 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Gossip Algorithms for Machine Learning with Pairwise Objectives
Mar 25, 2026In the IoT era, information is more and more frequently picked up by connected smart sensors with increasing, though limited, storage, communication and computation abilities. Whether due to privacy constraints or to the structure of the distributed system, the development of statistical learning methods dedicated to data that are shared over a network is now a major issue. Gossip-based algorithms have been developed for the purpose of solving a wide variety of statistical learning tasks, ranging from data aggregation over sensor networks to decentralized multi-agent optimization. Whereas the vast majority of contributions consider situations where the function to be estimated or optimized is a basic average of individual observations, it is the goal of this article to investigate the case where the latter is of pairwise nature, taking the form of a U -statistic of degree two. Motivated by various problems such as similarity learning, ranking or clustering for instance, we revisit gossip algorithms specifically designed for pairwise objective functions and provide a comprehensive theoretical framework for their convergence. This analysis fills a gap in the literature by establishing conditions under which these methods succeed, and by identifying the graph properties that critically affect their efficiency. In particular, a refined analysis of the convergence upper and lower bounds is performed.
Conformal Prediction for Long-Tailed Classification
Jul 09, 2025



Many real-world classification problems, such as plant identification, have extremely long-tailed class distributions. In order for prediction sets to be useful in such settings, they should (i) provide good class-conditional coverage, ensuring that rare classes are not systematically omitted from the prediction sets, and (ii) be a reasonable size, allowing users to easily verify candidate labels. Unfortunately, existing conformal prediction methods, when applied to the long-tailed setting, force practitioners to make a binary choice between small sets with poor class-conditional coverage or sets with very good class-conditional coverage but that are extremely large. We propose methods with guaranteed marginal coverage that smoothly trade off between set size and class-conditional coverage. First, we propose a conformal score function, prevalence-adjusted softmax, that targets a relaxed notion of class-conditional coverage called macro-coverage. Second, we propose a label-weighted conformal prediction method that allows us to interpolate between marginal and class-conditional conformal prediction. We demonstrate our methods on Pl@ntNet and iNaturalist, two long-tailed image datasets with 1,081 and 8,142 classes, respectively.
Cooperative learning of Pl@ntNet's Artificial Intelligence algorithm: how does it work and how can we improve it?
Jun 05, 2024Deep learning models for plant species identification rely on large annotated datasets. The PlantNet system enables global data collection by allowing users to upload and annotate plant observations, leading to noisy labels due to diverse user skills. Achieving consensus is crucial for training, but the vast scale of collected data makes traditional label aggregation strategies challenging. Existing methods either retain all observations, resulting in noisy training data or selectively keep those with sufficient votes, discarding valuable information. Additionally, as many species are rarely observed, user expertise can not be evaluated as an inter-user agreement: otherwise, botanical experts would have a lower weight in the AI training step than the average user. Our proposed label aggregation strategy aims to cooperatively train plant identification AI models. This strategy estimates user expertise as a trust score per user based on their ability to identify plant species from crowdsourced data. The trust score is recursively estimated from correctly identified species given the current estimated labels. This interpretable score exploits botanical experts' knowledge and the heterogeneity of users. Subsequently, our strategy removes unreliable observations but retains those with limited trusted annotations, unlike other approaches. We evaluate PlantNet's strategy on a released large subset of the PlantNet database focused on European flora, comprising over 6M observations and 800K users. We demonstrate that estimating users' skills based on the diversity of their expertise enhances labeling performance. Our findings emphasize the synergy of human annotation and data filtering in improving AI performance for a refined dataset. We explore incorporating AI-based votes alongside human input. This can further enhance human-AI interactions to detect unreliable observations.
