 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre labels informative in semi-supervised learning? -- Estimating and leveraging the missing-data mechanism
Feb 15, 2023Semi-supervised learning is a powerful technique for leveraging unlabeled data to improve machine learning models, but it can be affected by the presence of ``informative'' labels, which occur when some classes are more likely to be labeled than others. In the missing data literature, such labels are called missing not at random. In this paper, we propose a novel approach to address this issue by estimating the missing-data mechanism and using inverse propensity weighting to debias any SSL algorithm, including those using data augmentation. We also propose a likelihood ratio test to assess whether or not labels are indeed informative. Finally, we demonstrate the performance of the proposed methods on different datasets, in particular on two medical datasets for which we design pseudo-realistic missing data scenarios.
Don't fear the unlabelled: safe deep semi-supervised learning via simple debiasing
Mar 16, 2022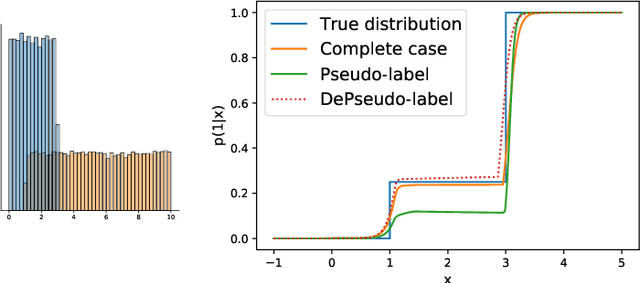
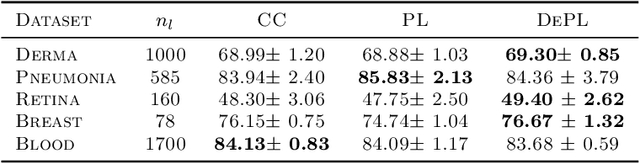
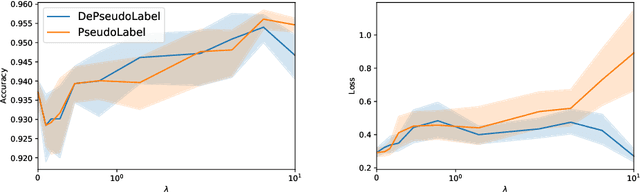
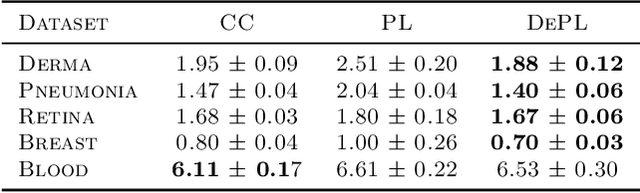
Semi supervised learning (SSL) provides an effective means of leveraging unlabelled data to improve a model's performance. Even though the domain has received a considerable amount of attention in the past years, most methods present the common drawback of being unsafe. By safeness we mean the quality of not degrading a fully supervised model when including unlabelled data. Our starting point is to notice that the estimate of the risk that most discriminative SSL methods minimise is biased, even asymptotically. This bias makes these techniques untrustable without a proper validation set, but we propose a simple way of removing the bias. Our debiasing approach is straightforward to implement, and applicable to most deep SSL methods. We provide simple theoretical guarantees on the safeness of these modified methods, without having to rely on the strong assumptions on the data distribution that SSL theory usually requires. We evaluate debiased versions of different existing SSL methods and show that debiasing can compete with classic deep SSL techniques in various classic settings and even performs well when traditional SSL fails.
Model-agnostic out-of-distribution detection using combined statistical tests
Mar 02, 2022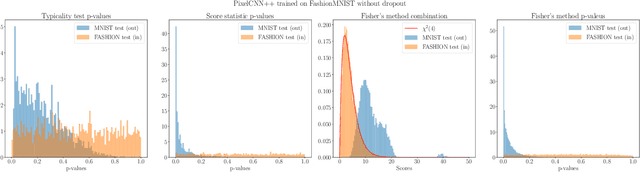
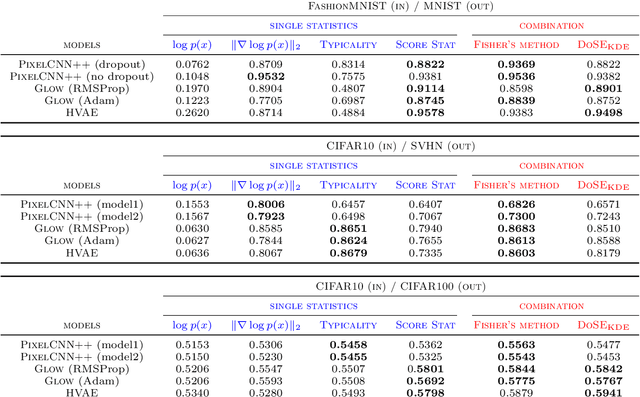
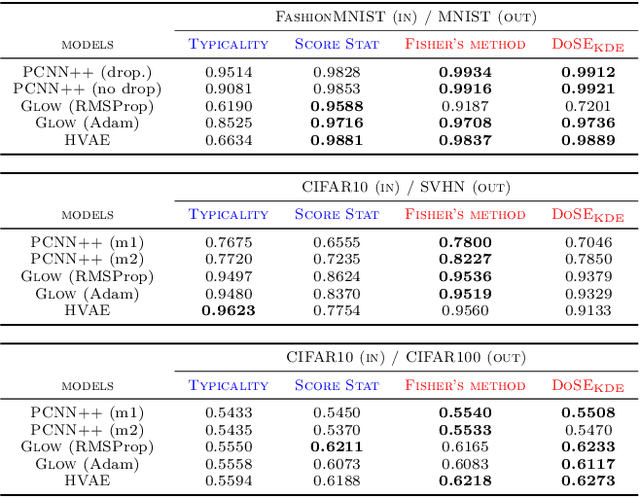
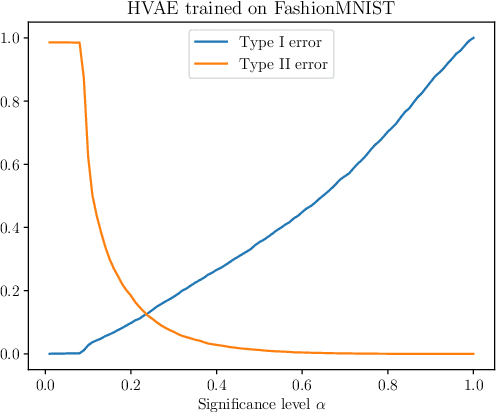
We present simple methods for out-of-distribution detection using a trained generative model. These techniques, based on classical statistical tests, are model-agnostic in the sense that they can be applied to any differentiable generative model. The idea is to combine a classical parametric test (Rao's score test) with the recently introduced typicality test. These two test statistics are both theoretically well-founded and exploit different sources of information based on the likelihood for the typicality test and its gradient for the score test. We show that combining them using Fisher's method overall leads to a more accurate out-of-distribution test. We also discuss the benefits of casting out-of-distribution detection as a statistical testing problem, noting in particular that false positive rate control can be valuable for practical out-of-distribution detection. Despite their simplicity and generality, these methods can be competitive with model-specific out-of-distribution detection algorithms without any assumptions on the out-distribution.