 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Balance Bias in Regularized Regression
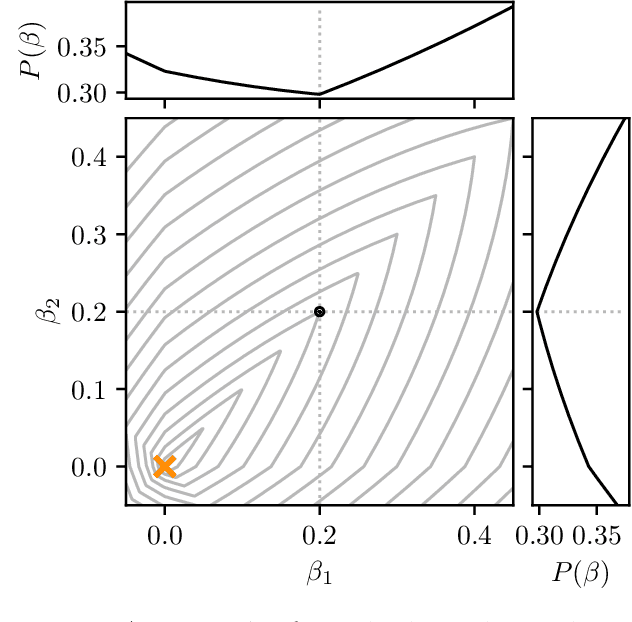
Jan 07, 2025Regularized models are often sensitive to the scales of the features in the data and it has therefore become standard practice to normalize (center and scale) the features before fitting the model. But there are many different ways to normalize the features and the choice may have dramatic effects on the resulting model. In spite of this, there has so far been no research on this topic. In this paper, we begin to bridge this knowledge gap by studying normalization in the context of lasso, ridge, and elastic net regression. We focus on normal and binary features and show that the class balances of binary features directly influences the regression coefficients and that this effect depends on the combination of normalization and regularization methods used. We demonstrate that this effect can be mitigated by scaling binary features with their variance in the case of the lasso and standard deviation in the case of ridge regression, but that this comes at the cost of increased variance. For the elastic net, we show that scaling the penalty weights, rather than the features, can achieve the same effect. Finally, we also tackle mixes of binary and normal features as well as interactions and provide some initial results on how to normalize features in these cases.
Coordinate Descent for SLOPE
Oct 26, 2022
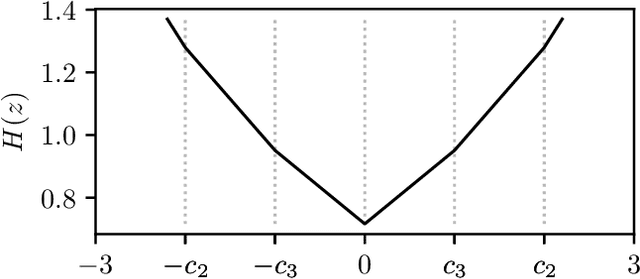

The lasso is the most famous sparse regression and feature selection method. One reason for its popularity is the speed at which the underlying optimization problem can be solved. Sorted L-One Penalized Estimation (SLOPE) is a generalization of the lasso with appealing statistical properties. In spite of this, the method has not yet reached widespread interest. A