A two-head loss function for deep Average-K classification
Mar 31, 2023


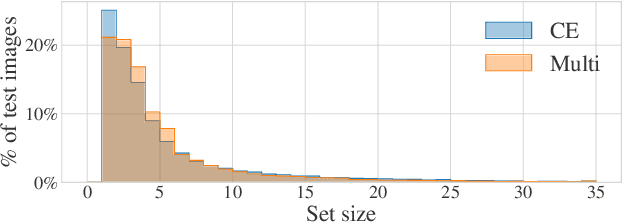
Average-K classification is an alternative to top-K classification in which the number of labels returned varies with the ambiguity of the input image but must average to K over all the samples. A simple method to solve this task is to threshold the softmax output of a model trained with the cross-entropy loss. This approach is theoretically proven to be asymptotically consistent, but it is not guaranteed to be optimal for a finite set of samples. In this paper, we propose a new loss function based on a multi-label classification head in addition to the classical softmax. This second head is trained using pseudo-labels generated by thresholding the softmax head while guaranteeing that K classes are returned on average. We show that this approach allows the model to better capture ambiguities between classes and, as a result, to return more consistent sets of possible classes. Experiments on two datasets from the literature demonstrate that our approach outperforms the softmax baseline, as well as several other loss functions more generally designed for weakly supervised multi-label classification. The gains are larger the higher the uncertainty, especially for classes with few samples.
Improve learning combining crowdsourced labels by weighting Areas Under the Margin
Sep 30, 2022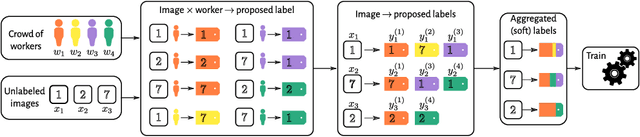


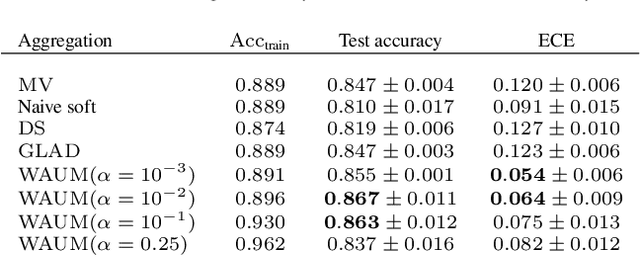
In supervised learning -- for instance in image classification -- modern massive datasets are commonly labeled by a crowd of workers. The obtained labels in this crowdsourcing setting are then aggregated for training. The aggregation step generally leverages a per worker trust score. Yet, such