewise-constant covariance eigenvalue profiles. These extend several low-rank models like the celebrated mixtures of probabilistic principal component analyzers (MPPCA), by enabling any possible sequence of eigenvalue multiplicities. If the latter are prespecified, then we can naturally derive an expectation-maximization (EM) algorithm to learn the mixture parameters. Otherwise, to address the notoriously-challenging issue of jointly learning the mixture parameters and hyperparameters, we propose a componentwise penalized EM algorithm, whose monotonicity is proven. We show the superior likelihood-parsimony tradeoffs achieved by our models on a variety of unsupervised experiments: density fitting, clustering and single-image denoising.
A Tutorial on Discriminative Clustering and Mutual Information
May 07, 2025To cluster data is to separate samples into distinctive groups that should ideally have some cohesive properties. Today, numerous clustering algorithms exist, and their differences lie essentially in what can be perceived as ``cohesive properties''. Therefore, hypotheses on the nature of clusters must be set: they can be either generative or discriminative. As the last decade witnessed the impressive growth of deep clustering methods that involve neural networks to handle high-dimensional data often in a discriminative manner; we concentrate mainly on the discriminative hypotheses. In this paper, our aim is to provide an accessible historical perspective on the evolution of discriminative clustering methods and notably how the nature of assumptions of the discriminative models changed over time: from decision boundaries to invariance critics. We notably highlight how mutual information has been a historical cornerstone of the progress of (deep) discriminative clustering methods. We also show some known limitations of mutual information and how discriminative clustering methods tried to circumvent those. We then discuss the challenges that discriminative clustering faces with respect to the selection of the number of clusters. Finally, we showcase these techniques using the dedicated Python package, GemClus, that we have developed for discriminative clustering.
Learning Energy-Based Models by Self-normalising the Likelihood
Mar 10, 2025Training an energy-based model (EBM) with maximum likelihood is challenging due to the intractable normalisation constant. Traditional methods rely on expensive Markov chain Monte Carlo (MCMC) sampling to estimate the gradient of logartihm of the normalisation constant. We propose a novel objective called self-normalised log-likelihood (SNL) that introduces a single additional learnable parameter representing the normalisation constant compared to the regular log-likelihood. SNL is a lower bound of the log-likelihood, and its optimum corresponds to both the maximum likelihood estimate of the model parameters and the normalisation constant. We show that the SNL objective is concave in the model parameters for exponential family distributions. Unlike the regular log-likelihood, the SNL can be directly optimised using stochastic gradient techniques by sampling from a crude proposal distribution. We validate the effectiveness of our proposed method on various density estimation tasks as well as EBMs for regression. Our results show that the proposed method, while simpler to implement and tune, outperforms existing techniques.
Kernel KMeans clustering splits for end-to-end unsupervised decision trees
Feb 19, 2024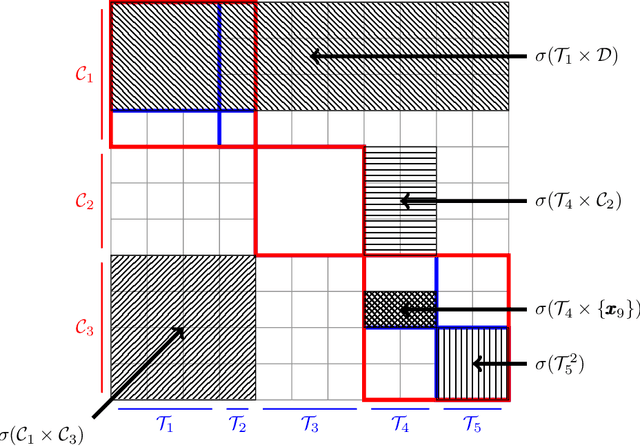
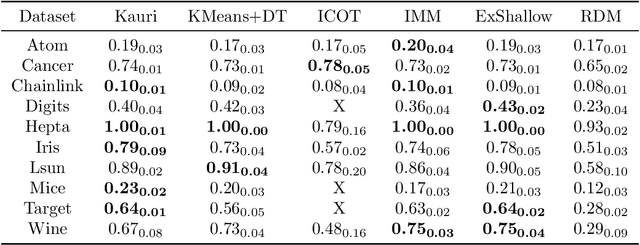
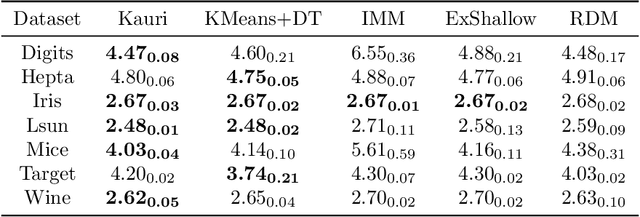
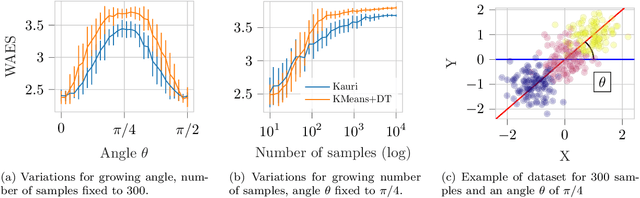
