 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative learning of Pl@ntNet's Artificial Intelligence algorithm: how does it work and how can we improve it?
Jun 05, 2024Deep learning models for plant species identification rely on large annotated datasets. The PlantNet system enables global data collection by allowing users to upload and annotate plant observations, leading to noisy labels due to diverse user skills. Achieving consensus is crucial for training, but the vast scale of collected data makes traditional label aggregation strategies challenging. Existing methods either retain all observations, resulting in noisy training data or selectively keep those with sufficient votes, discarding valuable information. Additionally, as many species are rarely observed, user expertise can not be evaluated as an inter-user agreement: otherwise, botanical experts would have a lower weight in the AI training step than the average user. Our proposed label aggregation strategy aims to cooperatively train plant identification AI models. This strategy estimates user expertise as a trust score per user based on their ability to identify plant species from crowdsourced data. The trust score is recursively estimated from correctly identified species given the current estimated labels. This interpretable score exploits botanical experts' knowledge and the heterogeneity of users. Subsequently, our strategy removes unreliable observations but retains those with limited trusted annotations, unlike other approaches. We evaluate PlantNet's strategy on a released large subset of the PlantNet database focused on European flora, comprising over 6M observations and 800K users. We demonstrate that estimating users' skills based on the diversity of their expertise enhances labeling performance. Our findings emphasize the synergy of human annotation and data filtering in improving AI performance for a refined dataset. We explore incorporating AI-based votes alongside human input. This can further enhance human-AI interactions to detect unreliable observations.
Improve learning combining crowdsourced labels by weighting Areas Under the Margin
Sep 30, 2022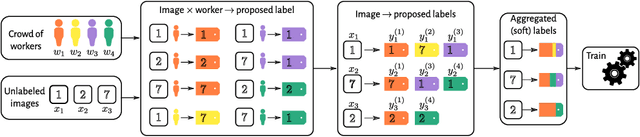


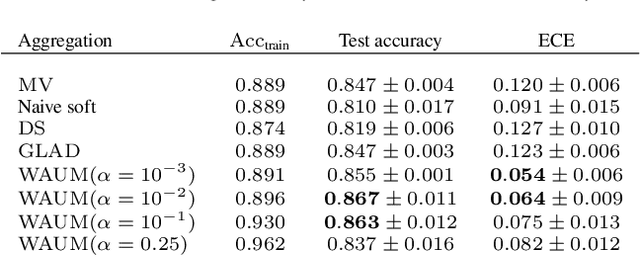
In supervised learning -- for instance in image classification -- modern massive datasets are commonly labeled by a crowd of workers. The obtained labels in this crowdsourcing setting are then aggregated for training. The aggregation step generally leverages a per worker trust score. Yet, such worker-centric approaches discard each task ambiguity. Some intrinsically ambiguous tasks might even fool expert workers, which could eventually be harmful for the learning step. In a standard supervised learning setting -- with one label per task and balanced classes -- the Area Under the Margin (AUM) statistic is tailored to identify mislabeled data. We adapt the AUM to identify ambiguous tasks in crowdsourced learning scenarios, introducing the Weighted AUM (WAUM). The WAUM is an average of AUMs weighted by worker and task dependent scores. We show that the WAUM can help discarding ambiguous tasks from the training set, leading to better generalization or calibration performance. We report improvements with respect to feature-blind aggregation strategies both for simulated settings and for the CIFAR-10H crowdsourced dataset.
Benchopt: Reproducible, efficient and collaborative optimization benchmarks
Jun 28, 2022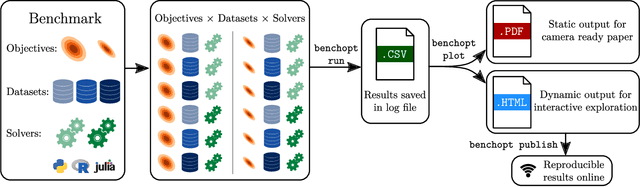
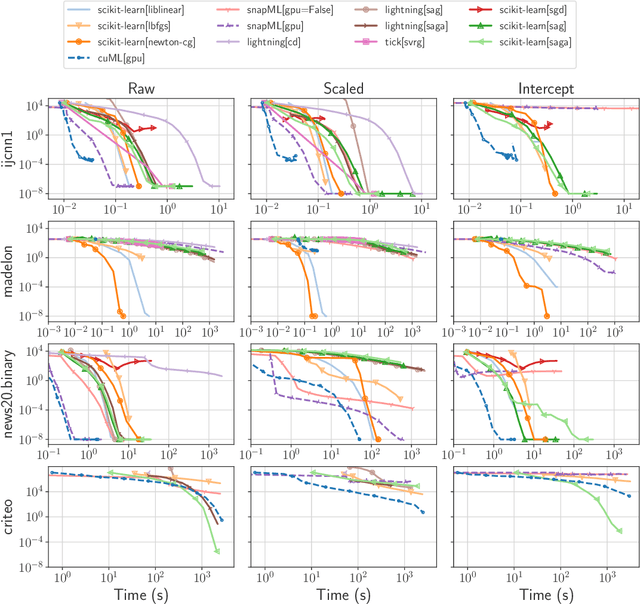
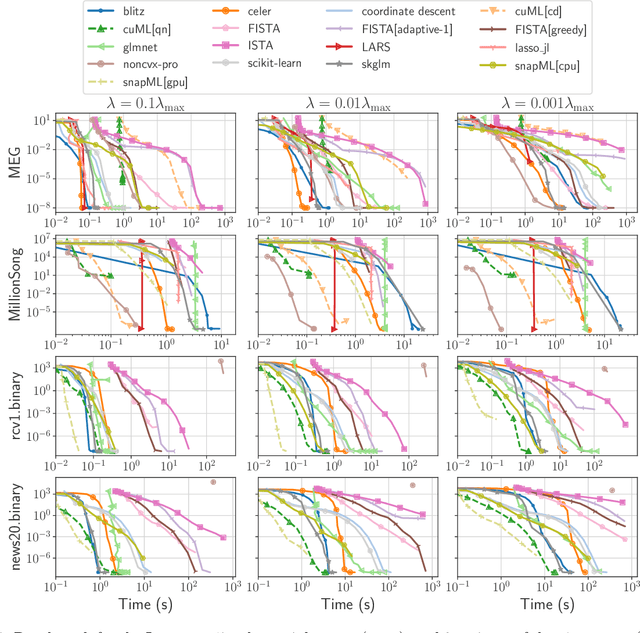
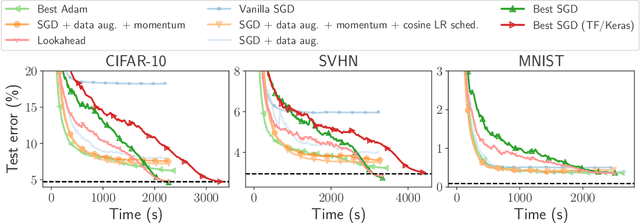
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: $\ell_2$-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.