major reason for this is that current software packages that fit SLOPE rely on algorithms that perform poorly in high dimensions. To tackle this issue, we propose a new fast algorithm to solve the SLOPE optimization problem, which combines proximal gradient descent and proximal coordinate descent steps. We provide new results on the directional derivative of the SLOPE penalty and its related SLOPE thresholding operator, as well as provide convergence guarantees for our proposed solver. In extensive benchmarks on simulated and real data, we show that our method outperforms a long list of competing algorithms.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022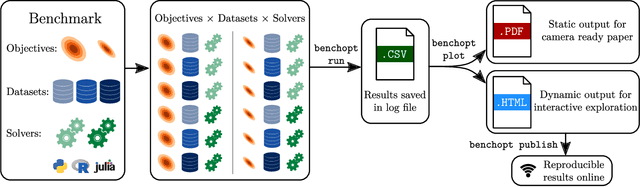
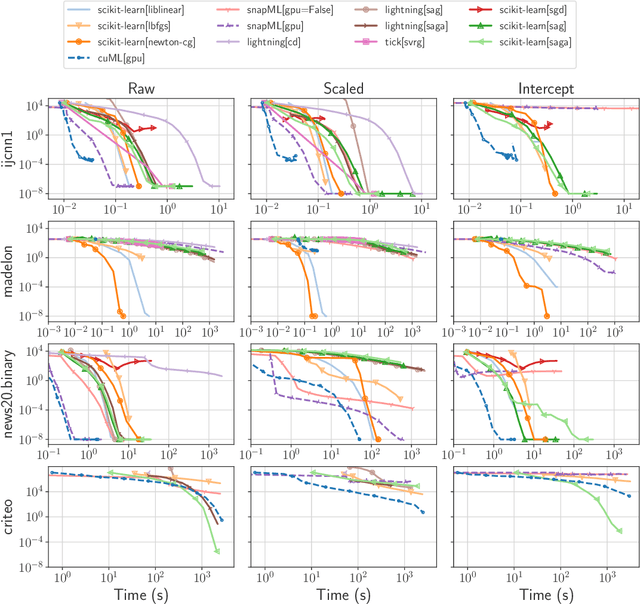
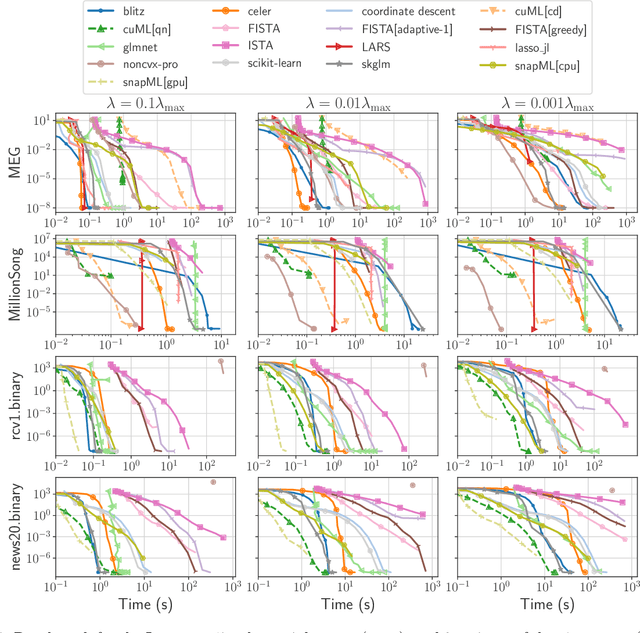
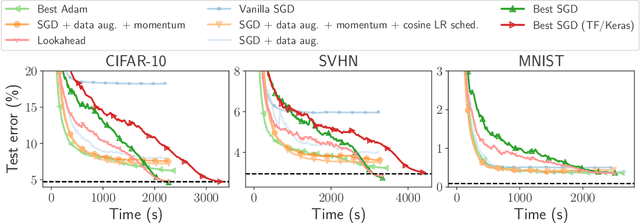
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
Look-Ahead Screening Rules for the Lasso
May 12, 2021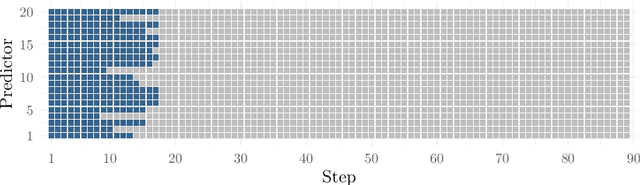
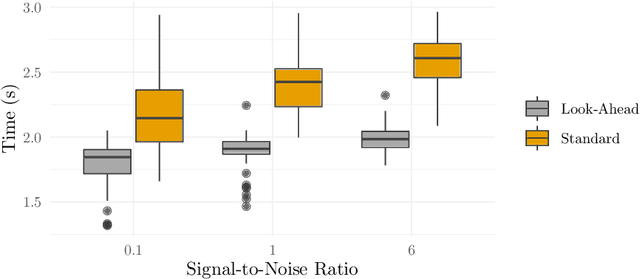
The lasso is a popular method to induce shrinkage and sparsity in the solution vector (coefficients) of regression problems, particularly when there are many predictors relative to the number of observations. Solving the lasso in this high-dimensional setting can, however, be computationally demanding. Fortunately, this demand can be alleviated via the use of screening rules that discard predictors prior to fitting the model, leading to a reduced problem to be solved. In this paper, we present a new screening strategy: look-ahead screening. Our method uses safe screening rules to find a range of penalty values for which a given predictor cannot enter the model, thereby screening predictors along the remainder of the path. In experiments we show that these look-ahead screening rules improve the performance of existing screening strategies.