Trees are convenient models for obtaining explainable predictions on relatively small datasets. Although there are many proposals for the end-to-end construction of such trees in supervised learning, learning a tree end-to-end for clustering without labels remains an open challenge. As most works focus on interpreting with trees the result of another clustering algorithm, we present here a novel end-to-end trained unsupervised binary tree for clustering: Kauri. This method performs a greedy maximisation of the kernel KMeans objective without requiring the definition of centroids. We compare this model on multiple datasets with recent unsupervised trees and show that Kauri performs identically when using a linear kernel. For other kernels, Kauri often outperforms the concatenation of kernel KMeans and a CART decision tree.
Are ensembles getting better all the time?
Nov 29, 2023Ensemble methods combine the predictions of several base models. We study whether or not including more models in an ensemble always improve its average performance. Such a question depends on the kind of ensemble considered, as well as the predictive metric chosen. We focus on situations where all members of the ensemble are a priori expected to perform as well, which is the case of several popular methods like random forests or deep ensembles. In this setting, we essentially show that ensembles are getting better all the time if, and only if, the considered loss function is convex. More precisely, in that case, the average loss of the ensemble is a decreasing function of the number of models. When the loss function is nonconvex, we show a series of results that can be summarised by the insight that ensembles of good models keep getting better, and ensembles of bad models keep getting worse. To this end, we prove a new result on the monotonicity of tail probabilities that may be of independent interest. We illustrate our results on a simple machine learning problem (diagnosing melanomas using neural nets).
Generalised Mutual Information: a Framework for Discriminative Clustering
Sep 06, 2023



In the last decade, recent successes in deep clustering majorly involved the Mutual Information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the Generalised Mutual Information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training as they are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep discriminative clustering context where the number of clusters is a priori unknown.
Fed-MIWAE: Federated Imputation of Incomplete Data via Deep Generative Models
Apr 17, 2023

Federated learning allows for the training of machine learning models on multiple decentralized local datasets without requiring explicit data exchange. However, data pre-processing, including strategies for handling missing data, remains a major bottleneck in real-world federated learning deployment, and is typically performed locally. This approach may be biased, since the subpopulations locally observed at each center may not be representative of the overall one. To address this issue, this paper first proposes a more consistent approach to data standardization through a federated model. Additionally, we propose Fed-MIWAE, a federated version of the state-of-the-art imputation method MIWAE, a deep latent variable model for missing data imputation based on variational autoencoders. MIWAE has the great advantage of being easily trainable with classical federated aggregators. Furthermore, it is able to deal with MAR (Missing At Random) data, a more challenging missing-data mechanism than MCAR (Missing Completely At Random), where the missingness of a variable can depend on the observed ones. We evaluate our method on multi-modal medical imaging data and clinical scores from a simulated federated scenario with the ADNI dataset. We compare Fed-MIWAE with respect to classical imputation methods, either performed locally or in a centralized fashion. Fed-MIWAE allows to achieve imputation accuracy comparable with the best centralized method, even when local data distributions are highly heterogeneous. In addition, thanks to the variational nature of Fed-MIWAE, our method is designed to perform multiple imputation, allowing for the quantification of the imputation uncertainty in the federated scenario.