 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance reduction techniques for stochastic proximal point algorithms
Aug 18, 2023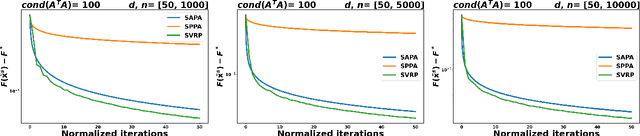
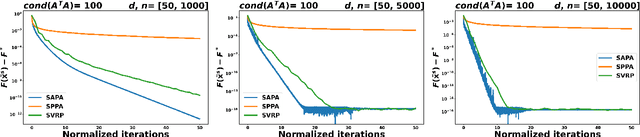
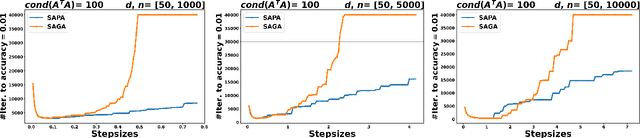
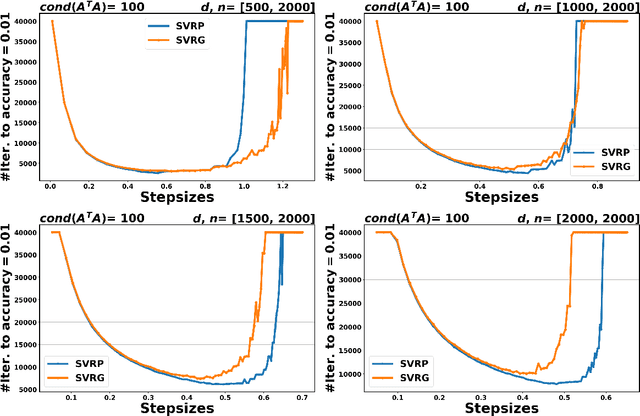
In the context of finite sums minimization, variance reduction techniques are widely used to improve the performance of state-of-the-art stochastic gradient methods. Their practical impact is clear, as well as their theoretical properties. Stochastic proximal point algorithms have been studied as an alternative to stochastic gradient algorithms since they are more stable with respect to the choice of the stepsize but a proper variance reduced version is missing. In this work, we propose the first study of variance reduction techniques for stochastic proximal point algorithms. We introduce a stochastic proximal version of SVRG, SAGA, and some of their variants for smooth and convex functions. We provide several convergence results for the iterates and the objective function values. In addition, under the Polyak-{\L}ojasiewicz (PL) condition, we obtain linear convergence rates for the iterates and the function values. Our numerical experiments demonstrate the advantages of the proximal variance reduction methods over their gradient counterparts, especially about the stability with respect to the choice of the step size.
Iterative regularization in classification via hinge loss diagonal descent
Dec 24, 2022Iterative regularization is a classic idea in regularization theory, that has recently become popular in machine learning. On the one hand, it allows to design efficient algorithms controlling at the same time numerical and statistical accuracy. On the other hand it allows to shed light on the learning curves observed while training neural networks. In this paper, we focus on iterative regularization in the context of classification. After contrasting this setting with that of regression and inverse problems, we develop an iterative regularization approach based on the use of the hinge loss function. More precisely we consider a diagonal approach for a family of algorithms for which we prove convergence as well as rates of convergence. Our approach compares favorably with other alternatives, as confirmed also in numerical simulations.