The Hessian Screening Rule
Apr 27, 2021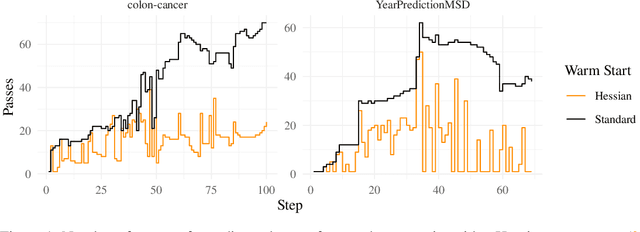
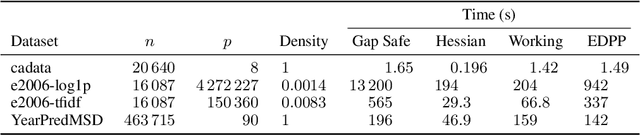
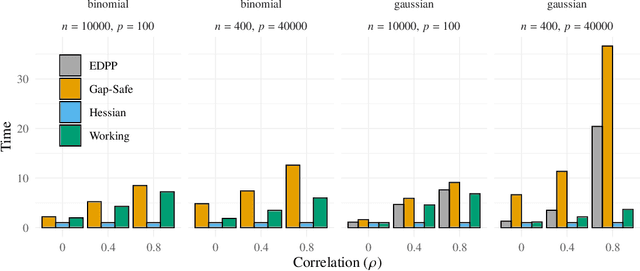
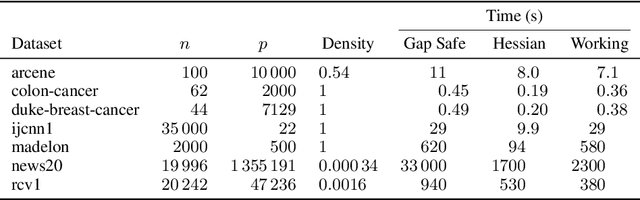
Predictor screening rules, which discard predictors from the design matrix before fitting a model, have had sizable impacts on the speed with which $\ell_1$-regularized regression problems, such as the lasso, can be solved. Current state-of-the-art screening rules, however, have difficulties in dealing with highly-correlated predictors, often becoming too conservative. In this paper, we present a new screening rule to deal with this issue: the Hessian Screening Rule. The rule uses second-order information from the model in order to provide more accurate screening as well as higher-quality warm starts. In our experiments on $\ell_1$-regularized least-squares (the lasso) and logistic regression, we show that the rule outperforms all other alternatives in simulated experiments with high correlation, as well as in the majority of real datasets that we study.
The Strong Screening Rule for SLOPE
May 07, 2020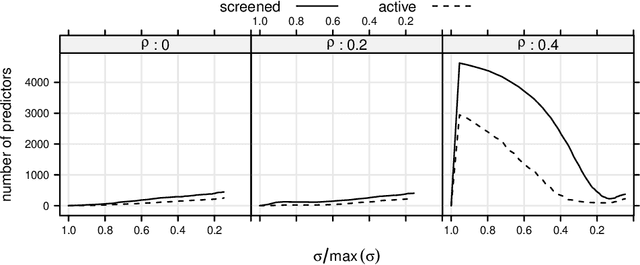
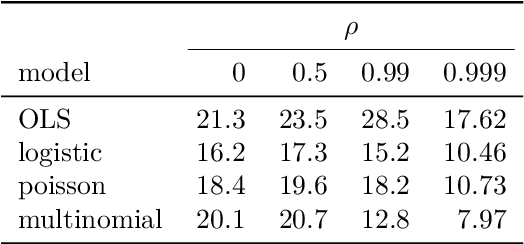

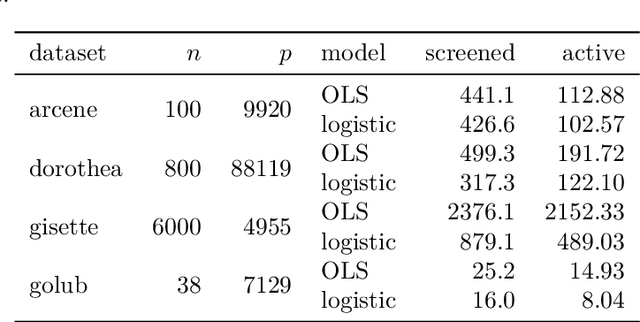
Extracting relevant features from data sets where the number of observations ($n$) is much smaller then the number of predictors ($p$) is a major challenge in modern statistics. Sorted L-One Penalized Estimation (SLOPE), a generalization of the lasso, is a promising method within this setting. Current numerical procedures for SLOPE, however, lack the efficiency that respective tools for the lasso enjoy, particularly in the context of estimating a complete regularization path. A key component in the efficiency of the lasso is predictor screening rules: rules that allow predictors to be discarded before estimating the model. This is the first paper to establish such a rule for SLOPE. We develop a screening rule for SLOPE by examining its subdifferential and show that this rule is a generalization of the strong rule for the lasso. Our rule is heuristic, which means that it may discard predictors erroneously. We present conditions under which this may happen and show that such situations are rare and easily safeguarded against by a simple check of the optimality conditions. Our numerical experiments show that the rule performs well in practice, leading to improvements by orders of magnitude for data in the $p \gg n$ domain, as well as incurring no additional computational overhead when $n \gg p$. We also examine the effect of correlation structures in the design matrix on the rule and discuss algorithmic strategies for employing the rule. Finally, we provide an efficient implementation of the rule in our R package SLOPE.