 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath-conditioned training: a principled way to rescale ReLU neural networks
Feb 23, 2026Despite recent algorithmic advances, we still lack principled ways to leverage the well-documented rescaling symmetries in ReLU neural network parameters. While two properly rescaled weights implement the same function, the training dynamics can be dramatically different. To offer a fresh perspective on exploiting this phenomenon, we build on the recent path-lifting framework, which provides a compact factorization of ReLU networks. We introduce a geometrically motivated criterion to rescale neural network parameters which minimization leads to a conditioning strategy that aligns a kernel in the path-lifting space with a chosen reference. We derive an efficient algorithm to perform this alignment. In the context of random network initialization, we analyze how the architecture and the initialization scale jointly impact the output of the proposed method. Numerical experiments illustrate its potential to speed up training.
Intrinsic training dynamics of deep neural networks
Aug 10, 2025A fundamental challenge in the theory of deep learning is to understand whether gradient-based training in high-dimensional parameter spaces can be captured by simpler, lower-dimensional structures, leading to so-called implicit bias. As a stepping stone, we study when a gradient flow on a high-dimensional variable $\theta$ implies an intrinsic gradient flow on a lower-dimensional variable $z = \phi(\theta)$, for an architecture-related function $\phi$. We express a so-called intrinsic dynamic property and show how it is related to the study of conservation laws associated with the factorization $\phi$. This leads to a simple criterion based on the inclusion of kernels of linear maps which yields a necessary condition for this property to hold. We then apply our theory to general ReLU networks of arbitrary depth and show that, for any initialization, it is possible to rewrite the flow as an intrinsic dynamic in a lower dimension that depends only on $z$ and the initialization, when $\phi$ is the so-called path-lifting. In the case of linear networks with $\phi$ the product of weight matrices, so-called balanced initializations are also known to enable such a dimensionality reduction; we generalize this result to a broader class of {\em relaxed balanced} initializations, showing that, in certain configurations, these are the \emph{only} initializations that ensure the intrinsic dynamic property. Finally, for the linear neural ODE associated with the limit of infinitely deep linear networks, with relaxed balanced initialization, we explicitly express the corresponding intrinsic dynamics.
Transformative or Conservative? Conservation laws for ResNets and Transformers
Jun 06, 2025While conservation laws in gradient flow training dynamics are well understood for (mostly shallow) ReLU and linear networks, their study remains largely unexplored for more practical architectures. This paper bridges this gap by deriving and analyzing conservation laws for modern architectures, with a focus on convolutional ResNets and Transformer networks. For this, we first show that basic building blocks such as ReLU (or linear) shallow networks, with or without convolution, have easily expressed conservation laws, and no more than the known ones. In the case of a single attention layer, we also completely describe all conservation laws, and we show that residual blocks have the same conservation laws as the same block without a skip connection. We then introduce the notion of conservation laws that depend only on a subset of parameters (corresponding e.g. to a pair of consecutive layers, to a residual block, or to an attention layer). We demonstrate that the characterization of such laws can be reduced to the analysis of the corresponding building block in isolation. Finally, we examine how these newly discovered conservation principles, initially established in the continuous gradient flow regime, persist under discrete optimization dynamics, particularly in the context of Stochastic Gradient Descent (SGD).
Convexity in ReLU Neural Networks: beyond ICNNs?
Jan 06, 2025Convex functions and their gradients play a critical role in mathematical imaging, from proximal optimization to Optimal Transport. The successes of deep learning has led many to use learning-based methods, where fixed functions or operators are replaced by learned neural networks. Regardless of their empirical superiority, establishing rigorous guarantees for these methods often requires to impose structural constraints on neural architectures, in particular convexity. The most popular way to do so is to use so-called Input Convex Neural Networks (ICNNs). In order to explore the expressivity of ICNNs, we provide necessary and sufficient conditions for a ReLU neural network to be convex. Such characterizations are based on product of weights and activations, and write nicely for any architecture in the path-lifting framework. As particular applications, we study our characterizations in depth for 1 and 2-hidden-layer neural networks: we show that every convex function implemented by a 1-hidden-layer ReLU network can be also expressed by an ICNN with the same architecture; however this property no longer holds with more layers. Finally, we provide a numerical procedure that allows an exact check of convexity for ReLU neural networks with a large number of affine regions.
PASCO (PArallel Structured COarsening): an overlay to speed up graph clustering algorithms
Dec 18, 2024Clustering the nodes of a graph is a cornerstone of graph analysis and has been extensively studied. However, some popular methods are not suitable for very large graphs: e.g., spectral clustering requires the computation of the spectral decomposition of the Laplacian matrix, which is not applicable for large graphs with a large number of communities. This work introduces PASCO, an overlay that accelerates clustering algorithms. Our method consists of three steps: 1-We compute several independent small graphs representing the input graph by applying an efficient and structure-preserving coarsening algorithm. 2-A clustering algorithm is run in parallel onto each small graph and provides several partitions of the initial graph. 3-These partitions are aligned and combined with an optimal transport method to output the final partition. The PASCO framework is based on two key contributions: a novel global algorithm structure designed to enable parallelization and a fast, empirically validated graph coarsening algorithm that preserves structural properties. We demonstrate the strong performance of 1 PASCO in terms of computational efficiency, structural preservation, and output partition quality, evaluated on both synthetic and real-world graph datasets.
