 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cautionary tale on the cost-effectiveness of collaborative AI in real-world medical applications
Dec 09, 2024Background. Federated learning (FL) has gained wide popularity as a collaborative learning paradigm enabling collaborative AI in sensitive healthcare applications. Nevertheless, the practical implementation of FL presents technical and organizational challenges, as it generally requires complex communication infrastructures. In this context, consensus-based learning (CBL) may represent a promising collaborative learning alternative, thanks to the ability of combining local knowledge into a federated decision system, while potentially reducing deployment overhead. Methods. In this work we propose an extensive benchmark of the accuracy and cost-effectiveness of a panel of FL and CBL methods in a wide range of collaborative medical data analysis scenarios. The benchmark includes 7 different medical datasets, encompassing 3 machine learning tasks, 8 different data modalities, and multi-centric settings involving 3 to 23 clients. Findings. Our results reveal that CBL is a cost-effective alternative to FL. When compared across the panel of medical dataset in the considered benchmark, CBL methods provide equivalent accuracy to the one achieved by FL.Nonetheless, CBL significantly reduces training time and communication cost (resp. 15 fold and 60 fold decrease) (p < 0.05). Interpretation. This study opens a novel perspective on the deployment of collaborative AI in real-world applications, whereas the adoption of cost-effective methods is instrumental to achieve sustainability and democratisation of AI by alleviating the need for extensive computational resources.
Benchmarking Collaborative Learning Methods Cost-Effectiveness for Prostate Segmentation
Oct 02, 2023



Healthcare data is often split into medium/small-sized collections across multiple hospitals and access to it is encumbered by privacy regulations. This brings difficulties to use them for the development of machine learning and deep learning models, which are known to be data-hungry. One way to overcome this limitation is to use collaborative learning (CL) methods, which allow hospitals to work collaboratively to solve a task, without the need to explicitly share local data. In this paper, we address a prostate segmentation problem from MRI in a collaborative scenario by comparing two different approaches: federated learning (FL) and consensus-based methods (CBM). To the best of our knowledge, this is the first work in which CBM, such as label fusion techniques, are used to solve a problem of collaborative learning. In this setting, CBM combine predictions from locally trained models to obtain a federated strong learner with ideally improved robustness and predictive variance properties. Our experiments show that, in the considered practical scenario, CBMs provide equal or better results than FL, while being highly cost-effective. Our results demonstrate that the consensus paradigm may represent a valid alternative to FL for typical training tasks in medical imaging.