worker-centric approaches discard each task ambiguity. Some intrinsically ambiguous tasks might even fool expert workers, which could eventually be harmful for the learning step. In a standard supervised learning setting -- with one label per task and balanced classes -- the Area Under the Margin (AUM) statistic is tailored to identify mislabeled data. We adapt the AUM to identify ambiguous tasks in crowdsourced learning scenarios, introducing the Weighted AUM (WAUM). The WAUM is an average of AUMs weighted by worker and task dependent scores. We show that the WAUM can help discarding ambiguous tasks from the training set, leading to better generalization or calibration performance. We report improvements with respect to feature-blind aggregation strategies both for simulated settings and for the CIFAR-10H crowdsourced dataset.
High-Dimensional Private Empirical Risk Minimization by Greedy Coordinate Descent
Jul 04, 2022
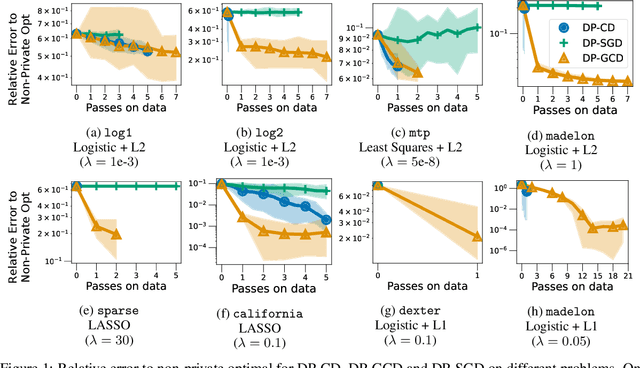
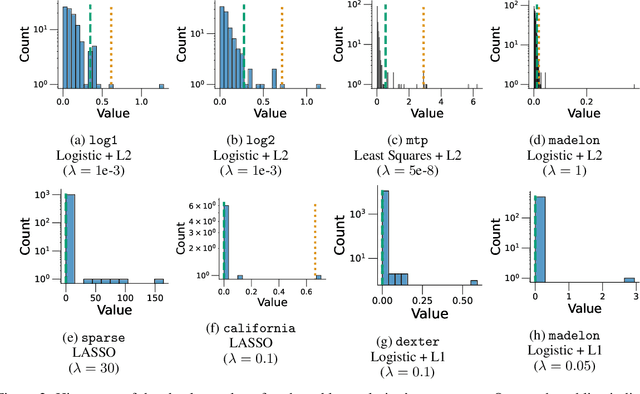
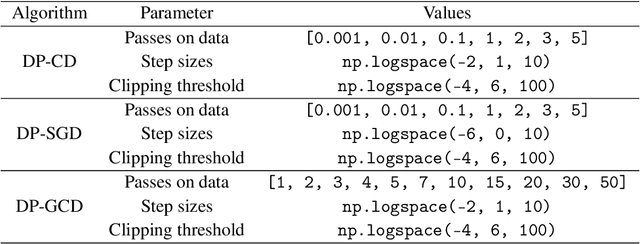
In this paper, we study differentially private empirical risk minimization (DP-ERM). It has been shown that the (worst-case) utility of DP-ERM reduces as the dimension increases. This is a major obstacle to privately learning large machine learning models. In high dimension, it is common for some model's parameters to carry more information than others. To exploit this, we propose a differentially private greedy coordinate descent (DP-GCD) algorithm. At each iteration, DP-GCD privately performs a coordinate-wise gradient step along the gradients' (approximately) greatest entry. We show theoretically that DP-GCD can improve utility by exploiting structural properties of the problem's solution (such as sparsity or quasi-sparsity), with very fast progress in early iterations. We then illustrate this numerically, both on synthetic and real datasets. Finally, we describe promising directions for future work.