Path-metrics, pruning, and generalization
May 23, 2024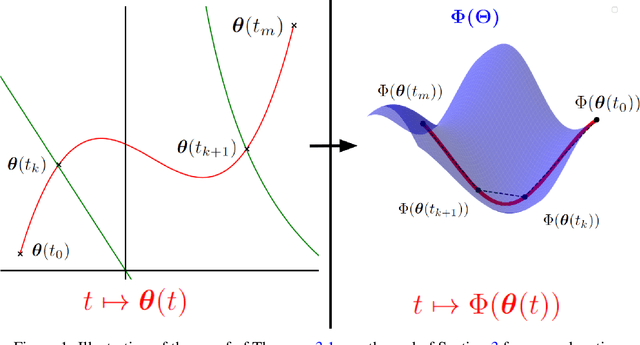

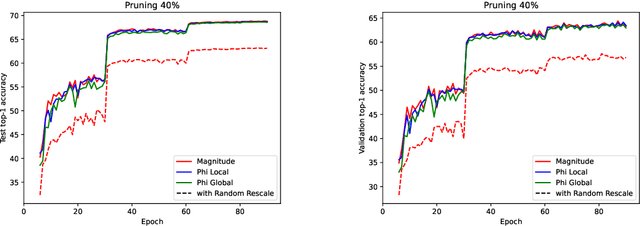

Analyzing the behavior of ReLU neural networks often hinges on understanding the relationships between their parameters and the functions they implement. This paper proves a new bound on function distances in terms of the so-called path-metrics of the parameters. Since this bound is intrinsically invariant with respect to the rescaling symmetries of the networks, it sharpens previously known bounds. It is also, to the best of our knowledge, the first bound of its kind that is broadly applicable to modern networks such as ResNets, VGGs, U-nets, and many more. In contexts such as network pruning and quantization, the proposed path-metrics can be efficiently computed using only two forward passes. Besides its intrinsic theoretical interest, the bound yields not only novel theoretical generalization bounds, but also a promising proof of concept for rescaling-invariant pruning.
Keep the Momentum: Conservation Laws beyond Euclidean Gradient Flows
May 21, 2024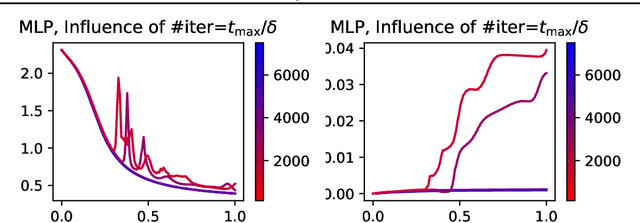
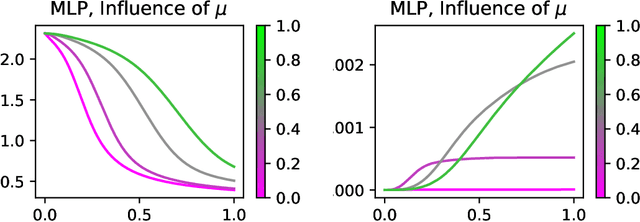

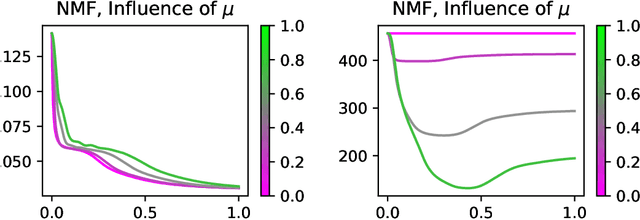
Conservation laws are well-established in the context of Euclidean gradient flow dynamics, notably for linear or ReLU neural network training. Yet, their existence and principles for non-Euclidean geometries and momentum-based dynamics remain largely unknown. In this paper, we characterize "all" conservation laws in this general setting. In stark contrast to the case of gradient flows, we prove that the conservation laws for momentum-based dynamics exhibit temporal dependence. Additionally, we often observe a "conservation loss" when transitioning from gradient flow to momentum dynamics. Specifically, for linear networks, our framework allows us to identify all momentum conservation laws, which are less numerous than in the gradient flow case except in sufficiently over-parameterized regimes. With ReLU networks, no conservation law remains. This phenomenon also manifests in non-Euclidean metrics, used e.g. for Nonnegative Matrix Factorization (NMF): all conservation laws can be determined in the gradient flow context, yet none persists in the momentum case.