Fed-BioMed: Open, Transparent and Trusted Federated Learning for Real-world Healthcare Applications
Apr 24, 2023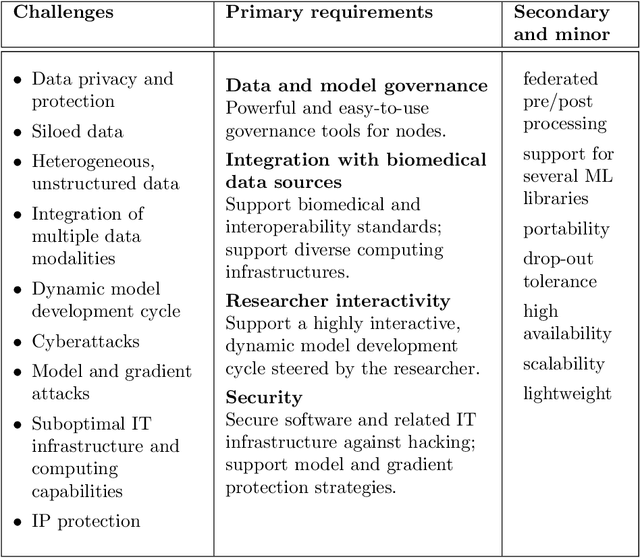
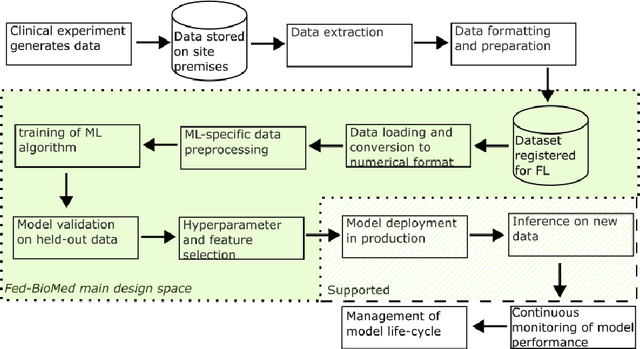
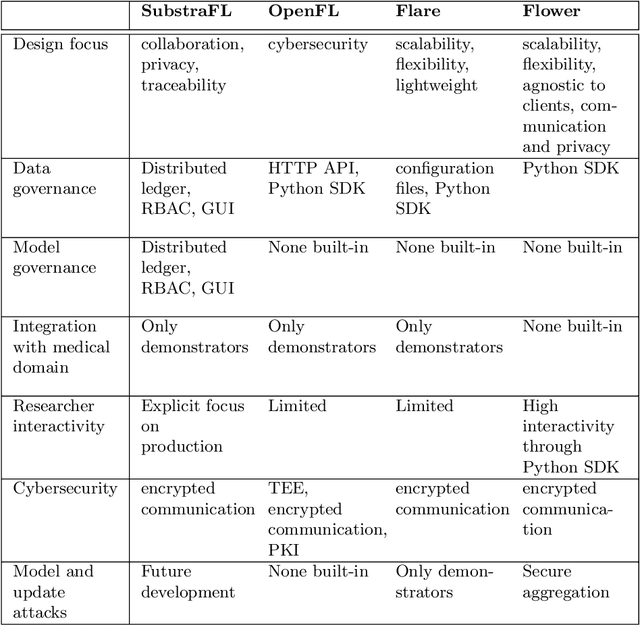
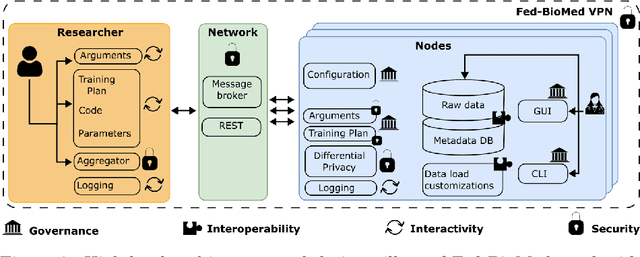
The real-world implementation of federated learning is complex and requires research and development actions at the crossroad between different domains ranging from data science, to software programming, networking, and security. While today several FL libraries are proposed to data scientists and users, most of these frameworks are not designed to find seamless application in medical use-cases, due to the specific challenges and requirements of working with medical data and hospital infrastructures. Moreover, governance, design principles, and security assumptions of these frameworks are generally not clearly illustrated, thus preventing the adoption in sensitive applications. Motivated by the current technological landscape of FL in healthcare, in this document we present Fed-BioMed: a research and development initiative aiming at translating federated learning (FL) into real-world medical research applications. We describe our design space, targeted users, domain constraints, and how these factors affect our current and future software architecture.
Fed-MIWAE: Federated Imputation of Incomplete Data via Deep Generative Models
Apr 17, 2023

Federated learning allows for the training of machine learning models on multiple decentralized local datasets without requiring explicit data exchange. However, data pre-processing, including strategies for handling missing data, remains a major bottleneck in real-world federated learning deployment, and is typically performed locally. This approach may be biased, since the subpopulations locally observed at each center may not be representative of the overall one. To address this issue, this paper first proposes a more consistent approach to data standardization through a federated model. Additionally, we propose Fed-MIWAE, a federated version of the state-of-the-art imputation method MIWAE, a deep latent variable model for missing data imputation based on variational autoencoders. MIWAE has the great advantage of being easily trainable with classical federated aggregators. Furthermore, it is able to deal with MAR (Missing At Random) data, a more challenging missing-data mechanism than MCAR (Missing Completely At Random), where the missingness of a variable can depend on the observed ones. We evaluate our method on multi-modal medical imaging data and clinical scores from a simulated federated scenario with the ADNI dataset. We compare Fed-MIWAE with respect to classical imputation methods, either performed locally or in a centralized fashion. Fed-MIWAE allows to achieve imputation accuracy comparable with the best centralized method, even when local data distributions are highly heterogeneous. In addition, thanks to the variational nature of Fed-MIWAE, our method is designed to perform multiple imputation, allowing for the quantification of the imputation uncertainty in the federated scenario.