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022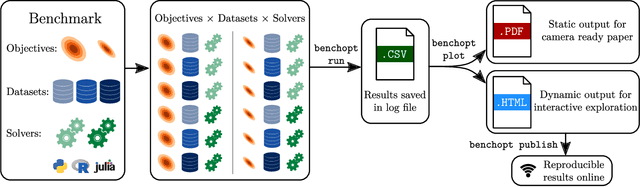
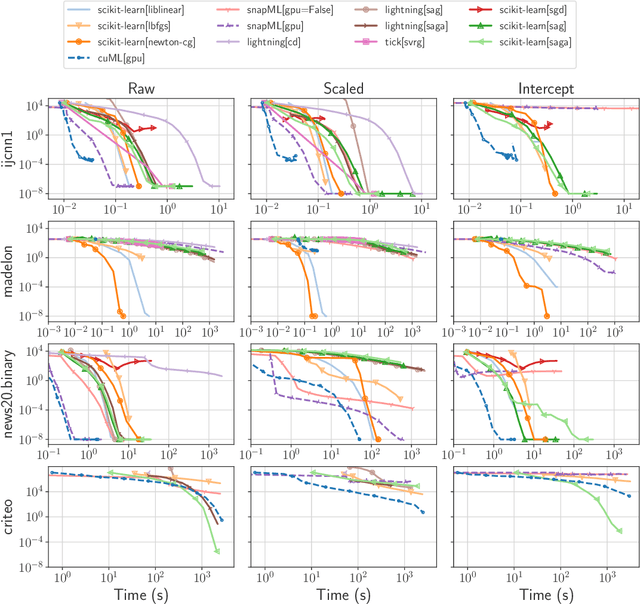
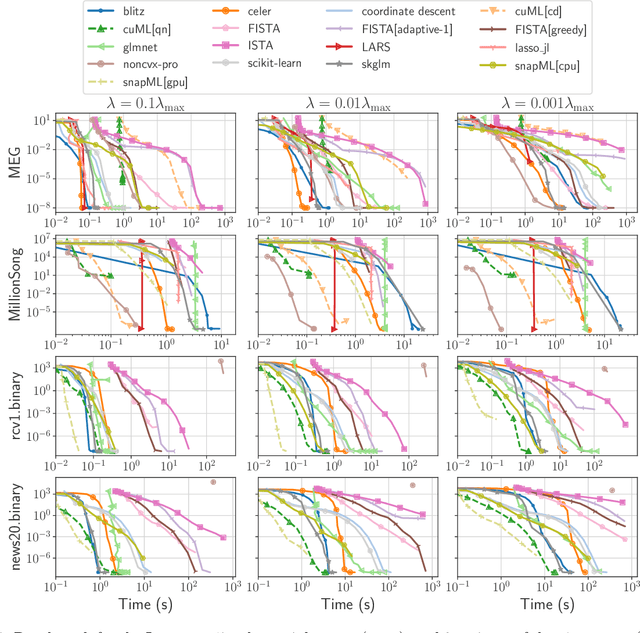
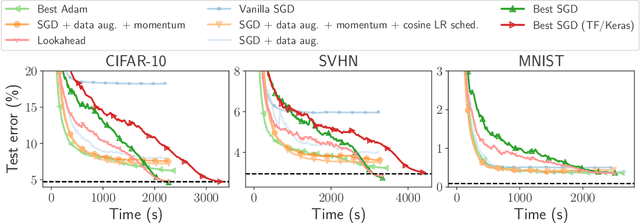
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
Stochastic smoothing of the top-K calibrated hinge loss for deep imbalanced classification
Feb 04, 2022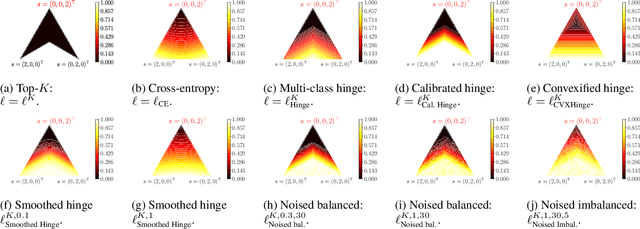

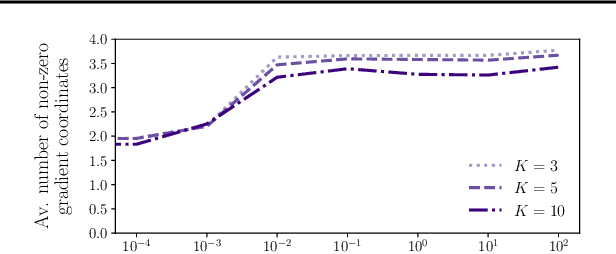

In modern classification tasks, the number of labels is getting larger and larger, as is the size of the datasets encountered in practice. As the number of classes increases, class ambiguity and class imbalance become more and more problematic to achieve high top-1 accuracy. Meanwhile, Top-K metrics (metrics allowing K guesses) have become popular, especially for performance reporting. Yet, proposing top-K losses tailored for deep learning remains a challenge, both theoretically and practically. In this paper we introduce a stochastic top-K hinge loss inspired by recent developments on top-K calibrated losses. Our proposal is based on the smoothing of the top-K operator building on the flexible "perturbed optimizer" framework. We show that our loss function performs very well in the case of balanced datasets, while benefiting from a significantly lower computational time than the state-of-the-art top-K loss function. In addition, we propose a simple variant of our loss for the imbalanced case. Experiments on a heavy-tailed dataset show that our loss function significantly outperforms other baseline loss functions.