Sketch and shift: a robust decoder for compressive clustering
Dec 15, 2023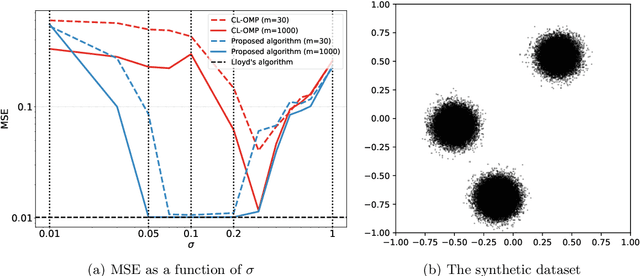
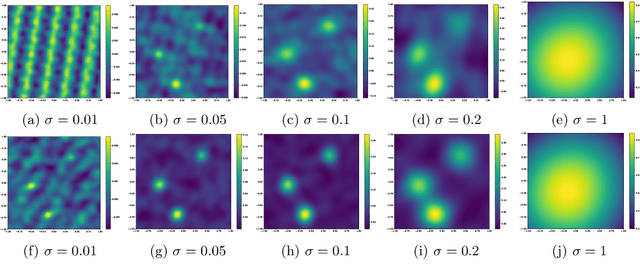
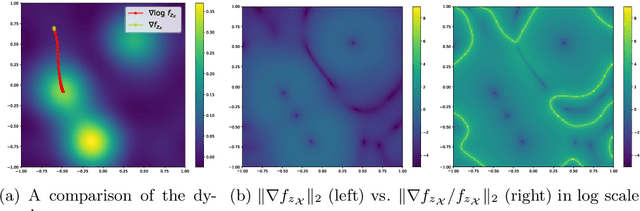
Compressive learning is an emerging approach to drastically reduce the memory footprint of large-scale learning, by first summarizing a large dataset into a low-dimensional sketch vector, and then decoding from this sketch the latent information needed for learning. In light of recent progress on information preservation guarantees for sketches based on random features, a major objective is to design easy-to-tune algorithms (called decoders) to robustly and efficiently extract this information. To address the underlying non-convex optimization problems, various heuristics have been proposed. In the case of compressive clustering, the standard heuristic is CL-OMPR, a variant of sliding Frank-Wolfe. Yet, CL-OMPR is hard to tune, and the examination of its robustness was overlooked. In this work, we undertake a scrutinized examination of CL-OMPR to circumvent its limitations. In particular, we show how this algorithm can fail to recover the clusters even in advantageous scenarios. To gain insight, we show how the deficiencies of this algorithm can be attributed to optimization difficulties related to the structure of a correlation function appearing at core steps of the algorithm. To address these limitations, we propose an alternative decoder offering substantial improvements over CL-OMPR. Its design is notably inspired from the mean shift algorithm, a classic approach to detect the local maxima of kernel density estimators. The proposed algorithm can extract clustering information from a sketch of the MNIST dataset that is 10 times smaller than previously.
Revisiting RIP guarantees for sketching operators on mixture models
Dec 09, 2023


In the context of sketching for compressive mixture modeling, we revisit existing proofs of the Restricted Isometry Property of sketching operators with respect to certain mixtures models. After examining the shortcomings of existing guarantees, we propose an alternative analysis that circumvents the need to assume importance sampling when drawing random Fourier features to build random sketching operators. Our analysis is based on new deterministic bounds on the restricted isometry constant that depend solely on the set of frequencies used to define the sketching operator; then we leverage these bounds to establish concentration inequalities for random sketching operators that lead to the desired RIP guarantees. Our analysis also opens the door to theoretical guarantees for structured sketching with frequencies associated to fast random linear operators.
Compressive Recovery of Sparse Precision Matrices
Nov 08, 2023We consider the problem of learning a graph modeling the statistical relations of the $d$ variables of a dataset with $n$ samples $X \in \mathbb{R}^{n \times d}$. Standard approaches amount to searching for a precision matrix $\Theta$ representative of a Gaussian graphical model that adequately explains the data. However, most maximum likelihood-based estimators usually require storing the $d^{2}$ values of the empirical covariance matrix, which can become prohibitive in a high-dimensional setting. In this work, we adopt a compressive viewpoint and aim to estimate a sparse $\Theta$ from a sketch of the data, i.e. a low-dimensional vector of size $m \ll d^{2}$ carefully designed from $X$ using nonlinear random features. Under certain assumptions on the spectrum of $\Theta$ (or its condition number), we show that it is possible to estimate it from a sketch of size $m=\Omega((d+2k)\log(d))$ where $k$ is the maximal number of edges of the underlying graph. These information-theoretic guarantees are inspired by compressed sensing theory and involve restricted isometry properties and instance optimal decoders. We investigate the possibility of achieving practical recovery with an iterative algorithm based on the graphical lasso, viewed as a specific denoiser. We compare our approach and graphical lasso on synthetic datasets, demonstrating its favorable performance even when the dataset is compressed.