Supervised learning of analysis-sparsity priors with automatic differentiation
Dec 15, 2021
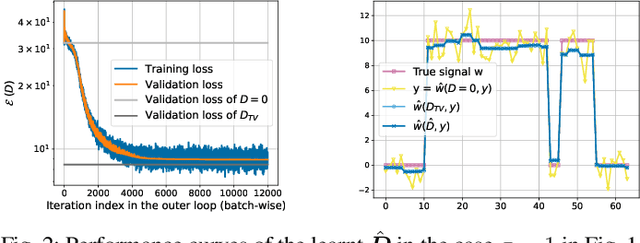
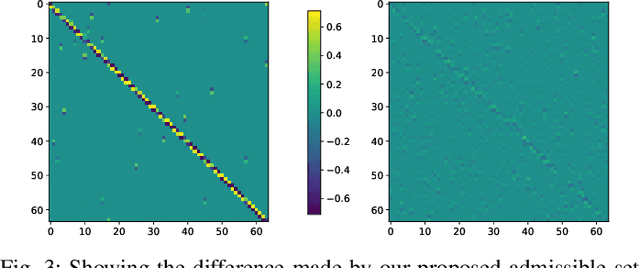
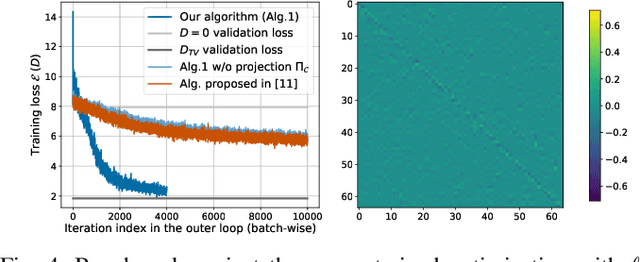
Sparsity priors are commonly used in denoising and image reconstruction. For analysis-type priors, a dictionary defines a representation of signals that is likely to be sparse. In most situations, this dictionary is not known, and is to be recovered from pairs of ground-truth signals and measurements, by minimizing the reconstruction error. This defines a hierarchical optimization problem, which can be cast as a bi-level optimization. Yet, this problem is unsolvable, as reconstructions and their derivative wrt the dictionary have no closed-form expression. However, reconstructions can be iteratively computed using the Forward-Backward splitting (FB) algorithm. In this paper, we approximate reconstructions by the output of the aforementioned FB algorithm. Then, we leverage automatic differentiation to evaluate the gradient of this output wrt the dictionary, which we learn with projected gradient descent. Experiments show that our algorithm successfully learns the 1D Total Variation (TV) dictionary from piecewise constant signals. For the same case study, we propose to constrain our search to dictionaries of 0-centered columns, which removes undesired local minima and improves numerical stability.
LassoBench: A High-Dimensional Hyperparameter Optimization Benchmark Suite for Lasso
Nov 04, 2021
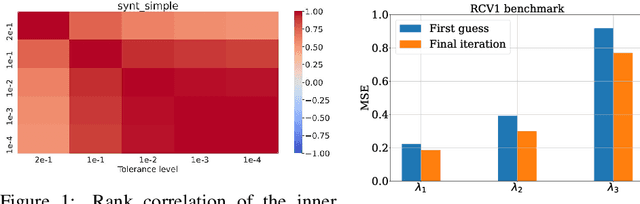

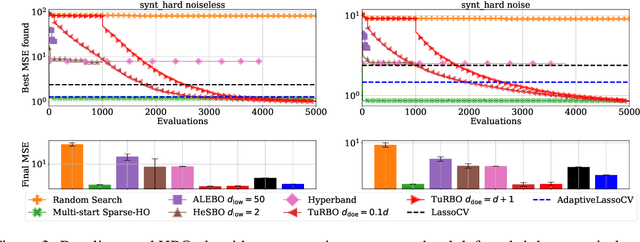
Even though Weighted Lasso regression has appealing statistical guarantees, it is typically avoided due to its complex search space described with thousands of hyperparameters. On the other hand, the latest progress with high-dimensional HPO methods for black-box functions demonstrates that high-dimensional applications can indeed be efficiently optimized. Despite this initial success, the high-dimensional HPO approaches are typically applied to synthetic problems with a moderate number of dimensions which limits its impact in scientific and engineering applications. To address this limitation, we propose LassoBench, a new benchmark suite tailored for an important open research topic in the Lasso community that is Weighted Lasso regression. LassoBench consists of benchmarks on both well-controlled synthetic setups (number of samples, SNR, ambient and effective dimensionalities, and multiple fidelities) and real-world datasets, which enable the use of many flavors of HPO algorithms to be improved and extended to the high-dimensional setting. We evaluate 5 state-of-the-art HPO methods and 3 baselines, and demonstrate that Bayesian optimization, in particular, can improve over the methods commonly used for sparse regression while highlighting limitations of these frameworks in very high-dimensions. Remarkably, Bayesian optimization improve the Lasso baselines on 60, 100, 300, and 1000 dimensional problems by 45.7%, 19.2%, 19.7% and 15.5%, respectively.